@
1. 案例一
1.1 数据读取
>>> df=pd.read_csv('D:\ 数据分析素材 \DataAnalyst.csv',encoding='gb2312')
>>> df前几列:

后几列:

上述呈现形式只能看个大概,需要对这些数据进一步进行粗略统计分析观察
1.2 预分析
>>> df.info()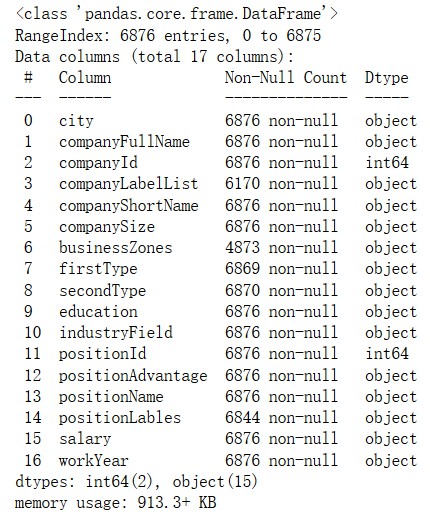
由此可以看到,每一列应该包含 6876 个数据,但是 index=3,6……等数据有空,其数据是不完整的。
表格数据中’positionId’这一列代表的招聘公司及职位的 ID,具有唯一性,有多少 ID,就有多少招聘岗位。其他为重复值。
>>> len(df.positionId.unique())
5031由此可以看到有效数据量为 5031 条。
1.3 数据清洗
删除重复值
>>> df1=df.drop_duplicates(['positionId']) // 按 positionID 列删除重复值
>>> df1.info()
数据规整
我们最为关心的数据之一就是薪水,它给出的是一个范围,我们要提取其中最大和最小值。
// 定义一个切词函数
def cut_word(word,method):
position=word.find('-') // 在 word 里找 '-',找到了返回其索引位置,找不到返回 -1
length=len(word)
if position != -1:
bottom_salary=word[:position-1] // 如 word 为 '6k-9k', 则返回 6
top_salary=word[position+1:length-1]
else:
bottom_salary=word[:word.upper().find('K')] // 有的 word 里是 '10K 以上 ',没有 '-',则只取数字部分
top_salary=bottom_salary
if method == 'bottom':
return bottom_salary
else:
return top_salary
>>> df1['bottom_salary']=df1.salary.apply(cut_word,method='bottom') // 注意这里传参方式
>>> df1['top_salary']=df1.salary.apply(cut_word,method='top')
>>> df1.head() 
这里的’bottom_salary’和’top_salary’都是字符类型数据,需要转换成整型数据。
>>> df1.bottom_salary = df1.bottom_salary.astype('int') // 数据类型转换
>>> df1.top_salary = df1.top_salary.astype('int')
>>> df1['avg_salary'] = df1.apply(lambda x:(x.bottom_salary+x.top_salary)/2,axis=1)
>>> df1.head()
最后只提取我们的需要的核心数据
>>> df2 = df1[['city','companyShortName','companySize','education',
'positionName','positionLables','workYear','avg_salary']] // 注意这里两个括号
>>> df2
>>> df2=df2.reset_index() // 可以将数据行索引变成 0-50301.4 数据分析
描述性统计
>>> df2.city.value_counts() // 统计城市职位需求
北京 2347
上海 979
深圳 527
杭州 406
广州 335
成都 135
南京 83
武汉 69
西安 38
苏州 37
厦门 30
长沙 25
天津 20
Name: city, dtype: int64>>> df2.describe() // 只有 avg_salary 数据列为整型数据,故只统计 avg_salary
avg_salary
count 5031.000000
mean 17.111409
std 8.996242
min 1.500000
25% 11.500000
50% 15.000000
75% 22.500000
max 75.0000001.5 可视化
Pandas 其实内置了简单的可视化工具
城市工资情况统计:
>>> df2.avg_salary.hist() // 直方图
>>> df2.boxplot(column='avg_salary',by='city',figsize=(9,7)) // 箱线图
上述箱线图横坐标城市本来为框,显示异常,可填入如下代码使之显示正常。
// 导入相关工具包
>>> import matplotlib.pyplot as plt
>>> %matplotlib inline // 为了可以直接在 jupyter notebook 中直接输出图表, 其实可以省略
>>> plt.style.use('ggplot')
>>> plt.rcParams['font.sans-serif'] = ['SimHei'] // 指定默认字体
>>> plt.rcParams['axes.unicode_minus'] = False // 解决保存图像是负号 '-' 显示为方块的问题职位关键词统计:
>>> df2.positionLables // 观察 positionLables 列的内容格式
>>> word = df2.positionLables.str[1:-1].replace(' ','') // 去掉中括号, 去掉空格
>>> df_word=word.dropna().str.split(',').apply(pd.value_counts) // 统计每个关键词在每行出现的次数
>>> df_word_counts = df_word.unstack().dropna().reset_index().groupby('level_0').count()
// 将 DataFrame 变成 Series,再按照 level_0 统计每个词出现的个数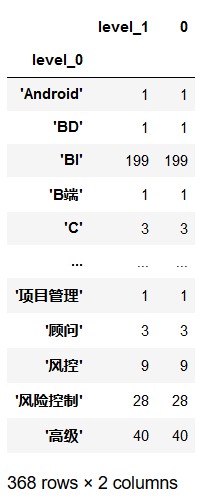
生成词云图:
>>> from wordcloud import WordCloud
>>> df_word_counts.index = df_word_counts.index.str.replace("'","")
>>> wordcloud = WordCloud(font_path='C:\Windows\Fonts\simsun.ttc',
width=900,height=400,
background_color='white')
>>> f,axs = plt.subplots(figsize=(15,15))
>>> wordcloud.fit_words(df_word_counts.level_1)
>>> axs = plt.imshow(wordcloud)
>>> plt.axis('off')
>>> plt.show()
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net