1、Scrapy 简介
官方文档:https://doc.scrapy.org/en/latest/topics/commands.html#std:command-startproject
Scrapy 是一个使用 Python 语言(基于 Twisted 框架)编写的开源网络爬虫框架,目前由 Scrapinghub Ltd 维护。Scrapy 简单易用、灵活易拓展、开发社区活跃,并且是跨平台的。在 Linux、 MaxOS 以及 Windows 平台都可以使用。
一个网络爬虫程序的基本执行流程可以总结三个过程:请求数据 , 解析数据 , 保存数据
往往一个爬虫项目会包含多个这样的过程(请求—解析—保存),为了避免因制造轮子而消耗大量时间,一些爬虫框架会将这些工作单独分开过来,将重复的过程进行封装, 使得程序员能够我们能够专注于爬虫数据获取逻辑,提高工作效率与代码质量。
Scrapy 已经包含了协程部分,不再需要多进程多线程。
1.1 架构原理
以下是爬虫框架 Scrapy 的工作流程:
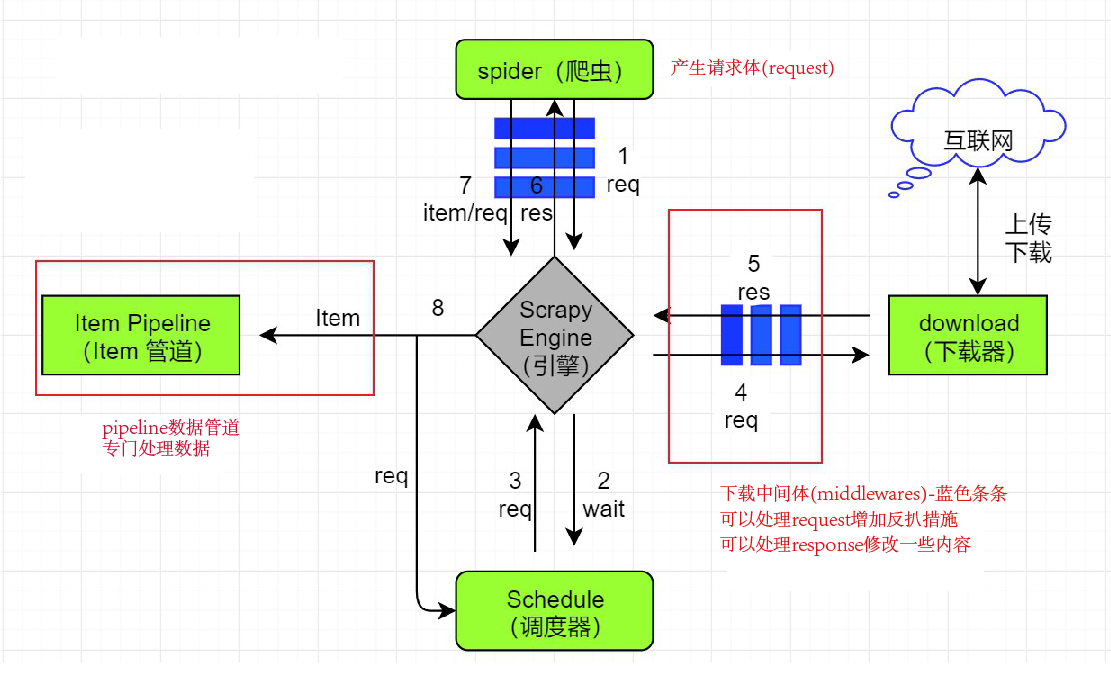
- scrapy 引擎向 spider 获取起始 Request 集合, 也就是 spider 中定义的
start_urls。如果 spider 重写了start_requests()方法,那么这个方法返回的 Request 集合就是起始 Request。 - scrapy 引擎将拿到的 Request 发给调度中心开始调度。
- scrapy 引擎向调度中心请求获取下一个要爬取的 Request。
- scrapy 引擎拿到 Request 后,然后将 Request 发给下载器。这个过程经过一系列在
settings.py中配置的下载中间件,所有在settings.py中配置的下载中间件会依次对 Request 进行处理。对应DownloaderMiddleware #process_request()方法 - 下载器根据 Request 获取响应的内容,比如 Request 的 url 是
http://www.baidu.com,下载器就会获取对应的网页内容下来并封装成 Response 对象。 - 下载器将 Response 发送给 scrapy 引擎。这个过程也会经过一系列在
settings.py中配置的下载中间件,这些下载中间件会依次对 Response 进行处理。对应DownloaderMiddleware#process_response()方法 - scrapy 引擎拿到 Response 后将 Response 发给 spider, 交给对应的 spider 函数处理。这里默认方法是
parse(), 这个回调方法构造 Request 的时候指定。引擎发送 Response 的过程会经过一系列在settings.py中配置的 spider 中间件,这些 spider 中间件会依次对 Response 进行一些处理。对应SpiderMiddleware#process_spider_input() - spider 处理完 Response 后会返回一个 result,这个 result 是一个
包含 Request 或 Item 对象的可迭代对象 (iterable)。然后将 result 发给 scrapy 引擎,这个过程也会经过一系列在settings.py中配置的 spider 中间件,这些 spider 中间件会依次对这个 result 进行一些处理。对应SpiderMiddleware#process_spider_output() - scrapy 引擎拿到这个 result 后,会将其中的 Item 发送给
Item Pipeline处理, 这些 item 就会被一系列我们在settings.py中配置的pipeline处理。同时,scrapy 也会将 result 中的 Request 发给调度中间准备调度。 - 继续重复第 2 步的步骤,直到所有的 Request 全部处理完后程序退出。
2、开始项目
2.1 创建一个爬虫项目
查看 scrapy 命令:
$ scrapy
// 输出如下
Scrapy 1.8.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[more] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
创建一个项目(名为 qutos):
cd (目标文件夹)
scrapy startproject qutos进入项目文件夹:
cd qutos生成一个爬虫(quto):
scrapy genspider quto toscrape.com // 这里的 toscrape.com 是爬虫的目标域名 此时项目目录下会创建如下文件:

spider文件夹:
quto.py:爬虫,用于编写爬虫程序
__init__.py :
items.py:用于保存抓取的数据
middlewares.py:额外功能拓展区
pipelines.py:核心处理器
settings.py:爬虫的设置文件,供用户进行设置定义
scrapy.cfg:默认配置文件
2.1 quto.py 爬虫

写好 quto.py 爬虫文件代码,就可以爬取数据了:
启动爬虫之前,注意在 settings.py 里设置ROBOTSTXT_OBEY = False 不遵守爬虫协议
scrapy crawl quto // 启动爬虫 保存为 json 数据到本地:
scrapy crawl quto -o qutodata.json //一个例子 quto.py
import scrapy
import urllib
class QutoSpider(scrapy.Spider):
name = 'quto' #爬虫名字
allowed_domains = ['toscrape.com'] #允许爬取的范围
start_urls = ['http://quotes.toscrape.com/'] #爬虫的起点,发送请求
def parse(self, response): #网址响应的内容 response 会传到这里面
divs=response.css('.quote')
for div in divs:
text=div.css('.text::text').get()
author=div.css('.author::text').get()
tag=div.css('.tag::text').getall()
yield dict(text=text,author=author,tag=tag) #返回的内容必须是字典 dict 或 item(scrapy 特有的)
next_page=response.css('.next a::attr(href)').get() #获取下一页网址
next_url=urllib.parse.urljoin(response.url,next_page) #只能通过这种方式
print(next_url)
yield scrapy.Request(next_url,callback=self.parse)2.1.1 多个起始 url
简单写法:
start_urls=[f'http://quotes.toscrape.com/{page}' for page in range(1,11)]重写:
使用 start_requests() 重写 start_urls,要使用Request() 方法自己发送请求:
def start_requests(self):
yield scrapy.Request('http://quotes.toscrape.com/',callback=self.parse)Request()对象用来描述一个 HTTP 请求,下面是其构造器方法的参数列表:
Request(url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None, cb_kwargs=None)- url(字符串)–此请求的 URL
- callback(callable)–将以请求的响应(一旦下载)作为第一个参数调用的函数。有关更多信息,请参见下面的将其他数据传递给回调函数。如果“请求”未指定回调,parse() 则将使用“Spider” 方法。请注意,如果在处理过程中引发异常,则会调用 errback。
- method(字符串)–此请求的 HTTP 方法。默认为
'GET'。 - meta(dict)– Request.meta 属性的初始值。如果给出,则在此参数中传递的字典将被浅表复制。
- headers(dict)–请求头。dict 值可以是字符串(对于单值标头)或列表(对于多值标头)。如果
None作为值传递,则将根本不发送 HTTP 标头。
其中里面的 meta 参数也比较重要:
主要作用是用来传递数据的
meta 是通过 Request 产生时传进去,通过 Response 对象中取出来。
2.3 item 类
spider 解析出数据之后,其结果是通过yield 一个 dict,但dict 缺少数据结构,没法保证每一处返回都能返回相同的字段。因此 scrapy 提供了 Item 类,用来声明爬取数据的数据结构,该类提供了 dict-like 的接口,因此可以很方便的使用。
items.py 用法如下:
import scrapy
class QutosItem(scrapy.Item):
name = scrapy.Field()
tags=scrapy.Field()item 是自定义的数据结构,涉及到 2 个类:
scrapy.Item:基类;
scrapy.Field:用来描述自定义数据包含哪些字段信息,也仅此而已,并没有实际的作用。
2.4 ItemPipeline
当 item 从 spider 爬取获得之后,会被送到 ItemPipeline,在 scrapy,ItemPipeline 是处理数据的组件,它们接收 Item 参数并再其之上进行处理。
ItemPipeline 的典型用法:
- 清理脏数据;
- 验证数据的有效性;
- 去重
- 保存 item 到 db,即持久化存储
2.4.1 数据处理
Scrapy 提供了 pipeline 模块来执行保存数据的操作。在创建的 Scrapy 项目中自动创建了一个 pipelines.py 文件,同时创建了一个默认的 Pipeline 类:
class TutorialPipeline(object): // 类名是可以修改的,也可以根据需要增加
def process_item(self, item, spider):
return item在这个类中,有个方法叫 process_item()方法,每个 定义的 Pipeline 类 都需要调用该方法。得到 item 类数据后,就是通过 process_item()里传入的 item 参数作为一个入口,进入 Class 类中执行一些操作。
process_item() 方法必须 返回 一个字典数据。默认有两个参数。如果把 return item 删除了那就不会再调用其他 Pipeline 方法了。
参数:
item (Item 对象 dict)
spider (Spider 对象)
数据保存到 txt:
import json
class TutorialPipeline(object):
def process_item(self, item, spider):
## 保存数据
with open('data.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(dict(item), ensure_ascii=False))
f.write('\n')
return item*下面是一个完整的 item pipeline 模板 *
import something
class SomethingPipeline(object):
def __init__(self):
## 可选实现,做参数初始化等
## doing something
pass
def process_item(self, item, spider):
## item (Item 对象) – 被爬取的 item
## spider (Spider 对象) – 爬取该 item 的 spider
## 这个方法必须实现,每个 item pipeline 组件都需要调用该方法,
## 这个方法必须返回一个 Item 对象,被丢弃的 item 将不会被之后的 pipeline 组件所处理。
return item
def open_spider(self, spider):
## spider (Spider 对象) – 被开启的 spider
## 可选实现,当 spider 被开启时,这个方法被调用。
pass
def close_spider(self, spider):
## spider (Spider 对象) – 被关闭的 spider
## 可选实现,当 spider 被关闭时,这个方法才被调用
pass在 Spider 整个爬取过程中,数据库的连接和关闭操作只需要进行一次,应在开始处理数据之前连接数据库,并在处理完所有数据之后关闭数据库。因此实现以下两个方法(在 Spider 打开和关闭时被调用):
open_spider(spider)
close_spider(spider)
保存
// 保存为 json
import json
class ItcastJsonPipeline(object):
def __init__(self):
self.file = open('item.json', 'wb') // 提前创建并打开文件
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
// 保存为 excel 文件
from openpyxl import Workbook
class ToexcelPipeline(object):
def __init__(self):
self.wb=Workbook()
self.ws=self.wb.active
self.ws.append([' 名字 ',' 性别 ',' 身高 ',' 生日 ',' 省份 ',' 城市 ',' 文化水平 ',' 年薪 '])
def process_item(self, item, spider):
infos=[item['username'],item['gender'],item['height'],item['birthdayyear'],
item['province'] ,item['city'] ,item['education'],item['salary']]
self.ws.append(infos)
self.wb.save('wzly-infos.xlsx')
return item去重
当数据重复时,我们就可以不保存:
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item2.4.2 启用 ItemPipeline
上面配置的 ItemPipeline 类需要在 settings.py 中进行启用才能生效。
启用 ItemPipeline
在 settings.py 中添加以下内容:
ITEM_PIPELINES = {
'newproject.pipelines.ItemPipeline': 300,
}其中,ITEM_PIPELINES是一个字典文件,【键】为在pipelines.py 文件中配置的 ItemPipeline 类,【值】为优先级,ItemPipeline 是按照优先级来调用的,值越小,优先级越高。通过这个值来调控 ItemPipeline 执行的顺序。
2.4.3 专用 ItemPipeline
Scrapy 框架内部提供了两个 Item Pipeline,专门用于下载文件和图片:
*FilesPipeline 和 ImagesPipeline *
我们可以将这两个 Item Pipeline 看作特殊的下载器,用户使用时只需要通过 item 的一个特殊字段将要下载文件或图片的 url 传递给它们,它们会自动将文件或图片下载到本地,并将下载结果信息存入 item 的另一个特殊字段,以便用户在导出文件中查阅。
ImagesPipeline 使用说明
用法如下:
from scrapy.pipelines.images import ImagesPipeline // 记得导入
class PicturePipeline(ImagesPipeline): // 类名字无所谓,需要继承基类 ImagesPipeline
def get_media_requests(self, item, info): // 这个定义名唯一
for image_url in item['img_s']:
yield scrapy.Request(image_url, meta={'filename': item['title']})
// 如果还需要对图片进行分类整理,还需重写以下方法
def file_path(self, request, response=None, info=None):
## 重命名,若不重写这函数,图片名为哈希
## 提取 url 前面名称作为图片名。
filename = request.meta.get('filename')
image_guid = request.url.split('/')[-1]
return os.path.join(filename, image_guid)
def item_completed(self, results, item, info):
## 下载完进行一些处理
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item其中包含了下载图片或文件的最重要的组件:
get_media_requests()是用来发送请求的,需要传入图片的网址,一定要有。file_path()是用来指定保存的文件的名字。item_completed() 当请求完成后进行的操作- 除了编写图片管道文件,还要在配置环境中激活,以及指定图片的存储位置。在 settings.py 在添加 IMAGES_STORE = ‘./images’
FilesPipeline 使用说明
使用 FilesPipeline 下载页面中所有 PDF 文件,可按以下步骤进行:
在配置文件 settings.py 中启用 FilesPipeline,通常将其置于其他 Item Pipeline 之前:
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}在配置文件 settings.py 中,使用 FILES_STORE 指定文件下载目录,如:
FILES_STORE = '/home/liushuo/Download/scrapy'在 Spider 解析一个包含文件下载链接的页面时,将所有需要下载文件的 url 地址收集到一个列表,赋给 item 的 file_urls 字段(item['file_urls'])。FilesPipeline 在处理每一项 item 时,会读取item['file_urls'],对其中每一个 url 进行下载。
Spider中示例代码如下:
class DownloadBookSpider(scrapy.Spider):
def parse(response):
item = {}
# 下载列表
item['file_urls'] = []
for url in response.xpath('//a/@href').extract():
download_url = response.urljoin(url)
# 将 url 填入下载列表
item['file_urls'].append(download_url)
yield item当 FilesPipeline 下载完 item['file_urls'] 中的所有文件后,会将各文件的下载结果信息收集到另一个列表,赋给 item 的 files 字段(item['files'])。下载结果信息包括以下内容:
● Path 文件下载到本地的路径(相对于 FILES_STORE 的相对路径)。
● Checksum 文件的校验和。
● url 文件的 url 地址。
2.4.4 POST 请求
在 Spider.py 爬虫文件里:
import scrapy
import requests
class LgSpider(scrapy.Spider):
name = 'lg'
allowed_domains = ['lagou.com']
# start_urls = ['http://lagou.com/'] // 不能再用这个起始 url 了,需要重写
def start_requests(self):
yield scrapy.http.JsonRequest('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false',
data={ 'first': 'true',
'pn': 1,
'kd': 'python' },
headers=headers),
def parse(self, response):
print(response.text)也可以在这个文件里继续添加请求头信息:
def get_cookie():
cookie=requests.get(
'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',},
allow_redirects=False).cookies.get_dict()
return cookie
headers={ 'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'cookies':get_cookie()} 2.5 Middlewares
Downloader Middlewares(下载器中间件),位于 scrapy 引擎和下载器之间的一层组件。作用:
- 引擎将 请求 传递给下载器之前, 下载中间件 可以对 请求 进行一系列处理。比如设置请求的 User-Agent,设置代理等
- 在下载器完成将 Response 传递给引擎之前,下载中间件可以对响应进行一系列处理。比如进行 gzip 解压等。
我们主要使用下载中间件处理请求,一般会对请求设置随机的 User-Agent,设置随机的代理。目的在于防止爬取网站的反爬虫策略。
2.5.1 Headers 配置
将请求头 headers 放到middlewares.py
//middlewares.py 文件下
from scrapy import signals
class UserAgentMiddleware(object):
def process_request(self, request, spider):
request.headers.update({
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
})
return None // 没有异常就返回 None配置完成之后记得在 settings.py 里添加:
DOWNLOADER_MIDDLEWARES = {
'lagou.middlewares.UserAgentMiddleware': 543,
}利用 faker 库生成 UserAgent
from faker import Faker
class UserAgentMiddleware(object):
def __init__(self):
self.fake=Faker()
def process_request(self, request, spider):
request.headers.update({
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'User-Agent': self.fake.user_agent(),
})
return None2.5.2 cookies 配置
将cookies放到middlewares.py
import requests
def get_cookie():
cookie=requests.get('https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',},
allow_redirects=False).cookies.get_dict()
return cookie
class CookiesMiddleware(object):
def process_request(self, request, spider):
request.cookies.update(get_cookie())
return None配置完成之后记得添加到 settings.py 里。
cookies 也可以在 headers 里一起配置。
2.5.3 Proxy 配置
将proxy放到middlewares.py
import requests
class ProxyMiddleware(object):
def process_request(self, request, spider):
request.meta['proxy']='http://223.199.16.186:9999'
return None配置完成之后记得在 settings.py 里添加。
2.5.4 超时与重试
有时候我们设置的代理 ip 网速比较慢,这时候就可以在 settings.py 里设置超时与重试。
// 请求失败就换下一个代理 ip
DOWNLOAD_TIMEOUT=5
# RETRY_ENABLED=True // 这个是默认的
RETRY_TIMES=53、CrawlSpider
Scrapy 框架中分两类爬虫:
Spider 类和 CrawlSpider 类。上面介绍的都是第一类爬虫——Spider 类。
这部分我们开始介绍第二类爬虫。
Crawlspider 是 Spider 的派生类 (一个子类),Spider 类的设计原则是只爬取 start_url 列表中的网页,而CrawlSpider 类 定义了一些规则 (Rule),可以更方便的跟进网页中的 Link,自动捕获并请求,从而 进行全站数据爬取。
3.1 项目创建
scrapy startproject + 项目名称创建一个项目(名为 qutos):
cd (目标文件夹)
scrapy startproject qutos进入项目文件夹:
cd qutos使用模板生成一个 Crawlspider:
scrapy genspider -t crawl 爬虫名称 + 域 生成爬虫界面是这样的
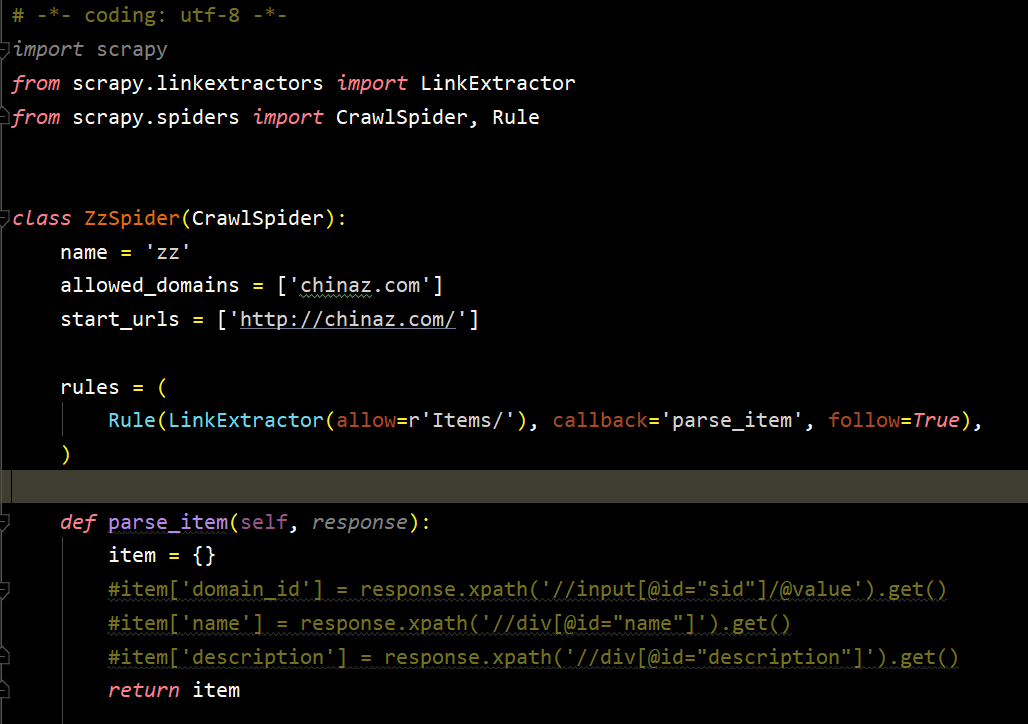
3.2 Rules 参数
CrawlSpider 使用 rules 来决定爬虫的爬取规则,并将匹配后的 url 请求提交给引擎。所以在正常情况下,CrawlSpider 不需要单独手动返回请求了。
在 rules 中包含一个或多个 Rule 对象,每个 Rule 对爬取网站的动作定义了某种特定操作,比如提取当前相应内容里的特定链接,是否对提取的链接跟进爬取,对提交的请求设置回调函数等。
Rule : 规则解析器。根据链接提取器中提取到的链接,根据指定规则提取解析器链接网页中的内容。
一个 Rule 对象表示一种提取规则。
3.2.1 LinkExtractor
顾名思义,作用就是链接提取器。
LinkExtractor(allow=r'Items/', deny=, restrict_css=, restrict_xpaths=,deny_domains=)其中 allow= 和deny=是采用 正则匹配 需要爬取(不爬取)的链接;
restrict_css=和 restrict_xpaths= 是进一步对链接进行限制,采用 css 或 xpath 选择器;
deny_domains=可以指定过滤掉的域名。
3.2.2 其他
callback: 从 link_extractor 中每获取到链接时,参数所指定的值作为回调函数,该回调函数接受一个 response 作为其第一个参数。
注意:当编写爬虫规则时,避免使用 parse()作为回调函数。由于 CrawlSpider 使用 parse 方法来实现其逻辑,如果覆盖了 parse 方法,crawl spider 将会运行失败。
follow:默认设置为 True ,否则默认为 False。指定了是否将链接提取器继续作用到链接提取器提取出的链接网页中。。
callback:指定规则解析器解析数据的规则(回调函数)
process_links:指定该 spider 中哪个的函数将会被调用,从 link_extractor 中获取到链接列表时将会调用该函数。该方法主要 用来过滤。
process_request:指定该 spider 中哪个的函数将会被调用, 该规则提取到每个 request 时都会调用该函数。 (用来过滤 request)。
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net