一、shell 编程概述
在 Linux 下有一门脚本语言叫做:Shell 脚本,这个脚本语言可以帮助我们简化很多工作,例如编写自定义命令等,所以还是很有必要学习它的基本用法的。
本质上讲,shell 是 linux 命令集的概称,是属于命令行的人机界面。shell 里语句可以直接是 linux 命令的执行。
shell分为几个版本,Bourne Shell, C Shell,Bash (Bourne Again Shell),Korn Shell,Z Shell 等版本。
常用的 shell 主要有两种:Bash 和 C Shell,特点如下:
- Bash 是 GNU 项目的一部分,是最广泛使用的 Shell 之一。
- 完全兼容 Bourne Shell,并扩展了大量功能,如命令行编辑、命令补全、历史记录等。
- 支持函数定义、数组操作、关联数组(从版本 4 开始)等高级特性。
- 非常适合脚本编写和日常使用,是 Linux 系统默认的 Shell。
- 在 linux 中,bash 默认的环境配置文件路径在~/.bashrc,用户在登录后,默认执行该配置。
- C Shell 提供一种更接近于 C 语言语法的脚本环境。
- 支持命令历史记录、别名、文件名补全等功能,提高了交互效率。
- 提供了一些类似于 C 语言的控制结构(如
if、switch),便于熟悉 C 的开发者使用。 - 不适合复杂的脚本编程,因为它的变量处理不如 Bash 灵活。
- 在 linux 中,csh 默认的环境配置文件路径在~/.cshrc,用户在登录后,默认执行该配置。
1.1 编程范式
#!/bin/bash
input="ssxx"
# 主函数
main (){
prepare_env $input $out1
do_work $out1 $out2
}
# 功能函数 1
function prepare_env(){
local x1=$1 #推荐使用 local 声明局部变量
echo "Prearing $x1"
}
# 功能函数 2
function do_work(){
local x1=$1
echo "Working $x1"
}
main "$@" # 一定要最后调用 main 函数1.2 执行字符串命令 eval
#!/bin/bash
cmd="echo"
fullCMD="$cmd hello | wc -l"
eval $fullCMD #将字符串拼接成命令执行二、开始 Bshell
shell 语言是 linux 命令集的概称,shell 可以通过其条件语句和循环语句等,把一系列 Linux 命令结合在一起,形成一个相当于面向过程的程序。
同时,在语法上,shell 语言格式与其他编程需要有相当大的不同。这个做一个简单的总结:
- 用 # 进行单行注释,也可多行注释,多行注释请百度,一般用的少
- 用空格分割命令,空格不能随便用
- 用换行分割语句,分号也可用来分割语句。语句可以是一个命令,也可以是一个关键词。
- 对缩进没有要求,但是尽可能好看点,便于阅读
一个简单的 hello.sh 脚本像下面这样:
#!/bin/bash # 标识该 Shell 脚本由哪个 Shell 解释
echo "Hello World!" # 打印输出字符 Hello World!运行 shell 脚本:在 CMD 命令行下,sh hello.sh 即可,也可 ./hello.sh 运行
后台运行:sh hello.sh & ,若退出终端的运行就会挂掉。
后台挂起运行:nohup sh hello.sh &,hohup 的作用是:用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。
Shell 的编写流程:
- 编写 Shell 脚本
- 赋予可执行权限(一般可以忽略)
- 执行,调试
2.1 shell 关键字
所有的 linux 命令都可以在 shell 脚本里直接使用,比如:
#!/bin/bash
input=`ls ./teat/*` #`` 是反引号,通常位于 esc 键下面,用于执行 linux 的 ls 命令并返回结果除此之外,bshell 还有以下关键字用于脚本编写。
2.1.1 基本关键字
基本常用的关键字如下:
- echo:打印文字到屏幕
- exec:执行另一个 Shell 脚本
- read:读标准输入
- expr:对整数型变量进行算术运算
- test:用于测试变量是否相等、 是否为空、文件类型等
- exit:退出
看个例子,新建文件 test.sh,写入:
#!/bin/bash
echo "Hello Shell" # 打印输出字符串 Hello Shell
# 读入变量(从屏幕输入)
read VAR
echo "VAR is $VAR"
# 计算变量
expr $VAR - 5 #算术运算,并返回值
# 测试字符串
test "Hello"="HelloWorld"
# 测试整数
test $VAR -eq 10
# 测试目录
test -d ./Android
# 执行其他 Shell 脚本
exec ./othershell.sh
# 退出
exit$ 符号是对变量取值
2.1.1 各种重要符号
$ 变量名:对变量取值${ 变量名 }:对变量取值,花括号的作用仅仅是精确界定变量名称的范围。$(命令或函数名):执行 命令或函数,并返回执行结果。与反引号 ` 命令或函数名 ` 作用一致- $() 重新开一个子 shell 进行执行里面的命令,不影响当前的 shell 环境
$[1+2]与$((2+1)):进行整数运算,注意这里可以没有空格[]:条件判断符号,用于条件测试,见 2.5 章节(()):仅仅用于整型数字的计算与比较[[]]:双方括号为字符串比较提供高级功能,可以模式匹配。常见用法见 2.4.2。[[是 bash 程序语言的关键字。- 下面写法中,有的为了避免 [] 符号在 markdown 格式中的特殊性,使用【】暂代
- 建议使用 [[]] 代替[]
;分号或换行,一个 / 一句命令的结束- 引号:见 2.2.1 章节
== 与 = 的区别
- == 可用于判断变量是否相等,= 除了可用于判断变量是否相等外,还可以表示赋值。
- = 与 == 在 [] 中表示判断 (字符串比较) 时是等价的
- 在 (()) 中 = 表示赋值, == 表示判断(整数比较),它们不等价
2.2 字符串
shell 就两种数据类型,字符型和数组。数字(整型)也可以看作是一种字符串。
在 Shell 中所有的变量默认都是字符串型。字符串可以用单引号,也可以用双引号,也可以不用引号。
字符串赋值时,变量名和等号之间 不能有空格
取值时,只要在变量名前面加美元符号 $ 即可,也可使用 ${变量名}
2.2.1 引号
单引号:里面写变量无效
str='this is a string'- 单引号里的任何字符都会 原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
双引号:可以含变量名
name="Jack" str="my name is $name"- 双引号里可以有变量
- 双引号里可以出现转义字符
不加引号
path=/home/qiang/ file=$path/xor.txt- 只能是连续字符串,不能有空格
- 可以有变量
- 可以出现转义字符
反引号 `:代表执行里面的命令
这个符号通常位于键盘 Esc 键的下方。当用尖角号括起来一个 shell 命令时,代表执行这个命令,并将执行的结果返回给赋给的变量。
2.2.2 字符串方法
2.2.2.1 常规方法
获取长度:
${#str},获取 str 变量的字符串长度提取子串(切片):
${str:1:4},从第 2 个字符开始,截取 4 个字符${str:2},从第 3 个字符开始,截取后面所有字符${str:2:-1},从左往右第 3 位开始截取,从右往左截取到第一位
查找子串:
awk -v s="$str" 'BEGIN{print index(s, "xy")}' # 子串查找,0 表示未找到 if 【【 $str == *"xy"* 】】 #判断 $str 中是否有“xy”拼接字符串:
"hello, ""$name",直接写在一块就行。字符串替换:
${var/pattern/replacement}替换一个${var//pattern/replacement}全局替换
2.2.2.2 匹配删除
直接匹配:
语法 说明 ${str#hello}如果 str 以 hello 为 开头 就删掉 hello ${str%hello}如果 str 以 hello 为 结尾 就删掉 hello 通配符匹配:
语法 含义 示例(var=”a_b_c.txt”) 结果 ${var# 模式 }从开头删,最短匹配 ${var#*_}b_c.txt${var## 模式 }从开头删,贪婪匹配 ${var##*_}c.txt${var% 模式 }从结尾删 , 最短匹配 ${var%.txt}a_b_c${var%% 模式 }从结尾删,贪婪匹配 ${var%%.*}a_b_c通配符:
通配符 含义 *匹配任意字符(包括空) ?匹配任意单个字符 [abc]匹配 a、b 或 c [0-9]匹配数字 举例:
#!/bin/csh var="/home/ju/test/mingtian_ver_vc01.txt" varname=${var##*/} # 输出文件名 mingtian_ver_vc01.txt
2.2.3 字符串分割
方法 1:IFS
IFS='.' read inlayer intype <<< "199.0" #以点为分隔符,两分割之后的参数分别赋给 inlayer 和 intype这个用法很有意思,后面会单独进行介绍。见 2.9.3 章节
方法 2:cut
input="199 200 201" x1=$(echo $input | cut -d " " -f 1) x2=$(echo $input | cut -d " " -f 2) x3=$(echo $input | cut -d " " -f 3)借助
cut命令,-d指定分隔符,-f指定分割之后的第 n 个字段cut 的分隔符只能是单个字符
2.2.4 字符串的遍历
# 单行写法
arr1="xxx yyy zz"
# 多行写法
arr2="
xxx
yyy
zzz
"
#----- 字符串的遍历
for item in $arr2; do
echo $item
done2.3 shell 变量
Shell 变量分为 3 种:
- 用户自定义变量
- 等号前后不要有空格:
NUM=10 - 一般变量名用大写:
M=1
- 等号前后不要有空格:
- 预定义变量
- 环境变量
2.3.1 自定义变量
这种变量 只支持字符串类型,不支持其他字符,浮点等类型。
一个例子:
#!/bin/bash
# 定义普通变量
CITY=SHENZHEN #将字符串 SHENZHEN 赋给变量 CITY
CITY="GUANGZHOU" #建议使用双引号
# 定义全局变量
export NAME=cdeveloper
# 定义只读变量
readonly AGE=21
# 打印变量的值
echo $CITY
echo $NAME
echo $AGE
# 删除 CITY 变量
unset CITYunset:删除变量readonly:标记只读变量export:指定全局变量
变量指定默认值:
${var:-word}:若 var 为空或未设置,返回默认值,但是并不把默认值赋值给该变量。${var:=word}:若 var 为空或未设置,把默认值赋值给该变量。${var:+word}:若 var 不为空时,返回默认值,并且也不重新赋值
2.3.2 预定义变量
预定义变量常用来获取命令行的输入,有下面这些:
$0:脚本文件名$1-9:第 1-9 个命令行参数名$#:命令行参数个数$@:所有命令行参数$*:所有命令行参数$?:前一个命令的退出状态,可用于获取函数返回值$$:执行本 shell 的进程 ID$!:执行的上个命令的进程 ID
在运行 shell 脚本的时候,可以外部传参,供脚本内部使用:
sh test.sh param1 parma2 parma3 #运行 test.sh 脚本并传入三个参数 param1 parma2 parma3这时候这 7 个预定义变量的作用就容易出来了。
一个例子执行sh.test.sh x y z:
#!/bin/bash
echo $0 #输出 test.sh
echo $1 #输出 x
echo $2 #输出 y
echo $3 #输出 z
echo $# #输出 3
echo $@ #输出 x y z
echo $* #输出 x y z
echo $? #输出 0
echo $$ #输出 1847152.3.3 环境变量
环境变量默认就存在,常用的有下面这几个:
HOME:代表用户主目录PATH:代表系统环境变量 PATHTERM:代表当前终端UID:代表当前用户 IDPWD:代表当前工作目录,绝对路径
看一个例子:
#!/bin/bash
echo "print env"
echo $HOME #输出 /home/origin
echo $PATH #输出 /home/orange/anaconda2/bin: 后面还有很多
echo $TERM #输出 xterm
echo $PWD #输出 /home/origin/test
echo $UID #输出 16742.4 shell 运算符
由于 Shell 中所有的变量默认都是字符串型,故在运算时,不同于常规运算方法。
2.4.1 算术运算
shell 的算术运算只支持整型数字运算(包括正负整型),不支持浮点数。
在算术运算时,非数字的单字符或字符串都被 shell 当作 0。
常用的四种运算格式(都是计算 m+10):
m=$[m+10]m=$((m+10))let m=m+10#除了let后面有空格,计算中必定不能存在空格,只能赋值,不能直接输出- 利用
expr命令
举例说明:
#!/bin/sh
aa=10
bb=$((aa+10))
bb=$[aa+10]
let bb=aa+10
bb=`expr $aa + 10`
if ((aa == 10)); then
((aa++))
fi
echo $aa #输出 11支持的运算符如下:
- 加号(+)、减号(-)、乘法(*)、除法(/)、取余(%)、赋值(=)、自增(++)、自减(–)
小数(浮点数)运算
- 利用 bc 模块
bc是Linux下的计算机工具模块,bc支持交互式和非交互式两种计算,在进行计算的时候,可以使用scale=n来指定小数点的位数,还支持比较操操作符>、>=、<、<=、==、!=。交互式:打开bc计算机,进行使用。非交互式:通过脚本命令执行,不需要打开计算机。- 在使用
bc命令时如果报错bc: command not found,说明没有安装此工具模块,需要进行安装:
- 利用 awk 模块
awk是一种编程语言,用于在 linux/unix 下对文本和数据进行处理。在本博客另一文章有介绍[linux 常见命令学习](https://jqiange.github.io/linux 常见命令学习 /#3-2-awk 命令)
举例:
#!/bin/bash
echo "scale=2;10/3" | bc #scale=2 是指定计算精度为 2 为小数,计算 10/3 的值
result=`echo "scale=2;10/3" | bc`
#------ 传参, 2 种方式
result=$(bc -l <<< "scale=2;$a * $b")
result=`echo "$a + $b" | bc`
#----- awk
awk 'BEGIN { print 3.14 + 2.86 }'
awk 'BEGIN { printf "%.2f", 10 / 3 }' # 保留两位小数
awk -v a=$index -v b=$count 'BEGIN { printf "%.2f", a*b }'关于 awk 中的 begin:
| 写法 | 是否需要输入 | 执行时机 | 适合场景 |
|---|---|---|---|
BEGIN { ... } |
不需要 | 启动时立即执行 | 变量计算、初始化 |
{ ... } |
需要至少一行输入 | 每读一行执行一次 | 处理文本行 |
2.4.2 逻辑运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑 AND | (( $a > 0 && $b < 10 )) |
| || | 逻辑 OR | (( $a >= 0 || $b < 10 )) |
特点:
- 短路求值:如果
command1失败,command2不会执行 - 用于命令流程控制,不是专门用于条件测试。
举例:
#!/bin/sh
index=0
file="test.txt"
#---- 写法 1
if ((index == 0)) && 【【 -f $file 】】; then
echo "hello" > $file
fi
#---- 写法 2
if 【【 $index == "0" && -f $file 】】; then
echo "hello" > $file
fi
#--- 写法 3
if 【 $index -eq 0 】 && 【 -f $file 】; then
echo "hello" > $file
fi为了避免 [] 特殊性,书写时用【】代替,实际脚本还是要用[]
2.4.3 布尔运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| ! | 取反运算 | 【 ! -f $file 】 |
这里只需要记住这个即可,其他的布尔运算符不建议用。
2.5 条件测试
shell 条件测试一共就三种: 文件测试 , 数值比较 , 字符串比较
条件测试分为三种用法,但作用是一样的:
test 条件表达式【 文件 / 字符串比较 】【【 文件 / 字符串比较 】】((整数比较))
2.5.1 文件测试[]
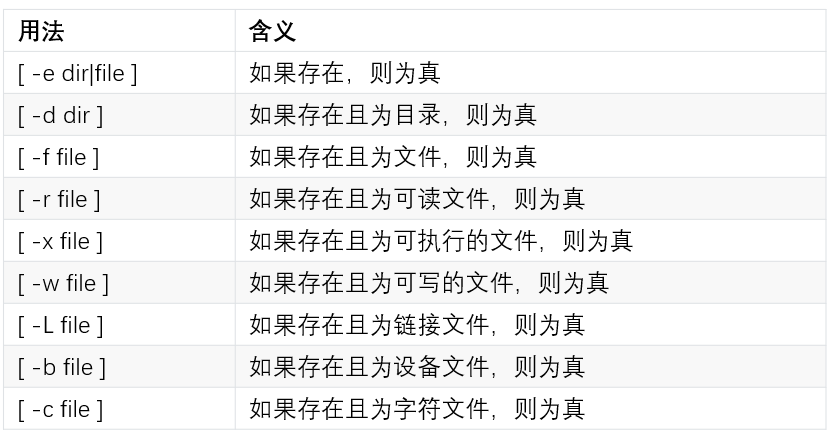
用法示例:
【 ! -d /home/test 】 && makdir /home/test #目录不存在就创建
【 -d /home/test ]】 || makdir /home/test #目录存在就不创建
test -d /home/test
echo $?
0 #在 shell 中,为真的退出状态码为 0,为假时状态码为 1为了避免 [] 特殊性,书写时用【】代替,实际脚本还是要用[]
2.5.2 数值比较 [] 和(())
关系运算符只支持 整数运算,不支持字符串,除非字符串的值是数字。
- 在
[]或test中仅仅支持自 字母 运算符
- 在
(())仅仅使用 符号 运算符
| 字母运算符 | 符号运算符 | 示例 | 说明 |
|---|---|---|---|
-eq |
== |
【 "$a" -eq "$b" 】 或 ((a == b)) |
等于 |
-ne |
!= |
【 "$a" -ne 5 】 或 ((a != 5)) |
不等于 |
-lt |
< |
【 "$a" -lt 10 】 或 ((a < 10)) |
小于 |
-le |
<= |
【 "$a" -le 10 】 或 ((a <= 10)) |
小于等于 |
-gt |
> |
【 "$a" -gt 0 】 或 ((a >= 0)) |
大于 |
-ge |
>= |
【 "$a" -ge 100 】 或 ((a >= 100)) |
大于等于 |
必须用双引号包裹变量(防止空值导致语法错误)
【 "$count" -gt 5 】 # ✅ 安全
【 $count -gt 5 】 # ❌ 若 count 为空,会报错浮点数比较
a=3.14
b=2.71
#---- 比较 a > b ?
if 【 "$(echo "$a > $b" | bc)" == "1" 】; then
echo "a 大于 b"
fi2.5.3 字符串比较[]
字符串变量要使用双引号引起来

用法示例:
cha="aa"
if 【 "$cha" == "aa" 】; then
echo "is aa"
fi
# [[]]支持通配符,属于 [] 的进阶版
if 【【 "$file" = *".jpg" 】】; then
echo "$file is jpg file"
fi
if 【【 "$str" =~ ^[a-z]+[0-9]+$ 】】; then
echo " 匹配字母 + 数字 "
fi2.5.4 [[]]与 [] 比较
| 特性 | [](test 命令) |
[[]](Bash 扩展) |
|---|---|---|
| 标准 | POSIX 标准,所有 shell 兼容(如 /bin/sh) |
Bash / Zsh / Ksh 等支持,非 POSIX |
| 是否内置 | 多数 shell 内置,但本质是 test 命令 |
Bash 内置语法(不是命令) |
| 安全性 | 较弱(需严格引号) | 更强(自动处理空格、通配符等) |
| 功能 | 基础比较 | 支持正则、模式匹配、逻辑组合等 |
建议使用 [[]] 代替[]
2.6 shell 语句
2.6.1 if 语句
格式:
if 条件测试 1 ; then
执行语句 1
elif 条件测试 2; then
执行语句 2
else
执行语句 2
fi用法示例:
#!/bin/bash
VAR=10
if ((VAR == 10)); then
echo "true"
else
echo "false"
fi
if 【 -f "$inputfile" 】; then
echo " 文件存在 "
fi2.6.2 case 语句
格式:
case $ 变量 in
值 1)
执行语句 1
;;
值 2)
执行语句 2
;;
*)
执行语句 3
;;
esac 2.6.3 for 语句
格式:
#--- 格式 1
for ((i = 1; i <= 3; i++))
do
echo $i
done
#--- 格式 2
for j in 1 2 3
do
echo $j
done
#--- 格式 3
for j in {0..100} #输出 0-100
do
echo $j
done
workspace="/home/user1/project"
input=`ls ./teat/*.gg`
for ff in $input ; do
out="$workspace/$input"
echo $out
done
2.6.4 while 语句
格式:
while 条件测试 #条件为真,执行
do
执行语句
done
# 举例
while True; do
if (($finishedNum >= $totalJob)); then
echo "all jobs have done!"
break # 跳出 while 循环
fi
done2.6.5 until 语句
格式:
until 条件测试 #条件为假,执行
do
echo $i
i=$((i+1))
done2.6.6 break
Shell 中的 break 用法与高级语言相同,都是 跳出循环,来看个例子:
for VAR in 1 2 3
do
if ((VAR == 2)) ; then
break
fi
echo $VAR
done2.6.7 continue
continue 用来 跳过本次循环,进入下一次循环
for VAR in 1 2 3
do
if (($VAR == 2)); then
continue
fi
echo $VAR
done2.7 shell 数组
shell 就两种数据类型,字符型和数组。字符串之前已经介绍了,这里介绍数组。
数组中可以存放多个值。Bash Shell 只支持一维数组(不支持多维数组),初始化时不需要定义数组大小。
2.7.1 数组定义
- 格式 :以括号
()定义
# ---- 第一种
arr=(v1 v2 v3 v4 v5) #v 可以是字符串或者数字,不必类型相同
# ---- 第二种
arr1=(
xxx
yyy
)
#---- 数组的遍历
for case in ${arr1[*]}
do
echo $case
done一对括号 (…) 表示的是数组,数组元素用空格符号分隔开
数组和字符串循环取值的方式不同,注意区分
2.7.2 读取与赋值
- 读取数组:
- 读取整个数组:
${arr[@]}或者${arr[*]} - 按索引读取:
${arr[index]},索引从 0 开始
- 读取整个数组:
- 读取长度:
${#arr[@]}或者${#arr[*]} - 赋值:
arr[1]=100 - 删除:
unset arr[1]或unset arr - 替换:
${a[@或 *] / 查找字符 / 替换字符 },该操作不会改变原来的数组内容
一个常用的例子:
caselist=($(ls /home/template_dir | grep -v 'xor')) #()目的是转为数组
for case in ${caselist[*]}
do
echo $case
done2.8 shell 字典(关联数组)
这里的字典是一种通俗说法,Bash 语言里,标准叫法是 关联数组 (Associative Array)允许使用 字符串键 来存取数据,同时功能也类似于其他语言的字典或 Map(Bash 4.0+ 支持)。它非常适合存储键值对数据,如配置项、统计结果等。
2.8.1 示例
#!/bin/bash
# 声明关联数组
declare -A userInfo
# 添加键值对
userInfo["name"]="Alice"
userInfo["age"]=28
userInfo["city"]="Seattle"
# 访问单个元素
echo "${userInfo["name"]}"
# 遍历所有键值对
for key in "${!userInfo[@]}"; do
echo "$key: ${userInfo[$key]}"
done2.8.2 扩展
- 定义数组直接赋值
declare -A site=(["google"]="www.google.com"
["runoob"]="www.runoob.com"
["taobao"]="www.taobao.com"
)- 常用操作
# 获取所有键和值
echo " 所有键: ${!site[@]}"
echo " 所有值: ${site[@]}"
# 获取长度
echo " 元素个数: ${#site[@]}"
# 删除元素或整个数组
unset site["google"] # 删除单个键
unset site # 删除整个数组
# 检查键是否存在
if [[-v site["runoob"] ]]; then
echo " 键存在 "
fi- 键必须唯一,重复赋值会覆盖原值。
- 遍历顺序无固定保证,不建议依赖顺序处理。
- 使用
"${!array[@]}"获取键时建议加双引号,避免空格分割问题。
2.9 shell 函数
shell 函数中,默认均为全局变量。Bash 函数体内直接声明的变量,属于全局变量,整个脚本都可以读取。这一点需要特别小心。
如想用局部变量加 local 关键字
2.9.1 函数定义与调用
bash 函数的定义有两种:
# 第一种
fn() {
# codes
}
# 第二种,如果写了 function 关键字,()可以省略
function fn() {
# codes
}
# 函数调用
fn # 无参调用
fun "1" "2" "$params" # 有参调用fn是自定义的函数名,函数代码就写在大括号之中。这两种写法是等价的。- 函数传参时,如果是传的变量名,最好加上双引号
2.9.2 参数变量与返回值
函数体内可以使用参数变量,获取函数参数。函数的参数变量,与脚本参数变量是一致的。
$1~$9:函数的第一个到第 9 个的参数。$0:函数所在的脚本名。$#:函数的参数总数。$@:函数的全部参数,参数之间使用空格分隔。$*:函数的全部参数,参数之间使用变量$IFS值的第一个字符分隔,默认为空格,但是可以自定义。
如果函数的参数多于 9 个,那么第 10 个参数可以用 ${10} 的形式引用,以此类推。
示例:
function fun1(){
local aa=$1 #$1 获取传入函数的第一个参数
local bb=$2 #$2 获取传入函数的第二个参数
echo "$aa" #返回方式 1
return 0 #返回方式 2
}
# 获取函数返回值
F=`fun1 100 200`
echo $F # 输出获取到的 $aa
echo $? # 输出 return 的 0bash 函数返回值,常用的两种方式:return、echo。二者是有差别的
return:只能用来返回整数值(0-255),一般是用来表示函数执行成功与否的,0 表示成功,其他值表示失败。
echo:标准输出返回,可以返回任何类型的数据。
函数用 echo 输出返回:直接函数名调用
函数用 return 输出返回:
$?接收,$?要紧跟在函数调用处的后面
函数其他的调用方法
- 函数名当命令执行:`fun2` (反引号) 或者
$(fun2) - 传参输出返回:$(fun2 “/temp”)
再举个例子:
fun() {
echo "fun call"
}
echo `fun` #输出打印 fun call
echo $(fun) #输出打印 fun call
re=$(fun)
echo ${re} #输出打印 fun call2.9.3 高级收参
$@ 可以接收所有参数, 以数组的方式。
function getsum(){
local sum=0
for n in $@ ; do
((sum+=n))
done
echo $sum
return 0
}
total=$(getsum 10 20 55 15)
echo $total2.9.4 字符串变数组
IFS= read -ra datas <<< "10 20 30 40" read -ra 是 Bash 中 read 命令的一个非常实用的组合选项,它结合了两个功能:
-r(raw input):防止反斜杠转义。-a(array):将读取到的内容分割成单词,并存储到数组中。
2.10 shell 重定向
2.10.1 命令输出
命令的结果不再输出到显示器上,而是输出到指定的文件里。
格式:
command > file #覆盖写入到文件
command >> file #追加写入到文件用法示例:
echo "hello world!" > data.txt
ls -l >> data.txt2.10.2 多行字符串输出
- cat 输出重定向
- echo 输出重定向
用法示例:
# 方法 1
cat > config.txt << EOF
export ORACLE_SID=yqpt
export PATH=\$PATH:\$ORACLE_HOME/bin
EOF
# 方法 2
headline="
this is a test
for example, to write into a file
"
echo "$headline" > test.txt # 注意这里变量名需要加双引号,就可以保留文本的换行符方法 1:将两个 EOF 之间的内容输出写到 data.txt 文件里。
- EOF 只是一个标识符,也可使用其他字符代替
- 当多行文本有 $ 等特殊字符时,如果需要 $ 符号保留进文件,须利用转义字符 \
方法 2:利用定义的多行字符串变量,直接用 echo 双引号变量名,写入到指定文件名里
2.10.3 给命令输入参数
使用文件作为命令的输入。
command < file #将 file 文件中的内容作为 command 的输入
command << END #从标准输入(键盘)中读取数据,直到遇见分界符 END 才停止 循环依次读入文本数据:
while read ...;do ... done < input.csv示例:
#!/bin/bash
sum=0
while read n; do
((sum += n))
done < nums.txt # 输入重定向
echo "sum=$sum"2.10.4 输入并指定分隔符
详解 VAR=value command arguments 结构,以下面为例:
IFS='.' read inlayer intype <<< "199.0" #以点为分隔符,两分割之后的参数分别赋给 inlayer 和 intype解释 <<<
<<< "$str"是 Here String 的写法,是 Bash 独有的一个特性- 它的作用是将
"$str"变量的值作为标准输入(stdin)传递给read命令 - 这比使用管道
echo "$bbox_layer" | read ...更高效,因为它避免了启动一个新的子进程来执行echo
解释 read inlayer intype
read是一个 Bash 内置命令,用于从标准输入读取一行文本,并将其中的内容赋值给指定的变量- 在这里,它会尝试读取一行文本,并将第一个“单词”赋值给
inlayer,将第二个“单词”赋值给intype
解释 IFS='.'
IFS是一个特殊的 Bash 环境变量,全称是 Internal Field Separator(内部字段分隔符)- 它定义了 Bash 在进行单词拆分(word splitting)时使用的分隔符
- 默认情况下,
IFS包含空格、制表符(tab)和换行符 - 在这个命令中,
IFS='.'临时将IFS的值设置为点.。这意味着read命令在处理输入时,会把点.当作字段之间的分隔符,而不是默认的空格、tab 等 - 命令执行完毕后,
IFS的值会恢复到它在命令执行之前的状态(因为IFS='.'是作为read命令的前缀,它的作用范围仅限于该命令)
这三部分连用的解释:
<<< "199.0"将"199.0"作为标准输入传递给read命令。IFS='.'临时将IFS设置为.。read inlayer intype命令开始从标准输入读取"199.0"。read遇到第一个字段分隔符.之前的部分199,将其赋值给第一个变量inlayer。read遇到第二个字段分隔符(或者到达行尾)之前的部分0,将其赋值给第二个变量intype。- 命令执行完毕后,
IFS的值会恢复到它在命令执行之前的状态(因为IFS='.'是作为read命令的前缀,它的作用范围仅限于该命令)。
为什么这三部分可以这样连用,这主要涉及到以下几个概念:
- 命令前缀(Command Prefix):在 Bash 中,你可以在一个命令前面放置变量赋值,这些赋值只对当前命令有效,而不是全局生效。
- 命令(Command):
read是一个 Bash 内置命令。 - 重定向(Redirection):
<<<是 Here String 重定向操作符。
当 Bash 看到 VAR=value command arguments 这样的结构时,它会做以下事情:
- 临时设置变量: 它会先将
VAR变量设置为value。 - 执行命令: 然后,它会执行
command和其arguments。 - 恢复变量: 命令执行完毕后,
VAR变量的值会自动恢复到命令执行之前的状态(如果之前有定义的话),或者取消设置(如果之前没有定义)。
2.11 shell 调试
检查是否有语法错误:
sh -n script_name.sh执行并逐步调试 shell 脚本:
sh -x script_name.sh带有 + 表示的是 Shell 调试器的输出 , 不带 + 表示我们程序的输出。
csh 同样支持逐步调试!使用
csh -x test.sh
2.12 一些优美的例子
2.12.1 如何计数
开始之前,请注意一个细节:
&& 并联多个命令,先会执行前面的,如果前面失败,则后面的不予执行
如果分行依次执行,前行命令报错,不影响后行的执行
#!/bin/sh
# case 1
count1=0
`lla ./` && ((count1++)) # 串起命令, lla 是虚构命令,会执行失败,也就不会计数
echo "$count1" #输出 0
# case 2
count2=0
`lla ./`
((count2++)) #这种计数不可取,前面失败还是会计数
echo "$count2" #输出 12.12.2 多层循环嵌套改造
不要写多层 for 循环,难看!
直接上示例:
#!/bin/sh
# 声明数组,也可以直接 GLISTS=()
declare -a GLISTS=()
declare -a GCURRENT=()
declare -a GRESULTS=()
main() {
### test, 假设要计算四组参数,循环搭配
a="20 22 25"
b="60 70 80"
c=" 40 50"
mrc="15 20"
### 以上不用写多层 for 循环,就能得到四个参数列表的全部组合 ####
20_60_40_15
20_60_40_20
20_60_50_15
20_60_50_20
...
#######################
count_jos "$a" "$b" "$c" "$mrc" # get all combined params
for params in $allParams; do
echo $parmas
prams=${params//_/ } #将下划线分隔符替换成空格
read -r sbWd sb2m sb2sb mrc <<< "$parmas" # 分离参数并赋值
done
}
# 下面是两个【最重要】的函数
count_jobs() {
GLISTS=("$@") # all input params
GRESULTS=() # collect all
cartesian_recursive 0 # from 0 to generate
totalCounts=${#GRESULTS[*]} # get all job counts
allParams="${GRESULTS[*]}" # convert arr to str_list
}
# recursive
cartesian_recursive() {
local depth=$1
if ((depth == ${#GLISTS[@]} )); then
#echo ${CURRENT[@]}
### 如果不需要加前缀,则不需要 modified ######
# add prefix for each inputdata
# local modified=()
#for idx in "${!GCURRENT[@]}"; do
# if ((idx == 0)); then
# modified[idx]="sbar${GCURRENT[idx]}" #add "sbar" flag from 0
# elif ((idx == 3)); then
# modified[idx]="mrc${GCURRENT[idx]}" #add "mrc" flag from 3
# else
# modified[idx]="${GCURRENT[idx]}"
# fi
#done
#GRESULTS+=("$(IFS='_'; echo "${modified[*]}")") #以下划线为分隔符组合参数
#####################################
GRESULTS+=("$(IFS='_'; echo "${CURRENT[*]}")") #以下划线为分隔符组合参数
return
fi
IFS=' ' read -r -a items <<< "${GLISTS[depth]}"
for item in "${items[@]}"; do
GCURRENT[depth]="$item"
cartesian_recursive $((depth + 1))
done
}
main "$@" # 程序入口2.12.3 一直跑直到全部完成
有时候我们一个脚本提交多个 job,而服务器上资源处于紧张状态,很可能资源被抢,导致任务终止,这个程序写一个死循环,任务不跑完,脚本就一直运行!!!
totalJobs=10
finishedNum=0
while True; do
if (($finishedNum >= $totalJob)); then # must use >=
echo "all jobs have done!"
break # 跳出 while 循环
fi
for params in $allparams ; do
#...
rulefile="xxx/yyy.rule"
logfile="xxx/yyy.log"
outres="xxx/yyy.oeb"
if 【【 -f $logfile 】】 && 【【 -f $outres 】】 ; then
has_done=`cat $logfile | tail -3 | grep "yyy finished" | wc -l`
if (($has_done == 1)); then
((finishedNum++)) # only get finished by logfile 这种最可靠
continue # 停止后续 code,直接进入下一次 for 循环
fi
fi
runjob -file $rulefile # 执行任务
done
done2.12.4 一个完整的脚本
#! /bin/bash
#############################################################
### This is for realchip clips, GDS merge, lable adding
### -> [GDS and rdb name must keep the same]
### -> gg format contains NO X Y (total 3 columns)
### author: jiangq
#############################################################
###### config ###############################################
gdsList=$(ls gdsin/*.oas) # suppurt gdslist or one gds
rdbPath="rdb/" # rdb folder, rdb name must be the same with gdsname
inlayers="all" #support 1.layer list ; 2."all" means auto clip all layers
#inlayers="10.0 20.0 30.0" #support 1.layer list ; 2."all" means auto clip all layers
# set output #
outGG_flag="1" # if output new gg file
outGDS="merge_out.oas"
outGG="merge_out.gg"
outPrec=10000
# set placement rule for each clip #
clip_xSize="17" # each clip size for x-direction, unit is um
clip_ySize="17" # each clip size for y-direction, unit is um
clip_xSpace="3" # x space for each clip
clip_ySpace="3" # y space for each clip
maxColNum=3 # max num clips alone x-axis
# set if add label
gdsname_add2label="1"
#############################################################
############### usually not to edit below ###########
#############################################################
main() {
workpath="temp"
gdsTemp="$workpath/gdsout"
clear_create_folder "$workpath" "$gdsTemp"
clear_file "$outGG" "$outGDS"
ggCount=0
xPitch=$((clip_xSize + clip_xSpace))
yPitch=$((clip_ySize + clip_ySpace))
curRow=1
curCol=1
for gdsin in $gdsList ; do
name=`basename $gdsin .oas | sed "s/.gds//g"`
rdbfile=`ls ${rdbPath}/${name}*rdb`
if 【 ! -f $rdbfile 】; then
echo "$rdbfile not exists, skip it"
continue
fi
outCoord="$workpath/temp.cood"
gdsout="$gdsTemp/${name}_out.oas"
rdb2hub "$rdbfile" "$outCoord" # pass params must with ""
if 【【 "$inlayers" == *"all"* 】】; then
inlayers=`calibredrv -a layout peek $gdsin -layers | sed -E 's#\{ *([0-9]+) +([0-9]+)[^}]*\}#\1.\2#g'`
fi
clipAndArray "$outCoord" "$inlayers" "$gdsin" "$gdsout"
done
if 【 "$gdsname_add2label" == "1" 】; then
gdsName_add2lable $gdsTemp
fi
calibredrv -a layout filemerge -in $gdsTemp -out ${workpath}/temp_merged.oas -createtop NEW_TP -mode rename
addLabel "${workpath}/temp_merged.oas" "$xPitch" "$yPitch" "$maxColNum" "$ggCount" "$outGDS"
if 【 "$outGG_flag" == "1" 】; then
outputGG "$outGG" "$ggCount"
fi
}
##################################################
function rdb2hub() {
local rdbfile=$1
local outCoord=$2
csvname=`basename $rdbfile .rdb | sed "s/.orc//g" | sed "s/.tdrc//g"`".csv"
outcsv="$workpath/${csvname}"
rm $outCoord
calibre -rve -drc $rdbfile -output_csv $outcsv
index=0
# skip first row and handle by rows
tail -n +2 "$outcsv" | while IFS=, read -ra line || 【【 -n "${line[*]}" 】】; do
coord_str="${line[-1]}"
vertex_count=${line[-2]}
#echo $coord_str
pt=0
sumX=0
sumY=0
while (($pt < $vertex_count)); do
x_p=$((2* pt + 1))
y_p=$((x_p + 1))
tmp_x1=$(echo $coord_str | cut -d " " -f $x_p)
tmp_y1=$(echo $coord_str | cut -d " " -f $y_p)
coord_x1=${tmp_x1#(}
coord_y1=${tmp_y1%)}
sumX=$(bc -l <<< "scale=4;$sumX + $coord_x1")
sumY=$(bc -l <<< "scale=4;$sumY + $coord_y1")
((pt++))
done
center_x=$(bc -l <<< "scale=4;$sumX / $vertex_count")
center_y=$(bc -l <<< "scale=4;$sumY / $vertex_count")
((index++))
echo $index $center_x $center_y >> $outCoord
done
local count=`cat $outCoord | wc -l`
ggCount=`expr $ggCount + $count`
}
function clipAndArray() {
local coordfile=$1
local inlayers=$2
local gdsin=$3
local gdsout=$4
outdrc="$workpath/temp.drc"
echo "$headline" > $outdrc # headline with "" and keep format
## layer mapping input
inlayerNum=()
mapNum=51001
for layer in $inlayers ; do
if 【【 $layer == *.* 】】; then
ly_part=${layer%.*}
dt_part=${layer#*.}
if [-z "$ly_part"]; then ly_part="0" ;fi
else
ly_part=$layer
dt_part="0"
fi
lnum=$((mapNum - 51000))
layerName="L${lnum}"
echo "LAYER MAP $ly_part DATATYPE $dt_part $mapNum LAYER $layerName $mapNum" >> $outdrc
((mapNum++))
inlayerNum[$lnum]="$ly_part $dt_part" # for following use
done
total_inlayers=$((mapNum - 51001))
outBLKs=""
mkNum=1
mapNum=52001
## read coord, use [while ... do ... done < $coordfile]
while IFS= read -r line ; do
x_c=$(echo $line | cut -d " " -f 2)
y_c=$(echo $line | cut -d " " -f 3)
# get BLOCK
x1=$(echo "$x_c - 0.5 * $clip_xSize" | bc)
y1=$(echo "$y_c - 0.5 * $clip_ySize" | bc)
x2=$(echo "$x_c + 0.5 * $clip_xSize" | bc)
y2=$(echo "$y_c + 0.5 * $clip_ySize" | bc)
text1="
LAYER MAP 9999 DATATYPE $mkNum $mapNum LAYER MK$mkNum $mapNum
POLYGON $x1 $y1 $x2 $y2 MK$mkNum
"
echo "$text1" >> $outdrc
## layer clip and shift
# get shift value
if (($curCol > $maxColNum)); then
((curRow++))
curCol=1
fi
real_xLoc=$((curCol * xPitch))
real_yLoc=$((curRow * yPitch))
relative_xShift=$(echo "${real_xLoc} - $x1" | bc)
relative_yShift=$(echo "${real_yLoc} - $y1" | bc)
# handle every inlayers
layeridx=1
while (($layeridx <= $total_inlayers)); do
orilayer=${inlayerNum[$layeridx]}
oriLY=$(echo $orilayer | cut -d " " -f 1)
oriDT=$(echo $orilayer | cut -d " " -f 2)
text2="
L${layeridx}_PRE$mkNum = AND L${layeridx} MK$mkNum
L${layeridx}_OUT$mkNum = SHIFT L${layeridx}_PRE$mkNum BY $relative_xShift ($relative_yShift)
L${layeridx}_OUT$mkNum { COPY L${layeridx}_OUT$mkNum} DRC CHECK MAP L${layeridx}_OUT$mkNum $oriLY $oriDT
"
echo "$text2" >> $outdrc
((layeridx++))
done
# shift block layer
text3="
MK_OUT$mkNum = SHIFT MK$mkNum BY $relative_xShift ($relative_yShift)
"
echo "$text3" >> $outdrc
outBLKs="$outBLKs MK_OUT$mkNum"
((curCol++))
((mkNum++))
((mapNum++))
done < $coordfile
# output layer
text4="
MK_OUT = OR $outBLKs
MK_OUT {COPY MK_OUT } DRC CHECK MAP MK_OUT 600 199
sq_center = EXTENTS MK_OUT CENTERS 0.010
sq_center {COPY sq_center } DRC CHECK MAP sq_center 600 299
"
echo "$text4" >> $outdrc
# run
sed -i "s#@gdsin@#${gdsin}#g" $outdrc
sed -i "s#@prec@#${outPrec}#g" $outdrc
sed -i "s#@gdsout@#${gdsout}#g" $outdrc
calibre -drc -hier -turbo 16 $outdrc | tee $workpath/temp.log
}
function addLabel() {
local gdsin=$1
local xPitch=$2
local yPitch=$3
local maxCol=$4
local ggCount=$5
local gdsout=$6
tclFile="${workpath}/lable.tcl"
cat > $tclFile << EOF
set layer 99
set datatype 0
set L0 [layout create $gdsin -dt_expand]
set TOPCELL [\$L0 topcell]
\$L0 create layer \$layer.\$datatype
set out_oas $gdsout
set bbox [\$L0 bbox \$TOPCELL]
set x0 [lindex \$bbox 0]
set y0 [lindex \$bbox 1]
set x 0
set y -2.5
set w 10
set h 2
set size 1
set curCol 1
set curRow 1
set ti 0
set xPitch $xPitch
set yPitch $yPitch
set maxCol $maxCol
set r 1
while {\$r <= $ggCount } {
if {\$curCol > \$maxCol} {
incr curRow
set curCol 1
}
set string "+ TK\${r}"
set shiftx [expr {\$curCol*\$xPitch+\$x}]
set shifty [expr {\$curRow*\$yPitch+\$y}]
set st [StringFeature a_\${ti} \$shiftx \$shifty \$w \$h \$size \$string l]
\$st addToLayout \$L0 \$TOPCELL 1 \$layer.\$datatype
incr curCol
incr ti
incr r
}
\$L0 oasisout \$out_oas
EOF
calibredrv -threads 16 $tclFile
}
function gdsName_add2lable() {
local gdsin=$1
tclFile2="${workpath}/lable2.tcl"
cat > $tclFile2 << EOF
set gdsfolder "$gdsin"
set outlayer 99
set outdatatype 0
set cutlength 10
set gdsin [glob -nocomplain -directory \$gdsfolder "*.gds" "*.oas"]
foreach gds \$gdsin {
set gdsName [file rootname [file tail \$gds] ]
set cutName [string range \$gdsName 0 \$cutlength]
set LableName "+ \$cutName"
set Lin [layout create \$gds]
set TOPCELL [\$Lin topcell]
set bbox [\$Lin bbox \$TOPCELL]
set x1 [lindex \$bbox 0]
set y1 [lindex \$bbox 1]
set x2 [lindex \$bbox 2]
set y2 [lindex \$bbox 3]
set prec [layout peek \$gds -precision]
set locx [expr (\$x2/\$prec + 2)]
set locy [expr \$y1/\$prec]
\$Lin create layer \${outlayer}.\${outdatatype}
\$Lin create cell addLabel
set LN [StringFeature ab0 0 0 15 2 1 \$LableName l]
\$LN addToLayout \$Lin addLabel 1 \${outlayer}.\${outdatatype}
\$Lin create ref \$TOPCELL addLabe \${locx}u \${locy}u 0 90 1; # rotate 90
\$Lin oasisout \$gdsfolder/\${gdsName}.oas
}
EOF
calibredrv -threads 16 $tclFile2
}
function outputGG() {
local outgg=$1
local ggCount=$2
rm $outgg
x0=$(echo "$clip_xSize * 0.5" | bc)
y0=$(echo "$clip_ySize * 0.5" | bc)
clipId=1
colNum=1
rowNum=1
while (($clipId <= $ggCount)); do
if (($colNum > $maxColNum)); then
((rowNum++))
colNum=1
fi
x1=$(($colNum * $xPitch))
y1=$(($rowNum * $yPitch))
GX1=`echo $(echo "scale=0;($x1 + $x0 - 0.005)*$outPrec" | bc) | awk -F . '{print $1}'`
GX2=`echo $(echo "scale=0;($x1 + $x0 + 0.005)*$outPrec" | bc) | awk -F . '{print $1}'`
GYY=`echo $(echo "scale=0;($y1 + $y0)*$outPrec" | bc) | awk -F . '{print $1}'`
ggName="TK_${clipId}"
echo "$clipId $ggName 1 1 $GX1 $GYY $GX2 $GYY 0 1 1 1 1 -1 -1 -1 1 -1 -1 -1 NA NA" >> $outgg
((clipId++))
((colNum++))
done
}
function clear_create_folder() {
for ff in $@ ; do
rm $ff -rf
mkdir -p $ff
done
}
function clear_file(){
for ff in $@; do
rm -rf $ff
done
}
headline="
LAYOUT PATH \"@gdsin@\" MAG AUTO
LAYOUT PRIMARY \"*\"
LAYOUT SYSTEM OASIS
LAYOUT MAGNIFY AUTO
PRECISION @prec@
RESOLUTION 1
DRC RESULTS DATABASE \"@gdsout@\" OASIS CBLOCK STRICT TOP
DRC MAXIMUM RESULTS ALL
LAYOUT ERROR ON INPUT YES
DRC MAXIMUM VERTEX 199
DRC KEEP EMPTY NO
FLATTEN VERY SMALL CELLS YES
LAYOUT INPUT EXCEPTION SEVERITY POLYGON_DEGENERATE 1
LAYOUT INPUT EXCEPTION SEVERITY PRECISION_RULE_FILE 1
LAYOUT INPUT EXCEPTION SEVERITY MISSING_REFERENCE 1
LAYOUT ALLOW DUPLICATE CELL YES
LAYOUT ULTRA FLEX YES
LAYOUT WINDOW CLIP YES
"
######## call main at the end ===================================
main "$@"
exit 0
三、开始 Cshell
csh 缺乏函数,局部变量等一些高级特性,但是在芯片及其相关软件应用上(Linux 环境),仍然非常广泛,时常需要用其写一些自动化脚本来执行任务,所以本章也对其做一个较为详细的介绍。
1. 变量声明
#!/bin/csh
#====== 使用 set 声明变量
set enc = "this is a test!"
set ax = 10 # csh 变量赋值只支持整数,不支持小数,需要额外的手段
echo $enc
echo $ax- 关键字,字符,命令,之间需要用空格分隔
2 字符串方法
2.1 字符串运算
字符串拼接:写一块就行
set first = "John" set last = "Doe" #===== 形式 1 set full = "$first $last" #===== 形式 2 set aa = "hhhha"`basename "test.txt" .txt`字符串长度:无内置方法或命令,需要借助外部命令
set str = "hello" set len = `echo -n "$str" | wc -c` # wc -c 统计单字符数量 echo "Length: $len"单词个数:无内置方法或命令,需要借助外部命令
set paths = "/home/test1 /home/test2" set len = `echo $paths | wc -w` # wc -w 以空格为分隔,统计字符串数量子串提取:无内置方法或命令,可借助 linux 命令
awk/cut/sedset ss = "abcdef" set sub = `echo "$ss" | cut -c2-4` # 提取第 2 到第 4 字符 echo $sub # 输出:bcd # 其他方法 1 set sub = `echo -n "$ss" | tail -c 5` # 提取最后五个字符 #方法 2 set sub = `echo $ss | awk '{print substr($0, length($0)-4)}'` #提取最后五个字符字符串替换:无内置方法或命令,借助 linux 命令
awk/cut/sedset var = "/home/ju/test/mingtian_ver_vc01.txt" set name = `basename $var | sed "s#.txt##g"`字符串删除:无内置方法或命令,借助 linux 命令
awk/cut/sedset var = "/home/ju/test/mingtian_ver_vc01.txt" set name = `basename $var .txt | sed "s#.png##g"`
2.2 字符串循环
#!/bin/csh
set chip1 = `ls /test1/*.oas`
set chip2 = `realpath /test2/*.oas`
set chiplist = "$chip1 $chip2"
foreach chip ($chiplist)
echo $chip
end3. 数组与循环
3.1 数组使用
在 csh(C Shell) 中,没有真正意义上的“数组”类型 (不像 bash 有索引数组或关联数组),但 csh 和其增强版 tcsh 支持一种称为“单词列表”(word list)的变量形式,可以 模拟简单的一维字符串数组。
#!/bin/csh
set myarr = ("aa" "bb" "cc")
echo $myarr[1] #index 从 1 开始
echo $#myarr #输出元素个数
foreach el (${myarr})
set out = $el
end多行 的写法:
set aa = (\
test1.txt \
test2.txt \
test3.txt \
)一般来讲,无论是使用双引号,或者是使用括号数组,无法直接定义多行文本。
但是可以 曲线救国,请看下面介绍。
3.2 here-doc 实现多行文本变量
当你定义多行文本的变量时,使用反斜杠太麻烦,不如借助 here-doc 来优雅的实现:
- 借助 cat > << END 先写多行文本到文件
- 然后 cat 读取文件,赋给变量,变量里就按照 空格为分隔符 来分隔每行文本
#!/bin/csh
######################### 【case 1】 ###############
cat > input.txt << END
path/test1
path/test2
END
set input = `cat input.txt`
echo $input
### 输出,以空格分隔每行
path/test1 path/test2
######################## 【case 2】##################
cat > input.txt << END
"this is a test1"
"this is a test2"
END
set input = `cat input.txt`
echo $input
### input 变量输出如下
"this is a test1" "this is a test2" 3.3 循环读取多行文本变量
#!/bin/csh
cat > input.txt << END
"this is a test1"
"this is a test2"
END
######## 错误写法 ##########
set input = `cat input.txt`
foreach txt ($input)
echo $txt #txt 输出以空格为分隔符,把每行的按单词全都打撒了
end注意这里有个坑:
- 使用 foreach 循环读取,默认以 空格为分隔符,所以当每行文本有空格的时候,会把每行的按空格分隔的单词全都打撒了!
- 但是如果每行文本,没有空格,则无需担心这个问题。
空格分隔符解决方案:
如果存在空格,有两种解决方案:建议使用第二种
临时修改脚本分隔符,用完再还原回去
set oldIFS = "$IFS" set IFS = '\n' foreach .... end set IFS = "$oldIFS"引号和 cat 的妙用:必须下面这样写
foreach line ("`cat input.txt`") echo "####$line####" end ## 输出 ####"this is a test1"#### ####"this is a test2"#### ############################ 错误写法 ######### set input = "`cat input.txt`" foreach line ("$input") echo "####$line####" end ## 输出 ####"this is a test1" "this is a test2"####
3.4 字符串转数组
set my_friuts = "apple banana cherry"
set my_array = ($my_friuts)4. 环境配置与别名声明
一般 csh 的默认配置文件为:~/.cshrc,可以在里面配置一些环境。
setenv PATH /home/user1/install/ #配置环境变量
alias .. "cd .." #别名(快捷命令)
alias python "/home/user1/install/python3.10"5. 逻辑判断与循环语句
5.1 if 判断
#!/bin/csh
set num = 5
if ($num == 1) then
echo "Number is 1"
else if ($num == 2) then
echo "Number is 2"
else if ($num == 3) then
echo "Number is 3"
else
echo "Number is not 1, 2, or 3"
endif5.2 循环语句
#!/bin/csh
###======== foreach --> 默认以空格为分隔符
set myarr = ("aa" "bb" "cc")
foreach el (${myarr})
set out = $el
end
foreach folder (test1 test2 test3)
if (! -d $folder) then
mkdir -p $folder
endif
end
###======= while
set sum = 0
set i = 1
while ($i <= 5)
set sum = `expr $sum + $i`
set i = `expr $i + 1`
end
echo "Sum is $sum"
###=========switch
switch ($sum)
case 1:
# commands
breaksw
case 2:
#commands
default:
breaksw
endsw想其他语言一样,csh 的循环体同样支持 break 和continue:
- break:跳出终止当前循环
- continue:跳过本次循环剩余部分,开始下一次循环迭代
6. 写文件
写文件也叫数据重定向,使用尖括号> filePath
#!/bin/csh
#====== 单行重定向
echo "this is a test" > tt.log
#====== 多行重定向
set words = ("test1" "test2" "test3")
cat > tt.log << END
this is a $words[1]
this is a $words[2]
this is a $words[3]
END- 也可以参照 bash 相关用法
7 数据运算与条件判断
7.1 数据运算
数据分为:数字,字符串。下面分别介绍数字运算和字符串处理方法
7.1.1 原生算数表达式
@ c = $a + $b
@ d = $c * 2
@ e = $d / 3
@ f = $d % 4- 支持的运算符:
+,-,*,/,%,+=,-=,++,-- - 不支持括号嵌套复杂表达式(如
@ x = ($a + $b) * 2会报错) - 所有操作必须在
@行内完成,不能直接在set中做算术
举例:
#!/bin/csh
set x = 7
set y = 3
@ sum = $x + $y
echo "Sum is $sum"7.1.2 扩展算数
借助 外部工具,还可以采用其他的方式:
- expr 命令,整数运算
- bc 命令,小数计算
- awk 命令,实数运算
#==== expr 命令,整数运算
set sum = `expr $a + $b`
set product = `expr $a \* $b`
#==== bc 命令,小数计算
set result = `echo "scale=2;10/3" | bc` #scale=2 保留两位小数
echo $result
# ==== awk 命令,实数运算
set pi = `awk 'BEGIN {print 22/7}'`
echo "Approx pi = $pi" #输出:3.142867.2 数值字符串判断
#===== 数值判断
set x = 10
if ($x > 5) then
echo "x is greater than 5"
endif
#===== 字符串判断
set name = "Alice"
if ("$name" == "Alice") then
echo "Hello, Alice!"
else
echo "Who are you?"
endif数值支持:==、!=、<、<=、>、>=
字符串支持:==、!=
7.3 文件判断
使用 csh 可以直接对文件或者路径进行判断:
#!/bin/csh
# 定义文件名
set filename = "test.txt"
#===== 判断文件是否存在
if (-e $filename) then
echo "$filename 存在 "
else
echo "$filename 不存在 "
endif文件 / 文件夹判断方法总结如下:
| 表达式 | 含义 |
|---|---|
-r file |
文件存在且可读 |
-w file |
文件存在且可写 |
-x file |
文件存在且可执行 |
-e file |
文件存在(任何类型) |
-f file |
文件存在且是普通文件 |
-d file |
文件存在且是目录 |
-c file |
字符设备文件 |
-b file |
块设备文件 |
-p file |
命名管道(FIFO) |
-l file |
符号链接(部分实现支持) |
-u file |
设置了 setuid 位 |
-g file |
设置了 setgid 位 |
-s file |
文件存在且非空(size > 0) |
7.3 逻辑运算
| 运算符 | 含义 | 示例 |
|---|---|---|
| && | 逻辑与(AND) | if ($a > 0 && -f "$file") then |
| || | 逻辑或(OR) | if ($a > 0 || -f "$file") then |
| ! | 逻辑非(NOT) | if (! -e "$tmp") then |
必要时用括号明确顺序(但注意 csh 对复杂嵌套括号支持有限):
if (($a == 1 || $a == 2) && (-f "data$a.txt")) then
...
endif8 案例
8.1 一直跑直到完成
#!/bin/csh
set chip1 = "t1.oas t2.oas t3.oas"
set chip2 = `ls /test/*.oas`
set chips = "$chip1 $chip2"
set all_jobs = `echo $chips | wc -w `
set count_job = 0
while (1)
if ($count_job >= $all_jobs) then
break
endif
foreach chip ($chips)
set log = "xxx.log"
set res = "xxx.oas"
if ((-r $log) && (-r $res)) then
set has_done = `cat $log | tail -3 | grep "yyy finished" | wc -l`
if ("$has_done" == "1") then
@ count_job = $count_job + 1
continue
endif
endif
#构造命令,执行命令
cp $template drcout/xxx.job
sed -i "s#@gdsin@#${chip}" drcout/xxx.job
sed -i "s#@gdsout@#${outpath}" drcout/xxx.job
#....
end
end欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net