官方中文文档:https://www.numpy.org.cn/user/
这里使用 jupyter notebook 进行演示。
安装:pip install jupyter
启动:jupyter notebook
1. 数组的创建
1.1 类型转变
从列表:
从元祖:
从字符串:
1.2 从头创建
1.2.1 一维数组
按顺序生成:
使用 np.random 模块可随机生成
按等间距生成:
生成全为“1”数组:
生成全为“0”数组:
对角线全为“1”数组:
注意:默认生成浮点型数值,可在括号里加参数dtype=int,使得生成整型数值。
归纳为以下:
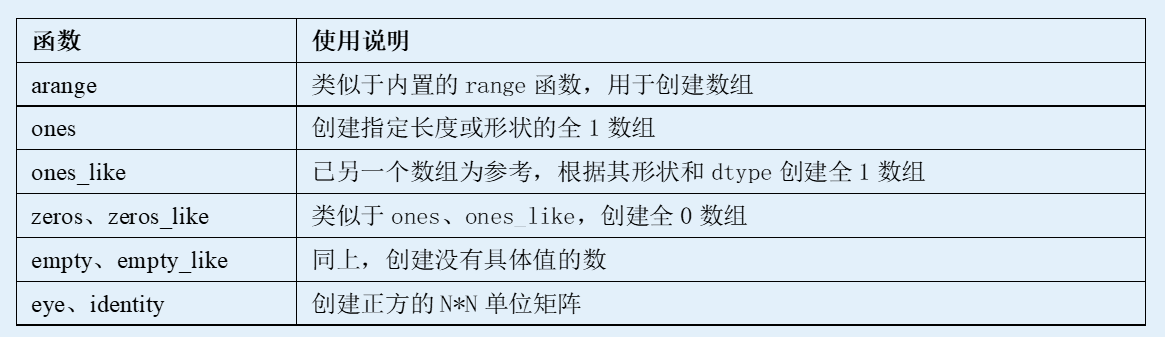
1.2.2 多维数组
.reshape()的使用:
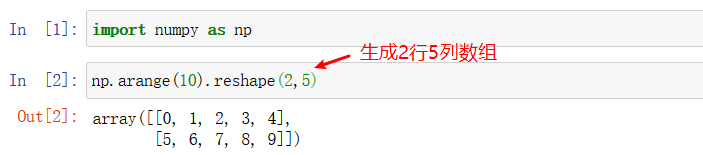
使用 .reshape() 方法可将 n 维数组变成任意指定形状的数组,但是元素个数要对的上。
将 n 维数组变成一维:
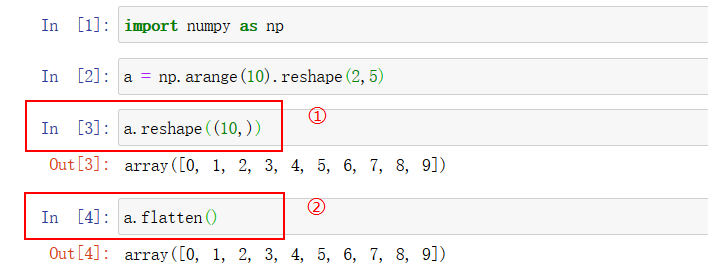
将一维行数据数据变成列数据:
>>> s=np.arange(5)
array([0, 1, 2, 3, 4])
>>> s.reshape(5,1)
array([[0],
[1],
[2],
[3],
[4]]).reshape()和 .resize() 区别:前者不改变原形状,后者改变。
.flatten()和 .ravel() 区别:执行命令后再进行赋值操作,前者不改变元素,后者改变(此用法不多)。
size()的使用:

1.2.3 np.random 模块
| 方法 | 使用说明 |
|---|---|
np.random.random((m,n)) |
随机生成 (0,1) 之间的数组,m 行 n 列 |
np.random.rand(m,n) |
随机生成 [0,1)之间的数组,m 行 n 列 |
np.random.randint(x,y,size=(m,n)) |
随机生成整型数组,数字 (x,y) 之间,m 行 n 列 |
np.random.uniform(x,y,size=(m,n)) |
随机生成浮点数组,数字 [x,y) 之间,m 行 n 列 |
np.random.choice(data) |
随机采样生成数组,从 data 中 |
np.random.shuffle(data) |
随机按行打乱数组,从 data 中,改变原数组 |
np.random.permutation(data) |
随机按行打乱数组,从 data 中,不改原数组 |
np.random.seed() |
调控随机数的生成,根据种子值 |
np.random.randn(m,n) |
随机生成标准正态分布数组,符合 N(0,1) |
np.random.normal(μ,σ,size=(m,n)) |
随机生成正态分布数组,符合 N(μ,σ) |
np.random.poisson(lam,size=(m,n)) |
随机生成泊松分布数组,事件发生率 lam |
以上均可很据括号里传入维度的不同,可以创建 1~N 维数组。
1.3 数组属性
| 属性 | 使用说明 |
|---|---|
.ndim |
秩,即数据轴的个数 |
.shape |
数组的维度 |
.size |
元素的总个数 |
.dtype |
数据类型 |
.itemsize |
数组中每个元素的字节大小 |
.T |
数组的转置,即行列进行交换 / .transpose作用一样,但它会改变原数组 |
使用以上方法不需要加括号。
举一个例子:
2. 数组的操作
2.1 索引
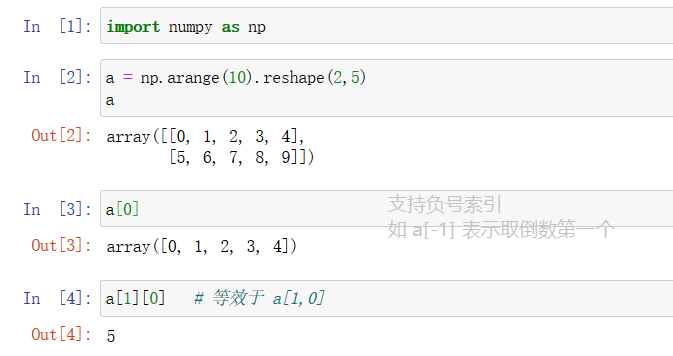
2.1.1 普通索引
位置索引:
布尔索引:

2.1.2 花哨索引
选取数据:

选择块:
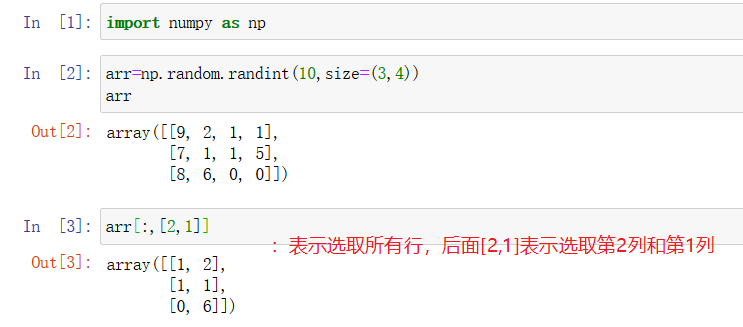

调换行:

2.2 切片
连续的切片:
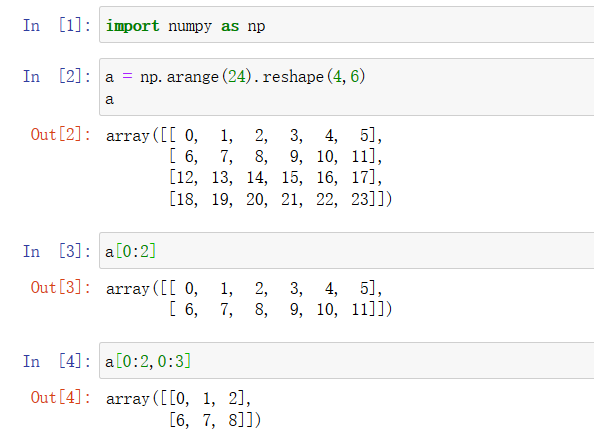
不连续的切片:

2.3 值的替换
根据索引赋值
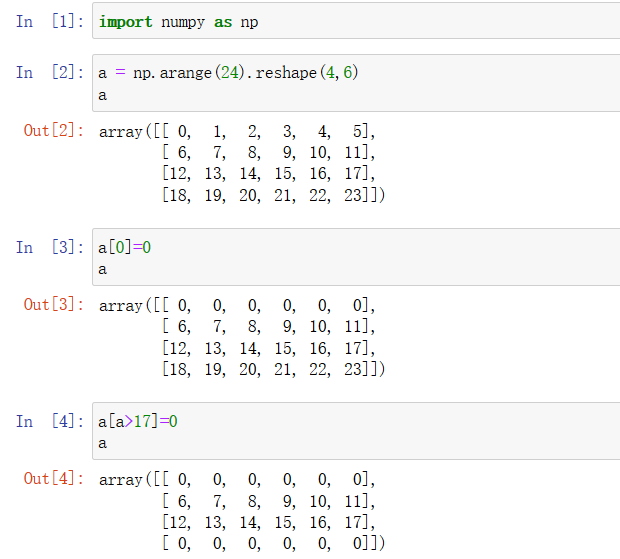
2.4 数组拼接

2.5 数组切割
2.5.1 普通切割

2.5.2 复杂切割

2.6 数组运算
2.6.1 通用函数


注意:这里的逻辑运算如逻辑与 np.logical_and()是进行多元运算的。括号里传入的数组必须形状相同。

NAN 安全版本:为了应对数组里的缺失值 np.nan 的。如下:

2.6.2 布尔数组函数

对传入的数组进行是否有空值判断。传入的数组也可以为布尔数组。只能进行一元判断。
2.7 数组排序
2.7.1 普通排序

如要 降序 排列,只需传入负号即可:np.sort(-arr)。
2.7.2 排序并返回唯一值

对传入的数组中的元素排序,并返回对应元素出现的个数。
2.8 数组广播机制
如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符或其中一方的长度为 1,则认为他们是广播兼容的。广播会在缺失和(或)长度为 1 的维度上进行。
举例说明:
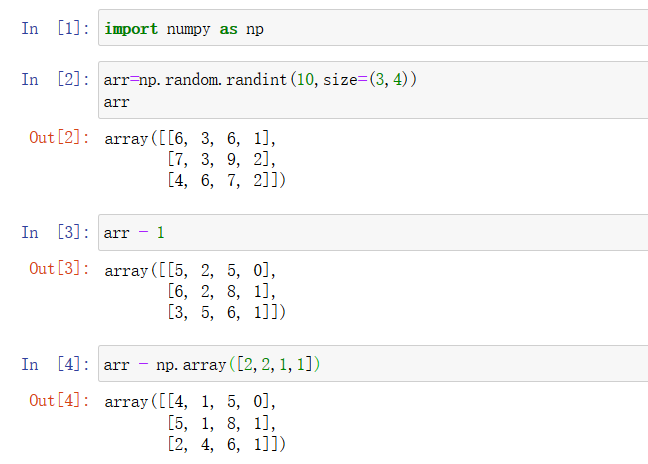
3. 文件操作
3.1 文件保存
np.savetxt(frame, array, fmt='%.18e', delimiter=None)- frame : 文件、字符串或产生器,可以是.gz 或.bz2 的压缩文件 如 “example.csv”
- array : 存入文件的数组
- fmt : 写入文件的格式,例如:%d %.2f %.18e 可以省略
- delimiter : 分割字符串,默认是任何空格 根据需要是否要指定
3.2 读取文件
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)- frame:文件、字符串或产生器,可以是.gz 或.bz2 的压缩文件。
- dtype:数据类型,可选。
- delimiter:分割字符串,默认是任何空格。
- skiprows:跳过前面 x 行。
- usecols:读取指定的列,用元组组合。
- unpack:如果 True,读取出来的数组是转置后的。
保存和读取文件举例:
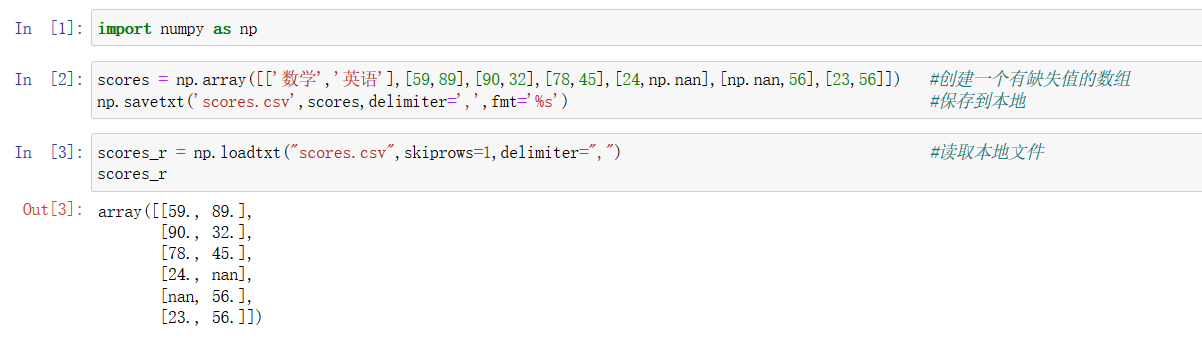
注意这里的 skiprows=1 的意思是忽略第一行数据。
3.3 numpy 独有存储格式
- 存储:
np.save('fname.np',array)或np.savez('fname.npz',array)。后者fname.npz是经过压缩的。 - 加载:
np.load(fname)。
4. 补充知识点
4.1 Axis 理解
方便大家理解,可以认为 axis=0 代表的是行 ,axis=1 代表的是列 。但其实不是这么简单理解的。这里具体解释一下这个axis 轴的概念。
简单来说, 最外面的括号代表着 axis=0,依次往里的括号对应的 axis 的计数就依次加 1:

操作方式:如果指定轴进行相关的操作,那么他会使用轴下的每个直接子元素的第 0 个,第 1 个,第 2 个…分别进行相关的操作。
二维的数组求和:
>>>x = np.array([[0,1],
[2,3]])
>>>x.sum(axis=0)
array([2, 4])
>>>x.sum(axis=1)
array([1, 5])按照 axis=0 的方式进行相加,那么就会把最外面轴下的所有直接子元素中的第 0 个位置 x[0][0] 与x[1][0]
进行相加,第 1 个位置 x[0][1] 与x[1][1]进行相加…依此类推。
按照 axis=1 的方式进行相加,那么就会把轴为 1 里面的元素拿出来进行求和,x[0][0]与 x[0][1] 进行相加,x[1][0]与 x[1][1] 进行相加…依此类推。
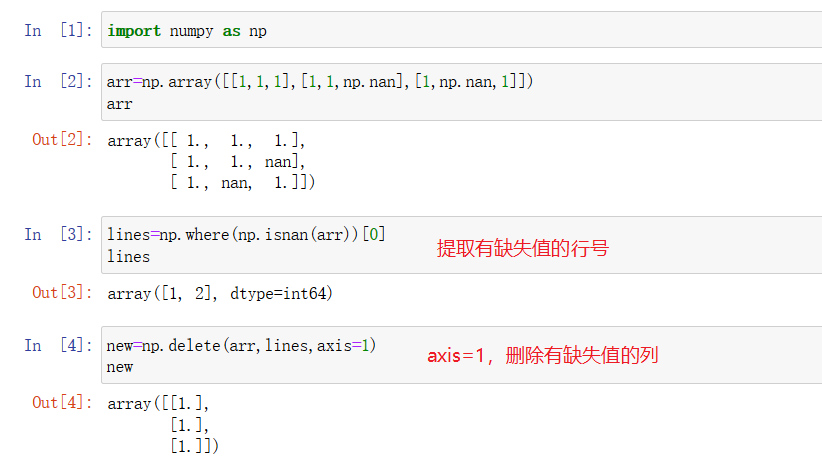
用 np.delete 在axis=0和 axis=1 两种情况下删除元素:
>>>x = np.random.randint(0,10,size=(3,5))
>>> np.delete(x,0,axis=0)
array([[0, 4, 2, 5, 2],
[2, 2, 1, 0, 8]]) #删除了行np.delete是个例外。我们按照 axis=0 的方式进行删除,那么他会首先找到最外面的括号下的直接子元素中的第 0 个,然后删掉,剩下最后一行的数据。
三维数组:
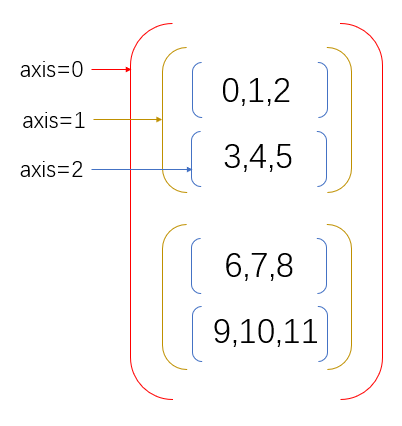
按照 axis=0 的方式进行相加:
按照 axis=1 的方式进行相加:
4.2 NAN 和 INF 值处理
意义解释:
NAN:Not A number,不是一个数字的意思,但是他是属于浮点类型的,所以想要进行数据操作的时候需要注意他的类型。INF:Infinity,代表的是无穷大的意思,也是属于浮点类型。np.inf表示正无穷大,-np.inf表示负无穷大,一般在出现除数为 0 的时候为无穷大。比如2/0
特点:
- NAN 和 NAN 不相等。比如
np.NAN != np.NAN这个条件是成立的。 - NAN 和任何值做运算,结果都是 NAN。
删除缺失值:
替换缺失值:

打开表格 scores.csv 可看到如下表格:
| 数学 | 英语 |
|---|---|
| 59 | 89 |
| 90 | 32 |
| 78 | 45 |
| 34 | nan |
| nan | 56 |
| 23 | 56 |
替换缺失值为 0:

4.3 深浅拷贝
在操作数组的时候,它们的数据有时候拷贝进一个新的数组,有时候又不是。这经常是初学者感到困惑。下面有三种情况:
不拷贝:
如果只是 简单的赋值,那么不会进行拷贝。示例代码如下:
a = np.arange(12)
b = a #这种情况不会进行拷贝
print(b is a) #返回 True,说明 b 和 a 是相同的View 或者浅拷贝:
有些情况,会进行 变量的拷贝 ,但是他们所 指向的内存空间都是一样的,那么这种情况叫做浅拷贝,或者叫做View(视图)。比如以下代码:
a = np.arange(12)
c = a.view()
print(c is a) #返回 False,说明 c 和 a 是两个不同的变量
c[0] = 100
print(a[0]) #打印 100,说明对 c 上的改变,会影响 a 上面的值,说明他们指向的内存空间还是一样的,这种叫做浅拷贝,或者说是 view深拷贝:
将之前数据 完完整整的拷贝一份放到另外一块内存空间中,这样就是两个完全不同的值了。示例代码如下:
a = np.arange(12)
d = a.copy()
print(d is a) #返回 False,说明 d 和 a 是两个不同的变量
d[0] = 100
print(a[0]) #打印 0,说明 d 和 a 指向的内存空间完全不同了。图例说明:
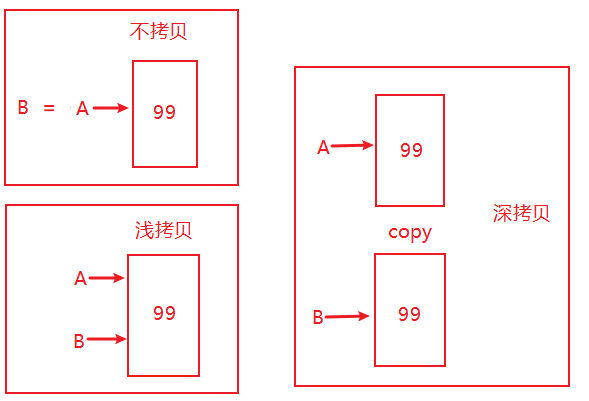
像之前讲到的 flatten 和ravel就是这种情况,ravel返回的就是 View,而 flatten 返回的就是深拷贝。
5. Numpy 实际应用
5.1 图像处理
以下简单举例 Numpy 数组在图像处理领域的应用:
读取图片并将其转化成数组数据:
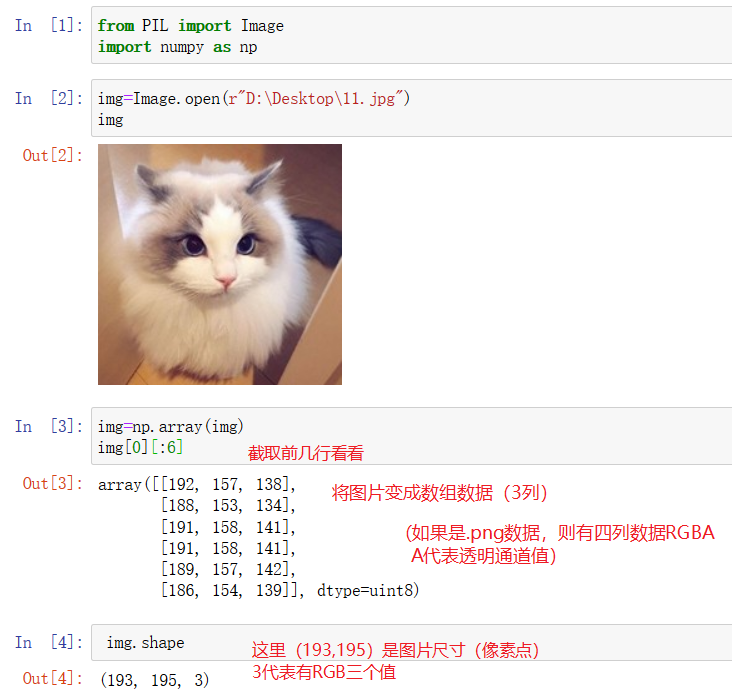
处理数组数据并还原成图片:
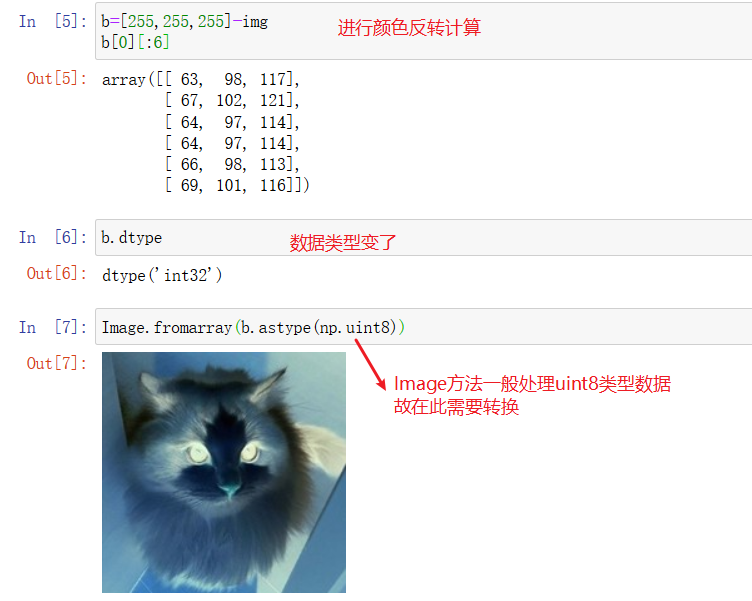
图像处理库 Pillow(PIL)更多用法参考:https://www.cnblogs.com/yhjoker/p/10773444.html
官方文档:https://pillow.readthedocs.io/en/stable/index.html
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net