1、Scrapy-redis 介绍
Scrapy_redis : Redis-based components for Scrapy.
Github 地址:https://github.com/rmax/scrapy-redis
Scrapy_redis 在 scrapy 的基础上实现了更多,更强大的功能,具体体现在:reqeust 去重,爬虫持久化,和轻松实现分布式
那么,scrapy_redis 是如何帮助我们抓取数据的呢?
1.1 单机爬虫
默认情况下 Scrapy 是不支持分布式的,需要使用基于 Redis 的 Scrapy-Redis 组件才能实现分布式。
正常的 Scrapy 单机爬虫:
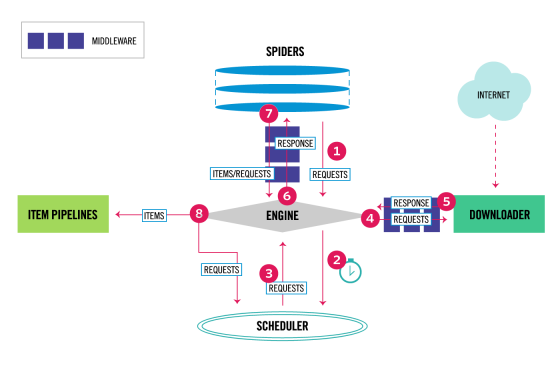
Scrapy 并不会共享调度队列,也就是说 Scrapy 是不支持分布式的。为了支持分布式,我们需要让 Scrapy 支持共享调度队列,也就是改造成共享调度和去重的功能。
1.2 分布式爬虫
分布式:分而治之
将一个爬虫代码,分别部署在多台电脑上,共同完成整个爬虫任务。
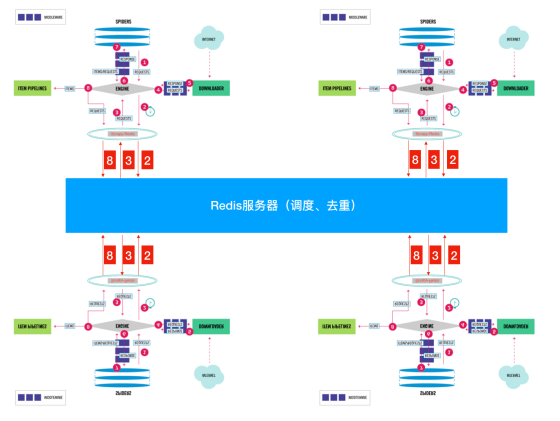
使用 Redis 服务器来集中处理所有的请求,主要负责请求的去重和调度。通过这种方式,所有电脑端的爬虫共享了一个爬取队列,并且每个电脑端每次得到的请求都是其他爬虫未曾访问的。从而提高了爬虫效率。
得到一个请求之后,检查一下这个 Request 是否在 Redis 去重,如果在就证明其它的 spider 采集过啦!如果不在就添加进调度队列,等待别人获取。
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis 是为了更方便地实现 Scrapy 分布式爬取,而提供了一些以 redis 为基础的组件。
安装如下:pip install scrapy-redis
Scrapy-redis 提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
- Scheduler(调度器)
- Duplication Filter(去重)
- Item Pipeline(管道)
- Base Spider(爬虫类)
(1)Scheduler(调度器)
Scrapy 改造了 Python 本来的 collection.deque(双向队列)形成了自己的 Scrapy queue,但是 Scrapy 多个 spider 不能共享待爬取队列 Scrapy queue, 即 Scrapy 本身不支持爬虫分布式,scrapy-redis 的解决是把这个 Scrapy queue 换成 redis 数据库(也是指 redis 队列),便能让多个 spider 去同一个数据库里读取,这样实现共享爬取队列。
Redis 支持多种数据结构,这些数据结构可以很方便的实现这样的需求:
列表有 lpush(),lpop(),rpush(),rpop(),这些方法可以实现先进先出,或者先进后出式的爬取队列。
集合元素是无序且不重复的,可以很方便的实现随机排序且不重复的爬取队列。
Scrapy 的 Request 带有优先级控制,Redis 中的集合也是带有分数表示的,可以用这个功能实现带有优先级调度的爬取队列。
Scrapy 把待爬队列按照优先级建立了一个字典结构,比如:
{
优先级 0 : 队列 0
优先级 1 : 队列 1
优先级 2 : 队列 2
}然后根据 request 中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。由于 Scrapy 原来的 Scheduler 只能处理 Scrapy 自身的队列,不能处理 Redis 中的队列,所以原来的 Scheduler 已经无法使用,应该使用 Scrapy-Redis 的 Scheduler 组件。
(2)Duplication Filter(去重)
Scrapy 自带去重模块,该模块使用的是 Python 中的集合类型。该集合会记录每个请求的指纹,指纹也就是 Request 的散列值。指纹的计算采用的是 hashlib 的 sha1()方法。计算的字段包含了,请求的 Method,URL,Body,Header 这几个内容,这些字符串里面只要里面有一点不同,那么计算出来的指纹就是不一样的。也就是说,计算的结果是加密后的字符串,这就是请求指纹。通过加密后的字符串,使得每个请求都是唯一的,也就是指纹是惟一的。并且指纹是一个字符串,在判断字符串的时候,要比判断整个请求对象容易。所以采用了指纹作为判断去重的依据。
Scrapy-Redis 要想实现分布式爬虫的去重功能,也是需要更新指纹集合的,但是不能每个爬虫维护自己的单独的指纹集合。利用 Redis 集合的数据结构类型,可以轻松实现分布式爬虫的指纹判重。也就是说:每台主机得到 Request 的指纹去和 Redis 中的集合进行对比,如果指纹存在,说明是重复的,也就不会再去发送请求,如果不曾存在于 Redis 中的指纹集合,就会发送请求,并且将该指纹加入 Redis 的集合中。这样就实现了分布式爬虫的指纹集合的共享。
(3)Item Pipeline
引擎将 (Spider 返回的) 爬取到的 Item 给 Item Pipeline,scrapy-redis 的 Item Pipeline 将爬取到的 Item 存⼊redis 的 items queue。修改过 Item Pipeline 可以很方便的根据 key 从 items queue 提取 item,从⽽实现 items processes 集群。
(4)Base Spider
不再使用 scrapy 原有的 Spider 类,重写的 RedisSpider 继承了 Spider 和 RedisMixin 这两个类,RedisMixin 是用来从 redis 读取 url 的类。当我们生成一个 Spider 继承 RedisSpider 时,调用 setup_redis 函数,这个函数会去连接 redis 数据库,然后会设置 signals(信号):
当 spider 空闲时候的 signal,会调用 spider_idle 函数,这个函数调用 schedule_next_request 函数,保证 spider 是一直活着的状态,并且抛出 DontCloseSpider 异常。
当抓到一个 item 时的 signal,会调用 item_scraped 函数,这个函数会调用 schedule_next_request 函数,获取下一个 request。
2、Scrapy_redis 使用
1、clone github scrapy-redis 源码文件
git clone https://github.com/rolando/scrapy-redis.git
2、研究项目自带的三个 demo
mv scrapy-redis/example-project ~/scrapyredis-project
2.1 Scrapy_redis 之 domz
首先看看 Spider 文件:
// filename(spider):domz.py
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
allowed_domains = ['dmoztools.net']
start_urls = ['http://dmoztools.net/']
rules = [
# 定义一个 url 提取规则,满足条件的 url 交给 callback 函数处理
Rule(LinkExtractor(restrict_css=('.top-cat', '.sub-cat', '.cat-item')
), callback='parse_directory', follow=True),
]
def parse_directory(self, response):
for div in response.css('.title-and-desc'):
# 将结果返回给引擎
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}domz.py 这个部分与我们自己写的 crawlspider 没有任何区别。
下一步再看对应的 Settings.py 文件,里面新增内容如下
//filename:settings.py
# Scrapy settings for example project
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/topics/settings.html
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
// 上两个是自动生成的,不用设置。意思是爬虫位于 example 项目的 spiders 文件夹下
USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
// 根据需要看是否设置
// 重点 1 指定去重方法
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
// 重点 2 指定调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
// 重点 3 指定队列中的内容是否持久保存,为 False 的时候在关闭爬虫时清空 redis 数据
SCHEDULER_PERSIST = True
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
// 利用 scrapy_redis 里的 pipelines 实现数据保存
LOG_LEVEL = 'DEBUG'
# Introduce an artifical delay to make use of parallelism. to speed up the crawl.
DOWNLOAD_DELAY = 1
// 默认为 3s,这里设置为 1s
// 重点 4 配置数据库连接
REDIS_URL = "redis://127.0.0.1:6379"
'''
redis 的地址可以写成如下形式
REDIS_HOST = "127.0.0.1" // 服务器 ip, 若为本地,则为 'localhost'
REDIS_PORT = 6379 // 指定端口
'''我们执行 domz.py 的爬虫,会发现 redis 数据库中多了一下三个键。我们可以尝试在 setting 中关闭 redispipeline,
观察 redis 中三个键的存储数据量的变化
变化结果:
dmoz:requests 有变化(变多或者变少或者不变)
dmoz:dupefilter 变多
dmoz:items 不变
变化结果分析:
redispipeline 中仅仅实现了 item 数据存储到 redis 的过程,我们可以新建一个 pipeline(或者修改默认的 ExamplePipeline),让数据存储到任意地方
那么问题来了:以上的这些功能 scrapy_redis 都是如何实现的呢?
2.2 Scrapy_redis 之 RedisPipeline
class RedisPipeline(object):
# 使用 process_item 的方法,实现数据保存
def process_item(self, item, spider):
return deferToThread(self._process_item, item, spider)
def _process_item(self, item, spider):
key = self.item_key(item, spider)
data = self.serialize(item)
# 向 dmoz:item 中添加 item
self.server.rpush(key, data)
return item
def item_key(self, item, spider):
return self.key % {'spider': spider.name}2.3 Scrapy_redis 之 RFPDupeFilter
# filename:scrapy_redis/dupeFilter.py
import logging
import time
from scrapy.dupefilters import BaseDupeFilter
from scrapy.utils.request import request_fingerprint
class RFPDupeFilter(BaseDupeFilter):
def request_seen(self, request):
""" 判断 request 对象是否已经存在 """
fp = self.request_fingerprint(request)
# 添加到 dupefilter 中,返回 0 表示数据已经存在
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
return request_fingerprint(request)# filename:scrapy/utils/request.py
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
# sha1 加密
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
# 添加请求头,默认不加请求头(因为 headers 的 cookies 中含有 session_id, 这在不同的网站中是随机的,会给 sha1 带来误差)
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
# 返回加密之后的 16 进制
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
2.4 scrapy_redis 去重方法
- 使用 sha1 加密 request 得到指纹
- 把指纹存在 redis 的集合中
- 下一次新来一个 request,同样的方式生成指纹,判断指纹是否存在 reids 的集合中
生成指纹
fp = hashlib.sha1()
fp.update(to_bytes(request.method)) #请求方法
fp.update(to_bytes(canonicalize_url(request.url))) #url
fp.update(request.body or b'') #请求体
return fp.hexdigest()2.5 Scrapy_redis 之 Scheduler
# filename:scrapy_redis/dupeFilter.py
class Scheduler(object):
def close(self, reason):
# 如果在 settings 中设置不持久,那么在退出时候就会清空
if not self.persist:
self.flush()
def flush(self):
# 存放 dupefilter 的 redis
self.df.clear()
# 存放 request 的 redis
self.queue.clear()
def enqueue_request(self, request):
# 不能加入带爬取队列的条件,当 url 需要经过 allow_domain 过滤并且 request 不存在 dp 的时候
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
self.queue.push(request)
return True
request 对象什么时候入队
- dont_filter = True , 构造请求的时候,把 dont_filter 置为 True,该 url 会被反复抓取(url 地址对应的内容会更新的情况)
- 一个全新的 url 地址被抓到的时候,构造 request 请求
- url 地址在 start_urls 中的时候,会入队,不管之前是否请求过
- 构造 start_url 地址的请求时候,dont_filter = True
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
# dont_filter=False Ture True request 指纹已经存在 #不会入队
# dont_filter=False Ture False request 指纹已经存在 全新的 url #会入队
# dont_filter=Ture False #会入队
self.df.log(request, self.spider)
return False
self.queue.push(request) #入队
return True通过以上知识点的学习,我们会发现:
domz 相比于之前的 spider 多了持久化和 request 去重的功能
在之后的爬虫中,我们可以模仿 domz 的用法,使用 scrapy_redis 实现相同的功能
注意:setting 中的配置都是可以自己设定的,意味着我们的可以重写去重和调度器的方法,包括是否要把数据存储到 redis(pipeline)
配置文件:
# 修改调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 修改去重工具
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 开启数据持久化
SCHEDULER_PERSIST = True
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
# 验证数据库密码
REDIS_PARAMS = {
'password': '123456',
}3、分布式爬取
了解了 scrapy-redis 的原理后,我们学习使用 scrapy + scrapy-redis 进行分布式爬取。
3.1 搭建环境
首先搭建 scrapy-redis 分布式爬虫环境,当前我们有 3 台 Linux 主机。
云服务器(A):116.29.35.201 (Redis Server)
云服务器(B):123.59.45.155
本机(C):1.13.41.127
在 3 台主机上安装 scrapy 和 scrapy-redis:
$ pip install scrapy
$ pip install scrapy-redis选择其中一台云服务器搭建供所有爬虫使用的 Redis 数据库,步骤如下:
[步骤 01] 在云服务器上安装 redis-server。
[步骤 02] 在 Redis 配置文件中修改服务器的绑定地址(确保数据库可被所有爬虫访问)。
[步骤 03] 启动/重启 Redis 服务器。
登录云服务器(A),在 bash 中完成上述步骤:
116.29.35.201$ sudo apt-get install redis-server
116.29.35.201$ sudo vi /etc/redis/redis.conf
...
# bind 127.0.0.1
bind 0.0.0.0
...
116.29.35.201$ sudo service redis-server restart最后,在 3 台主机上测试能否访问云服务器(A)上的 Redis 数据库:
$ redis-cli -a 123456 -h 116.29.35.201 ping
PONG-a 后面接 redis 的密码(若有),-h 后面接目标 ip 地址。
到此,Scrapy 分布式爬虫环境搭建完毕。
3.2 项目实战
本章的核心知识点是分布式爬取,因此本项目不再对分析页面、编写 Spider 等大家熟知的技术进行展示。我们可以任意挑选一个在之前章节中做过的项目,将其改为分布式爬取的版本,这里以第 8 章的 toscrape_book 项目(爬取 books.toscrape.com 中的书籍信息)为例进行讲解。
复制 toscrape_book 项目,得到新项目 toscrape_book_distributed:
$ cp -r toscrape_book toscrape_book_distributed
$ cd toscrape_book_distributed在配置文件 settings.py 中添加 scrapy-redis 的相关配置:
# 必选项
# ==================================================================
# 指定爬虫所使用的 Redis 数据库(在云服务器 116.29.35.201 上)
REDIS_URL = 'redis://116.29.35.201:6379'
# 使用 scrapy_redis 的调度器替代 Scrapy 原版调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 使用 scrapy_redis 的 RFPDupeFilter 作为去重过滤器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 启用 scrapy_redis 的 RedisPipeline 将爬取到的数据汇总到 Redis 数据库
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300,
}
# 可选项
# ==================================================================
#爬虫停止后,保留/清理 Redis 中的请求队列以及去重集合
# True:保留,False:清理,默认为 False
SCHEDULER_PERSIST = True将单机版本的 Spider 改为分布式版本的 Spider,只需做如下简单改动:
from scrapy_redis.spiders import RedisSpider
# 1. 更改基类
# class BooksSpider(spider.Spider):
class BooksSpider(RedisSpider):
...
# 2. 注释 start_urls
#start_urls = ['http://books.toscrape.com/']
...上述改动针对“如何为多个爬虫设置起始爬取点”这个问题,解释如下:
● 在分布式爬取时,所有主机上的代码是相同的,如果使用之前单机版本的 Spider 代码,那么每一台主机上的 Spider 都通过 start_urls 属性定义了起始爬取点,在构造起始爬取点的 Request 对象时,dont_filter 参数设置为了 True,即忽略去重过滤器的过滤。因此多个(数量等于爬虫数量)重复请求将强行进入 Redis 中的请求队列,这可能导致爬取到重复数据。
● 为了解决上述问题,scrapy-redis 提供了一个新的 Spider 基类 RedisSpider,RedisSpider 重写了 start_requests 方法,它尝试从 Redis 数据库的某个特定列表中获取起始爬取点,并构造 Request 对象(dont_filter=False),该列表的键可通过配置文件设置(REDIS_START_URLS_KEY),默认为
到此,分布式版本的项目代码已经完成了,分发到各个主机:
$ scp -r toscrape_book_distributed liushuo@116.29.35.201:~/scrapy_book
$ scp -r toscrape_book_distributed liushuo@123.59.45.155:~/scrapy_book分别在 3 台主机使用相同命令运行爬虫:
$ scrapy crawl books
2017-05-14 17:56:42 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: toscrape_book) 2017-05-14 17:56:42 [scrapy.utils.log] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy_redis.dupefilter.RFPDupeFilter', 'FEED_EXPORT_FIELDS': ['upc', 'name', 'price', 'stock', 'review_rating', 'review_num'], 'SCHEDULER': 'scrapy_redis.scheduler.Scheduler', 'BOT_NAME': 'toscrape_book', 'ROBOTSTXT_OBEY': True, 'NEWSPIDER_MODULE': 'toscrape_book.spiders', 'SPIDER_MODULES': ['toscrape_book.spiders']} 2017-05-14 17:56:42 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.logstats.LogStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.corestats.CoreStats'] 2017-05-14 17:56:42 [books] INFO: Reading start URLs from redis key 'books:start_urls' (batch size: 16, encoding: utf-8 2017-05-14 17:56:42 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 2017-05-14 17:56:42 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 2017-05-14 17:56:42 [scrapy.middleware] INFO: Enabled item pipelines: ['scrapy_redis.pipelines.RedisPipeline'] 2017-05-14 17:56:42 [scrapy.core.engine] INFO: Spider opened 2017-05-14 17:56:42 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2017-05-14 17:56:42 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 ... 阻塞在此处...运行后,由于 Redis 中的起始爬取点列表和请求队列都是空的,3 个爬虫都进入了暂停等待的状态,因此在任意主机上使用 Redis 客户端设置起始爬取点:
$ redis-cli -h 116.29.35.201 116.29.35.201:6379> lpush books:start_urls 'http://books.toscrape.com/' (integer) 1随后,其中一个爬虫(本实验中是云服务器 A)从起始爬取点列表中获取到了 url,在其 log 中观察到如下信息:
2017-05-14 17:57:18 [books] DEBUG: Read 1 requests from 'books:start_urls'该爬虫用起始爬取点 url 构造的 Request 对象最终被添加到 Redis 中的请求队列之后。各个爬虫相继开始工作了,可在各爬虫的 log 中观察到类似于如下的信息:
2017-05-14 18:00:42 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/arena_587/index.html> {'name': 'Arena', 'price': '£21.36', 'review_num': '0', 'review_rating': 'Four', 'stock': '11', 'upc': '2c34f9432069b52b'} 2017-05-14 18:00:42 [scrapy.core.engine] DEBUG: Crawled (200) (referer: http://books.toscrape.com/catalogue/page-21.html) 2017-05-14 18:00:42 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/adultery_586/index.html> {'name': 'Adultery', 'price': '£20.88', 'review_num': '0', 'review_rating': 'Five', 'stock': '11', 'upc': 'bb967277222e689c'} 2017-05-14 18:00:42 [scrapy.core.engine] DEBUG: Crawled (200) (referer: http://books.toscrape.com/catalogue/page-21.html) 2017-05-14 18:00:42 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/a-mothers-reckoning-living-in-the-aftermath-of-tragedy_585/index.htm l> {'name': "A Mother's Reckoning: Living in the Aftermath of Tragedy", 'price': '£19.53', 'review_num': '0', 'review_rating': 'Three', 'stock': '11', 'upc': '2b69dec0193511d9'} 2017-05-14 18:00:43 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/112263_583/index.html> {'name': '11/22/63', 'price': '£48.48', 'review_num': '0', 'review_rating': 'Three', 'stock': '11', 'upc': 'a9d7b75461084a26'} 2017-05-14 18:00:43 [scrapy.core.engine] DEBUG: Crawled (200) (referer: http://books.toscrape.com/catalogue/page-21.html) 2017-05-14 18:00:43 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/10-happier-how-i-tamed-the-voice-in-my-head-reduced-stress-without- losing-my-edge-and-found-self-help-that-actually-works_582/index.html> {'name': '10% Happier: How I Tamed the Voice in My Head, Reduced Stress ' 'Without Losing My Edge, and Found Self-Help That Actually Works', 'price': '£24.57', 'review_num': '0', 'review_rating': 'Two', 'stock': '10', 'upc': '34669b2e9d407d3a'}等待全部爬取完成后,在 Redis 中查看爬取到的数据:
116.29.35.201:6379> keys * 1) "books:items" 2) "books:dupefilter" 116.29.35.201:6379> llen books:items (integer) 1000 116.29.35.201:6379> LRANGE books:items 0 4 1) "{\"stock\": \"22\", \"review_num\": \"0\", \"upc\": \"a897fe39b1053632\", \"name\": \"A Light in the Attic\", \"review_rating\": \"Three\", \"price\": \"\\u00a351.77\"}" 2) "{\"stock\": \"20\", \"review_num\": \"0\", \"upc\": \"e00eb4fd7b871a48\", \"name\": \"Sharp Objects\", \"review_rating\": \"Four\", \"price\": \"\\u00a347.82\"}" 3) "{\"stock\": \"20\", \"review_num\": \"0\", \"upc\": \"90fa61229261140a\", \"name\": \"Tipping the Velvet\", \"review_rating\": \"One\", \"price\": \"\\u00a353.74\"}" 4) "{\"stock\": \"20\", \"review_num\": \"0\", \"upc\": \"6957f44c3847a760\", \"name\": \"Soumission\", \"review_rating\": \"One\", \"price\": \"\\u00a350.10\"}" 5) "{\"stock\": \"19\", \"review_num\": \"0\", \"upc\": \"2597b5a345f45e1b\", \"name\": \"The Dirty Little Secrets of Getting Your Dream Job\", \"review_rating\": \"Four\", \"price\": \"\\u00a333.34\"}" 116.29.35.201:6379> LRANGE books:items -5 -1 1) "{\"name\": \"Shameless\", \"price\": \"\\u00a358.35\", \"review_rating\": \"Three\", \"upc\": \"c068c013d6921fea\", \"review_num\": \"0\", \"stock\": \"1\"}" 2) "{\"stock\": \"1\", \"review_num\": \"0\", \"upc\": \"19fec36a1dfb4c16\", \"name\": \"A Spy's Devotion (The Regency Spies of London ##1)\", \"review_rating\": \"Five\", \"price\": \"\\u00a316.97\"}" 3) "{\"stock\": \"1\", \"review_num\": \"0\", \"upc\": \"f684a82adc49f011\", \"name\": \"1st to Die (Women's Murder Club ##1)\", \"review_rating\": \"One\", \"price\": \"\\u00a353.98\"}" 4) "{\"stock\": \"1\", \"review_num\": \"0\", \"upc\": \"228ba5e7577e1d49\", \"name\": \"1,000 Places to See Before You Die\", \"review_rating\": \"Five\", \"price\": \"\\u00a326.08\"}" 5) "{\"name\": \"Girl in the Blue Coat\", \"price\": \"\\u00a346.83\", \"review_rating\": \"Two\", \"upc\": \"41fc5dce044f16f5\", \"review_num\": \"0\", \"stock\": \"3\"}"如上所示,我们成功地爬取到了 1000 项数据(由各爬虫最后的 log 信息得知,爬虫 A:514 项,爬虫 B:123 项,爬虫 C:363 项)。每一项数据以 json 形式存储在 Redis 的列表中,需要使用这些数据时,可以编写 Python 程序将它们从 Redis 中读出,代码框架如下:
import redis
import json
ITEM_KEY = 'books:items'
def process_item(item):
# 添加处理数据的代码
'''...'''
def main():
r = redis.StrictRedis(host='116.29.35.201', port=6379)
for _ in range(r.llen(ITEM_KEY)):
data = r.lpop(ITEM_KEY)
item = json.loads(data.decode('utf8'))
process_item(item)
if __name__ == '__main__':
main()到此,我们完成了分布式爬取的项目。
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net