1、爬虫简介
1.1 爬虫分类
1.1.1 通用爬虫
通用网络爬虫是捜索引擎抓取系统(Baidu、Google、Sogou 等)的一个重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。为搜索引擎提供搜索支持。主要是提供检索服务,网站排名。
搜索引擎去成千上万个网站抓取数据。抓取的是整个网页,不是具体详细的信息。无法提供针对具体某个客户需求的搜索结果

1.1.2 聚焦爬虫
聚焦爬虫,是”面向特定主题需求”的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页数据。
后续探讨的是 聚焦爬虫。
1.2 Robots 协议
robots 是网站跟爬虫间的协议,用简单直接的 txt 格式文本方式告诉对应的爬虫被允许的权限,也就是说 robots.txt 是搜索引擎中访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在 robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
Robots 协议也叫爬虫协议、机器人协议等,全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过 Robots 协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
怎么看 robots 协议:网站主域名 +robots.txt
如:淘宝:https://www.taobao.com/robots.txt
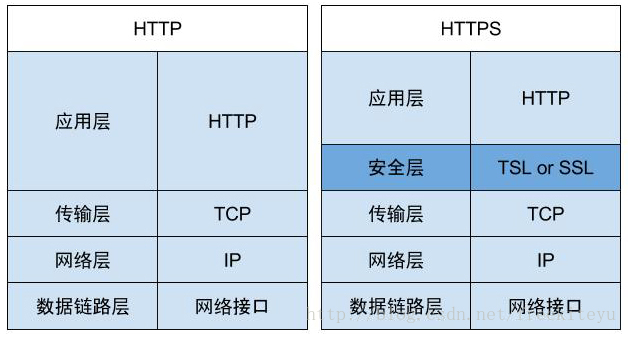
1.3 HTTP 协议
- HTTP 协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML 页面的方法。
- HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是 HTTP 的安全版,在 HTTP 下加入 SSL 层。
1.3.1 请求与响应

- 当我们在浏览器输入 URL 的时候,浏览器发送一个 Request 请求去获取目标 URL 的 html 文件,服务器把 Response 返回文件对象发送回给浏览器。
- 浏览器分析 Response 中的 HTML,发现其中引用了很多其他文件,比如 Images 文件,CSS 文件,JS 文件。 浏览器会自动再次发送 Request 去获取图片,CSS 文件,或者 JS 文件。
- 当所有的文件都下载成功后,网页会根据 HTML 语法结构,完整的显示出来了。
1.3.2 URL 请求
URL 又叫作 统一资源定位符,是用于完整地描述 Internet 上网页和其他资源的地址的一种方法。类似于 Windows 的文件路径。
http://: 这个是协议,也就是 HTTP 超文本传输协议,也就是网页在网上传输的协议。
mail:这个是服务器名,代表着是一个邮箱服务器,所以是 mail。
163.com: 这个是域名,是用来定位网站的独一无二的名字。
mail.163.com: 这个是网站名,由服务器名 + 域名组成。
/: 这个是根目录,也就是说,通过网站名找到服务器,然后在服务器存放网页的根目录。
index.html: 这个是根目录下的网页。
http://mail.163.com/index.html 这个叫做 URL,统一资源定位符,全球性地址,用于定位网上的资源。
请求方法:
最主要分两种:
get请求:一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求。post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用post请求。
1.4 关于编码
ASCII 码:处理英文字符而发明的
GB2312:为了处理中文字符发明的
GBK:中文拓展库,加入繁体,亚裔文字编码。
Unicode:万国码,包含世界范围的语言编码
UTF-8:为了提高 Unicode 存储和传输性能。
2、requests 请求
- Requests 模块就是 Python 实现的简单易用的 HTTP 库
还有其他库例如 urllib,urllib2 等模块。但是目前来说 Requests 模块是最流行的。而且也是做好用的模块。
requests 库的安装
pip install requests2.1 GET 请求
请求获取数据:
response = requests.get(url,*karaws)requests.get 中包含的方法:
| method | 含义 |
|---|---|
| url | 指定 Request 对象的 URL |
| params(可选) | 指定 Request 对象的查询字符串,可以是字典(Dict)或者字节数组(Bytes) |
| headers(可选) | 指定 Request 对象的 HTTP 头部内容,是以字典(Dict)的形式 |
| proxies(可选) | 指定代理网址,是以字典(Dict)的形式 |
| timeout(可选) | 指定等待服务器响应的超时时间,可以是整形、浮点型,也可以是一个元组 (t1, t2),如果是元组,那么 t1 表示连接超时,t2 表示读取超时 |
| cookies(可选) | 指定 Request 对象的 cookies 内容,可以是字典(Dict)或者 CookieJar 对象 |
| data(可选) | 指定 Request 对象的 body 内容,可以是字典(Dict)、包含元组的列表 [(key, value)]、字节数组(Bytes)或者类文件对象 |
| json(可选) | 指定 Request 对象的 body 内容,是以 JSON 格式的形式 |
| files(可选) | 以字典的形式上传多部分编码文件({‘name’: file-like-objects} 或 {‘name’: file-tuple}),其中的 file-tuple 可以是一个 2 元组 (‘filename’, fileobj),也可以是一个 3 元组 (‘filename’, fileobj, ‘content_type’),还可以是一个 4 元组 (‘filename’, fileobj, ‘content_type’, custom_headers)。注:’content-type’ 是由一个字符串来描述上传的文件类型;custom_headers 是一个类似字典的对象,包含额外的 header 信息 |
| auth(可选) | 启用 Basic(基础)或 Digest(摘要式)或 Custom(自定义)的 HTTP 认证 |
| allow_redirects(可选) | 是否允许重定向,Enable(启用)或 disable(禁用)GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD 的重定向,默认值是 True |
| cert(可选) | 如果是字符串,那么是 ssl 客户端证书(.pem)的路径;如果是元组,那么是一个 (‘cert’, ‘key’) 的键值对 |
| verify(可选) | 可以是一个布尔类型的值,表示是否验证服务器的 TLS 证书;也可以是一个字符串,包含一个 CA 证书的路径。默认值是 True |
| stream(可选) | 是否允许流式传输数据(大视频),如果为 False,响应内容会立即下载 |
2.1.1 传递 URL 参数
给 URL 的查询字符串 (query string) 传递某种数据。如果你是手工构建 URL,也就是通过拼接字符串构造的 URL。那么数据会以键 / 值对的形式置于 URL 中,跟在一个问号的后面。
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
response = requests.get("http://httpbin.org/get", params=payload)
print(response.url)
# 结果如下:
http://httpbin.org/get?key2=value2&key1=value12.1.2 传递请求头
为了将爬虫伪装成浏览器访问,以躲过目标网站的屏蔽,可以给爬虫添加请求头信息。
header={
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
response=requests.get(url, headers=header)2.1.3 传递代理 ip
有时候仅仅传递请求头并不能躲避目标网站的封锁,这时候可以再加代理 ip,搭建代理 ip 池,实现匿名访问。
ipset=['134.209.13.16:8080','134.203.13.14:8080']
response=requests.get(url, proxies={'http':random.choice(ipset)})
2.1.4 response 返回
print(response) // 打印状态码 r.status_code 也可以
print(response.text) // 打印返回的文本信息
print(response.content) // 打印返回的二进制信息,用于图片,视频,音频等
print(response.encoding) // 打印网页的编码信息
print(response.json()) // 打印 json 解码的 response 对象
print(response.url) // 打印网页的请求 url
print(response.apparent_encoding) // 返回网页的编码信息除了一些常用的,还包括一下这些内容:
In [5]: response.
apparent_encoding cookies history
iter_lines ok close
elapsed is_permanent_redirect json
raise_for_status connection encoding
is_redirect links raw
content headers iter_content
next reason url
.....2.1.5 文本乱码
添加解码信息
添加一行
response.encoding='utf-8'万能解码
response.encoding = response.apparent_encoding2.2 POST 请求
POST 请求主要用来提交表单数据,然后服务器根据表单数据进行分析,再决定返回什么样的数据给客户端。
response=requests.post(url, data=formdata, headers=headers,*karaws)post 请求除了要传递目标 url 以外,还需要传递表单数据给 data。
如:
headers = {
'Cookie': cookies_str,
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
# post 的表单数据
formdata = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
# 提交数据
response = requests.post(url, data=formdata, headers=headers)
# 查看数据
print(response.json())2.3 HTTP 响应报文
HTTP 响应报文也由三部分组成:响应行、响应头、响应体。
这里主要说说常见的状态码
总结如下:
凡是以 2 开头的状态码 都是成功
凡是以 4 开有的状态码 都是客户端的问题(请求不存在的内容)
凡是以 5 开头的状态吗 都是服务器的问题 如果发送了一个错误请求 (一个 4XX 客户端错误,或者 5XX 服务器错误响应),我们可以通过 response.raise_for_status() 来抛出异常。
100~199:表示成功接收请求,要求客户端继续提交下一次请求才能完成整个处理过程。
200~299:表示成功接收请求并已完成整个处理过程。常用 200
300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用 302(意味着你请求我,我让你去找别人),307 和 304(我不给你这个资源,自己拿缓存)
400~499:客户端的请求有错误,常用 404(意味着你请求的资源在 web 服务器中没有)403(服务器拒绝访问,权限不够)
500~599:服务器端出现错误,常用 500
2.4 重定向
重定向 (Redirect) 就是通过各种方法将一个网络请求重新定个方向转到其它位置。可能的原因是有些网址现在已经废弃不准备再使用等。
如果你使用的是 GET、POST 等,那么你可以通过 allow_redirects 参数禁用重定向处理:
r = requests.get(url, allow_redirects=False)欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net