1、过滤器
过滤器 (Filter) 是处于客户端与服务器资源文件之间的一道过滤网,在访问资源文件之前,通过一系列的过滤器对请求进行修改、判断等,把不符合规则的请求在中途拦截或修改。也可以对响应进行过滤,拦截或修改响应。
过滤器主要用于增量式爬虫中,所谓增量式爬虫并不是新型的爬虫架构,而是根据项目需求而产生的一种爬虫类型。例如我们想爬取智联的职位信息,可是我们只想爬取每天更新的职位信息,不想全部都爬取,这就需要增量式爬虫。增量式爬虫的核心在于快速去重,我们必须判断哪些是已经爬取过的,哪些是新产生的。
1.1 去重方案
对于爬虫来说,由于网络间的链接错综复杂,爬虫在网络间爬行很可能会形成“环”,这对爬虫来说是非常可怕的事情,会一直做无用功。为了避免形成“环”,就需要知道 Spider 已经访问过哪些 URL,基本上有如下几种方案。
1.1.1 关系型数据库去重
关系型数据库去重,需要将 URL 存入到数据库中,每来一个 URL 就启动一次数据库查询,数据量变得非常庞大后关系型数据库查询的效率会变得很低,不推荐。
1.1.2 缓存数据库去重
缓存数据库,比如现在比较流行的 Redis,去重方式是使用其中的 Set 数据类型,类似于 Python 中的 Set,也是一种内存去重方式,但是它可以将内存中的数据持久化到硬盘中,应用非常广泛,推荐。
1.1.3 内存去重
内存去重方案,可以细分出三种不同的实现方式:
- 将 URL 直接存储到 HashSet 中,也就是 Python 中的 Set 数据结构中,但是这种方式最明显的缺点是太消耗内存。随着 URL 的增多,占用的内存会越来越多。大家可以计算一下假如存储了 1 亿个链接,每个链接平均 40 个字符,这就占用了 4G 内存。
- 将 URL 经过 MD5 或者 SHA-1 等单向哈希算法生成摘要,再存储到 HashSet 中。由于字符串经过 MD5 处理后的信息摘要长度只有 128 位,SHA-1 处理后也只有 160 位,所以占用的内存将比第一种方式小很多倍。
- 采用 Bit-Map 方法,建立一个 BitSet,将每个 URL 经过一个哈希函数映射到某一位。这种方式消耗内存是最少,但缺点是单一哈希函数发生冲突的概率太高,极易发生误判。
1.2 Scrapy 默认去重
scrapy 默认是进行 url 去重,scrapy 内部默认也提供了一个去重方案,位于scrapy.dupefilters.RFPDupeFilter, 具体逻辑如下
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
...
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
def request_fingerprint(self, request):
return request_fingerprint(request)由类里面的 request_seen 实现去重的逻辑,具体的逻辑被封装在 request_fingerprint(request 指纹) 方法里面。
继续查看源代码,可以了解到 Scrapy 是根据 request_fingerprint 方法实现过滤的,将 Request 指纹添加到 set()中。部分源码如下:
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]从代码中我们可以看到,去重指纹为 sha1(method+url+body+header),对这个整体进行去重,去重比例太小。
scrapy 自带过滤器的缺点:
- 存储在本机的内存里面(set)
- 没有数据持久化,重启爬虫之后,数据都没了
- 存储的是 url 的指纹,一旦请求的 url 很多,去重数据就会变得非常大。
1.3 修改过滤器
下面我们根据 URL 进行去重,定制过滤器。代码如下:
from scrapy.dupefilter import RFPDupeFilter
class URLFilter(RFPDupeFilter):
""" 根据 URL 过滤 """
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.urls_seen = set()
def request_seen(self, request):
if request.url in self.urls_seen:
return True
else:
self.urls_seen.add(request.url)但是这样依旧不是很好,因为 URL 有时候会很长导致内存上升,我们可以将 URL 经过 sha1 操作之后再去重,改进如下:
from scrapy.dupefilter import RFPDupeFilter
from w3lib.util.url import canonicalize_url
class URLSha1Filter(RFPDupeFilter):
""" 根据 urlsha1 过滤 """
def __init__(self, path=None):
self.urls_seen = set()
super().__init__(self, path)
def request_seen(self, request):
fp = hashlib.sha1()
fp.update(canonicalize_url(request.url))
url_sha1 = fp.hexdigest()
if url_sha1 in self.urls_seen:
return True
else:
self.urls_seen.add(url_sha1)2、布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
特点:布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势;空间效率和查询时间都远远超过一般的 算法,布隆过滤器存储空间和插入 / 查询时间都是常数 O(k)。
2.1 介绍及原理
前置需求
- 需求
- 已经有 50 亿个电话号码,现在给出 10 万个电话号码,如何快速准确地判断这些电话号码是否已经存在?
- 参考方案
- 通过数据库查询:比如 MySQL,性能不行,速度太慢
- 将数据先放进内存:50 亿 *8 字节 =40GB,内存占用太大
- hyperloglog 算法:准确度不行
- 现实类似问题
- 垃圾邮件判断
- 文字处理软件的错误单词检测
- 网络爬虫的 url 去重
- 解决方法
- 使用布隆过滤器
布隆过滤器介绍以及原理
布隆过滤器作用
- 占用很少的空间和使用较少的时间判断一个小数据集是否是一个大数据集的子集
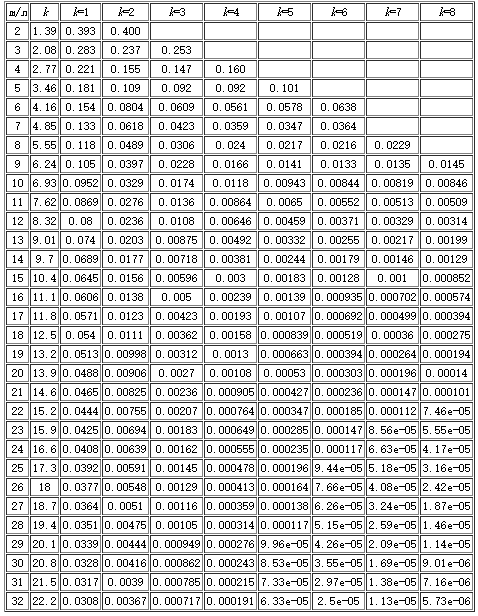
布隆过滤器参数
- n:一个很长的二进制,n 位
- m:需要放入的数据数量,m 个
- k:k 个哈希函数
布隆过滤器构建过程
初始化:原始二进制数字中的每一位都置为 0
一个数据经过 1 个哈希函数会得到一个位置,该位置置 1
一个数据经过 k 个哈希函数处理会,在原理二进制中会有 k 个位置被置 1
所有数据重复以上两步,即可构建出对于这个数据集的布隆过滤器
布隆过滤器判断有无
- 一个数据经过 k 个哈希函数处理,查看得到的位置是否都为 1,如果有至少一个位置不为 1,则证明这个数据不在数据集中,反之,这个数据很大可能在这个数据集中(因为存在误差)
布隆过滤器的误差
误差可能存在
- 一个数据并未参数构建布隆过滤器,但是它的计算结果可能会“已经存在”,比如当只用 1 个哈希函数或者二进制数很短时,可能别的数据的结果刚好与整个数据相同,于是这个数据也被当做存在了
- 已有的数据一定显示已有,未有数据可能”已有“
误差计算

误差率统计
布隆过滤器的实现
- 由 Go 和 redis 组合实现一个布隆过滤器
- 底层数据结构
- redis 中衍生数据类型很适合作为实现布隆过滤器的底层数据类型
- 实现方法
- 布隆过滤器的构造参数:插入数量 m,哈希函数个数 k
- 布隆过滤器的操作函数:Add,Contains,Probability
- 封装 redis 位图操作
- 总体代码
- 样例测试
2.2 对接 Scrapy
实现 Bloom Filter 时,Bloom Filter 的实现需要借助于一个位数组,既然当前架构依赖于 Redis,那么位数组的维护直接使用 Redis 就好了。
首先实现一个基本的散列算法,将一个值经过散列运算后映射到一个 m 位数组的某一位上,代码如下:
class HashMap(object):
def __init__(self, m, seed):
self.m = m
self.seed = seed
def hash(self, value):
"""
Hash Algorithm
:param value: Value
:return: Hash Value
"""
ret = 0
for i in range(len(value)):
ret += self.seed * ret + ord(value[i])
return (self.m - 1) & ret这里新建了一个 HashMap 类。构造函数传入两个值,一个是 m 位数组的位数,另一个是种子值seed。不同的散列函数需要有不同的seed,这样可以保证不同的散列函数的结果不会碰撞。
在 hash() 方法的实现中,value是要被处理的内容。这里遍历了 value 的每一位,并利用 ord() 方法取到每一位的 ASCII 码值,然后混淆 seed 进行迭代求和运算,最终得到一个数值。这个数值的结果就由 value 和seed唯一确定。我们再将这个数值和 m 进行按位与运算,即可获取到 m 位数组的映射结果,这样就实现了一个由字符串和 seed 来确定的散列函数。当 m 固定时,只要 seed 值相同,散列函数就是相同的,相同的 value 必然会映射到相同的位置。所以如果想要构造几个不同的散列函数,只需要改变其 seed 就好了。以上内容便是一个简易的散列函数的实现。
接下来我们再实现 Bloom Filter。Bloom Filter 里面需要用到 k 个散列函数,这里要对这几个散列函数指定相同的 m 值和不同的 seed 值,构造如下:
BLOOMFILTER_HASH_NUMBER = 6
BLOOMFILTER_BIT = 30
class BloomFilter(object):
def __init__(self, server, key, bit=BLOOMFILTER_BIT, hash_number=BLOOMFILTER_HASH_NUMBER):
"""
Initialize BloomFilter
:param server: Redis Server
:param key: BloomFilter Key
:param bit: m = 2 ^ bit
:param hash_number: the number of hash function
"""
# default to 1 << 30 = 10,7374,1824 = 2^30 = 128MB, max filter 2^30/hash_number = 1,7895,6970 fingerprints
self.m = 1 << bit
self.seeds = range(hash_number)
self.maps = [HashMap(self.m, seed) for seed in self.seeds]
self.server = server
self.key = key由于我们需要亿级别的数据的去重,即前文介绍的算法中的 n 为 1 亿以上,散列函数的个数 k 大约取 10 左右的量级。而 m>kn,这里 m 值大约保底在 10 亿,由于这个数值比较大,所以这里用移位操作来实现,传入位数 bit,将其定义为 30,然后做一个移位操作1<<30,相当于 2 的 30 次方,等于 1073741824,量级也是恰好在 10 亿左右,由于是位数组,所以这个位数组占用的大小就是 2^30 b=128 MB。开头我们计算过 Scrapy-Redis 集合去重的占用空间大约在 2 GB 左右,可见 Bloom Filter 的空间利用效率极高。
随后我们再传入散列函数的个数,用它来生成几个不同的 seed。用不同的seed 来定义不同的散列函数,这样我们就可以构造一个散列函数列表。遍历 seed,构造带有不同seed 值的 HashMap 对象,然后将 HashMap 对象保存成变量 maps 供后续使用。
另外,server就是 Redis 连接对象,key就是这个 m 位数组的名称。
接下来,我们要实现比较关键的两个方法:一个是判定元素是否重复的方法exists(),另一个是添加元素到集合中的方法insert(),实现如下:
def exists(self, value):
"""
if value exists
:param value:
:return:
"""
if not value:
return False
exist = 1
for map in self.maps:
offset = map.hash(value)
exist = exist & self.server.getbit(self.key, offset)
return exist
def insert(self, value):
"""
add value to bloom
:param value:
:return:
"""
for f in self.maps:
offset = f.hash(value)
self.server.setbit(self.key, offset, 1)首先看下 insert() 方法。Bloom Filter 算法会逐个调用散列函数对放入集合中的元素进行运算,得到在 m 位位数组中的映射位置,然后将位数组对应的位置置 1。这里代码中我们遍历了初始化好的散列函数,然后调用其 hash() 方法算出映射位置 offset,再利用 Redis 的setbit() 方法将该位置 1。
在 exists() 方法中,我们要实现判定是否重复的逻辑,方法参数 value 为待判断的元素。我们首先定义一个变量 exist,遍历所有散列函数对value 进行散列运算,得到映射位置,用 getbit() 方法取得该映射位置的结果,循环进行与运算。这样只有每次 getbit() 得到的结果都为 1 时,最后的 exist 才为 True,即代表value 属于这个集合。如果其中只要有一次 getbit() 得到的结果为 0,即 m 位数组中有对应的 0 位,那么最终的结果 exist 就为 False,即代表value 不属于这个集合。
Bloom Filter 的实现就已经完成了,我们可以用一个实例来测试一下,代码如下:
conn = StrictRedis(host='localhost', port=6379, password='foobared')
bf = BloomFilter(conn, 'testbf', 5, 6)
bf.insert('Hello')
bf.insert('World')
result = bf.exists('Hello')
print(bool(result))
result = bf.exists('Python')
print(bool(result))这里首先定义了一个 Redis 连接对象,然后传递给 Bloom Filter。为了避免内存占用过大,这里传的位数 bit 比较小,设置为 5,散列函数的个数设置为 6。
调用 insert() 方法插入 Hello 和World两个字符串,随后判断 Hello 和Python这两个字符串是否存在,最后输出它的结果,运行结果如下:
True
False很明显,结果完全没有问题。这样我们就借助 Redis 成功实现了 Bloom Filter 的算法。
接下来继续修改 Scrapy-Redis 的源码,将它的 dupefilter 逻辑替换为 Bloom Filter 的逻辑。这里主要是修改 RFPDupeFilter 类的 request_seen() 方法,实现如下:
def request_seen(self, request):
fp = self.request_fingerprint(request)
if self.bf.exists(fp):
return True
self.bf.insert(fp)
return False利用 request_fingerprint() 方法获取 Request 的指纹,调用 Bloom Filter 的 exists() 方法判定该指纹是否存在。如果存在,则说明该 Request 是重复的,返回 True,否则调用 Bloom Filter 的insert() 方法将该指纹添加并返回False。这样就成功利用 Bloom Filter 替换了 Scrapy-Redis 的集合去重。
对于 Bloom Filter 的初始化定义,我们可以将 __init__() 方法修改为如下内容:
def __init__(self, server, key, debug, bit, hash_number):
self.server = server
self.key = key
self.debug = debug
self.bit = bit
self.hash_number = hash_number
self.logdupes = True
self.bf = BloomFilter(server, self.key, bit, hash_number)其中 bit 和hash_number需要使用 from_settings() 方法传递,修改如下:
@classmethod
def from_settings(cls, settings):
server = get_redis_from_settings(settings)
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
debug = settings.getbool('DUPEFILTER_DEBUG', DUPEFILTER_DEBUG)
bit = settings.getint('BLOOMFILTER_BIT', BLOOMFILTER_BIT)
hash_number = settings.getint('BLOOMFILTER_HASH_NUMBER', BLOOMFILTER_HASH_NUMBER)
return cls(server, key=key, debug=debug, bit=bit, hash_number=hash_number)其中,常量 DUPEFILTER_DEBUG 和BLOOMFILTER_BIT统一定义在 defaults.py 中,默认如下:
BLOOMFILTER_HASH_NUMBER = 6
BLOOMFILTER_BIT = 30现在,我们成功实现了 Bloom Filter 和 Scrapy-Redis 的对接。
2.3 封装使用
本节代码地址为:https://github.com/Python3WebSpider/ScrapyRedisBloomFilter。
为了方便使用,本节的代码已经打包成一个 Python 包并发布到 PyPi,链接为https://pypi.python.org/pypi/scrapy-redis-bloomfilter,可以直接使用 ScrapyRedisBloomFilter,不需要自己实现一遍。
我们可以直接使用 pip 来安装,命令如下:
pip3 install scrapy-redis-bloomfilter使用的方法和 Scrapy-Redis 基本相似,在这里说明几个关键配置。
# 去重类,要使用 Bloom Filter 请替换 DUPEFILTER_CLASS
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"
# 散列函数的个数,默认为 6,可以自行修改
BLOOMFILTER_HASH_NUMBER = 6
# Bloom Filter 的 bit 参数,默认 30,占用 128MB 空间,去重量级 1 亿
BLOOMFILTER_BIT = 30DUPEFILTER_CLASS是去重类,如果要使用 Bloom Filter,则DUPEFILTER_CLASS需要修改为该包的去重类。BLOOMFILTER_HASH_NUMBER是 Bloom Filter 使用的散列函数的个数,默认为 6,可以根据去重量级自行修改。BLOOMFILTER_BIT即前文所介绍的BloomFilter类的bit参数,它决定了位数组的位数。如果BLOOMFILTER_BIT为 30,那么位数组位数为 2 的 30 次方,这将占用 Redis 128 MB 的存储空间,去重量级在 1 亿左右,即对应爬取量级 1 亿左右。如果爬取量级在 10 亿、20 亿甚至 100 亿,请务必将此参数对应调高。
以上内容便是 Bloom Filter 的原理及对接实现,Bloom Filter 的使用可以大大节省 Redis 内存。在数据量大的情况下推荐此方案。
3、摘要算法
3.1 SHA
SHA(Secure Hash Algorithm)是由美国专门制定密码算法的标准机构——美国国家标准技术研究院(NIST)制定的,SHA 系列算法的摘要长度分别为:SHA 为 20 字节(160 位)、SHA256 为 32 字节(256 位)、 SHA384 为 48 字节(384 位)、SHA512 为 64 字节(512 位),由于它产生的数据摘要的长度更长,因此更难以发生碰撞,因此也更为安全,它是未来数据摘要算法的发展方向。由于 SHA 系列算法的数据摘要长度较长,因此其运算速度与 MD5 相比,也相对较慢。
目前 SHA1 的应用较为广泛,主要应用于 CA 和数字证书中,另外在目前互联网中流行的 BT 软件中,也是使用 SHA1 来进行文件校验的。
3.1.1 SHA-1
SHA-1 算法可以从明文生成 160bit 的信息摘要,示例如下:
给定明文: abcd
SHA-1 摘要: 81FE8BFE87576C3ECB22426F8E57847382917ACF
import hashlib
sha1 = hashlib.sha1()
sha1.update(b'abcd')
print(sha1.hexdigest())SHA-1 与 MD5 的主要区别是什么呢?
1. 摘要长度不同。
MD5 的摘要的长度为 128bit,SHA-1 摘要长度 160bit。多出 32bit 意味着什么呢?不同明文的碰撞几率降低了 2^32 = 324294967296 倍。
2. 性能略有差别
SHA-1 生成摘要的性能比 MD5 略低。
3.1.2 SHA-2
SHA-2 是一系列 SHA 算法变体的总称,其中包含如下子版本:
SHA-256:可以生成长度 256bit 的信息摘要。
SHA-224:SHA-256 的“阉割版”,可以生成长度 224bit 的信息摘要。
SHA-512:可以生成长度 512bit 的信息摘要。
SHA-384:SHA-512 的“阉割版”,可以生成长度 384bit 的信息摘要。
3.2 MD5
Message-Digest Algorithm 5,消息摘要算法版本 5。由 Ron Rivest(RSA 公司)在 1992 年提出,目前被广泛应用于数据完整性校验、数据(消息)摘要、数据加密等。MD2、MD4、MD5 都产生 16 字节(128 位)的校验值,一般用 32 位十六进制数表示。MD2 的算法较慢但相对安全,MD4 速度很快,但安全性下降,MD5 比 MD4 更安全、速度更快。
是信息摘要的一种实现,它可以从任意长度的明文字符串生成 128 位哈希值
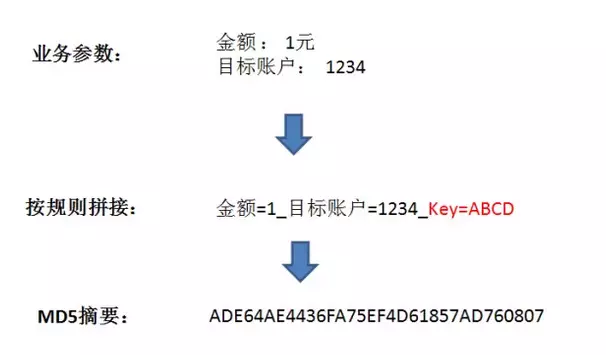
摘要哈希生成的正确姿势是什么样呢?分三步:
1. 收集相关业务参数,在这里是金额和目标账户。当然,实际应用中的参数肯定比这多得多,这里只是做了简化。
2. 按照规则,把参数名和参数值拼接成一个字符串,同时把给定的 密钥 也拼接起来。之所以需要密钥,是因为攻击者也可能获知拼接规则。
3. 利用 MD5 算法,从原文生成哈希值。MD5 生成的哈希值是 128 位的二进制数,也就是 32 位的十六进制数。
考虑把多种摘要算法结合使用比如
明文: abcd
MD5 摘要:
e2fc714c4727ee9395f324cd2e7f331f
SHA-256 摘要:
88d4266fd4e6338d13b845fcf289579d209c897823b9217da3e161936f031589
取 MD5 摘要的前 16 位,取 SHA-256 的后 32 位
简单概括起来,MD5 算法的过程分为四步:处理原文 , 设置初始值 , 循环加工,拼接结果。
第一步: 处理原文
首先,计算出原文长度 (bit) 对 512 求余的结果,如果不等于 448,就需要填充原文使得原文对 512 求余的结果等于 448。填充的方法是第一位填充 1,其余位填充 0。填充完后,信息的长度就是 512*N+448。
之后,用剩余的位置(512-448=64 位)记录原文的真正长度,把长度的二进制值补在最后。这样处理后的信息长度就是 512*(N+1)。
第二步: 设置初始值
MD5 的哈希结果长度为 128 位,按每 32 位分成一组共 4 组。这 4 组结果是由 4 个初始值 A、B、C、D 经过不断演变得到。
第三步: 循环加工
这一步是最复杂的一步,我们看看下面这张图,此图代表了单次 A,B,C,D 值演变的流程。
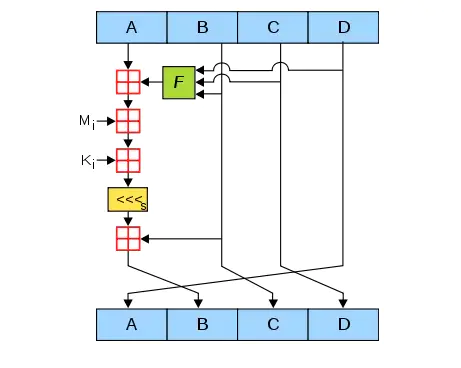
图中,A,B,C,D 就是哈希值的四个分组。每一次循环都会让旧的 ABCD 产生新的 ABCD。一共进行多少次循环呢?由处理后的原文长度决定。
假设处理后的原文长度是 M
主循环次数 = M / 512
每个主循环中包含 512 / 32 * 4 = 64 次 子循环。
上面这张图所表达的就是 单次子循环 的流程。
1. 图中的绿色 F,代表非线性函数
2. 红色的田字代表相加
3. 黄色的 <<<S(左移 S 位)
4.Mi 是第一步处理后的原文。在第一步中,处理后原文的长度是 512 的整数倍。把原文的每 512 位再分成 16 等份,命名为 M0M15,每一等份长度 32。在 64 次子循环中,每 16 次循环,都会交替用到 M1M16 之一。
5.ki 一个常量,在 64 次子循环中,每一次用到的常量都是不同的
第四步:拼接结果
这一步就很简单了,把循环加工最终产生的 A,B,C,D 四个值拼接在一起,转换成字符串即可。
简而言之,MD5 把 128bit 的信息摘要分成 A,B,C,D 四段(Words),每段 32bit,在循环过程中交替运算 A,B,C,D,最终组成 128bit 的摘要结果。
SHA 算法与 MD5 区别
SHA-1 算法,核心过程大同小异,主要的不同点是把 160bit 的信息摘要分成了 A,B,C,D,E 五段。
SHA-2 系列算法,核心过程更复杂一些,把信息摘要分成了 A,B,C,D,E,F,G,H 八段。
其中 SHA-256 的每一段摘要长度是 32bit,SHA-512 的每一段摘要长度是 64bit。SHA-224 和 SHA-384 则是在前两者生成结果的基础上做出裁剪。
3.3 CRC
CRC(Cyclic Redundancy Check,循环冗余校验)算法出现时间较长,应用也十分广泛,尤其是通讯领域,现在应用最多的就是 CRC32 算法,它产生一个 4 字节(32 位)的校验值,一般是以 8 位十六进制数,如 FA 12 CD 45 等。CRC 算法的优点在于简便、速度快,严格的来说,CRC 更应该被称为数据校验算法,但其功能与数据摘要算法类似,因此也作为测试的可选算法。
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net