MySQL 是一个 DBMS(数据库管理系统),由瑞典 MySQLAB 公司开发,目前属于 Oracle (甲骨文)公司,是最流行的关系型数据库管理系统(关系数据库,是建立在关系数据库模型基础上的数据库,借助于集合代数等概念和方法来处理数据库中的数据)。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发者都选择 MySQL 作为网站数据库。MySQL 使用 SQL 语言进行操作。
菜鸟教程:https://www.runoob.com/mysql/mysql-administration.html
概念对比
- DB:数据库,存放数据的容器
- DBMS:数据库管理系统,用于管理 DB
- SQL:结构化查询语言,是关系型数据库的通用语言
RDBMS 术语
在我们开始学习 MySQL 数据库前,让我们先了解下 RDBMS 的一些术语:
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(= 元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
1、安装
1.1 Windows 系统
1.1.1 下载
安装包下载地址:https://dev.mysql.com/downloads/mysql/
注意选择 size 大点的下载。
1.1.2 安装
建议自定义安装,如下:
选择模块:

自定义安装路径:

接下来一直 next 就行。
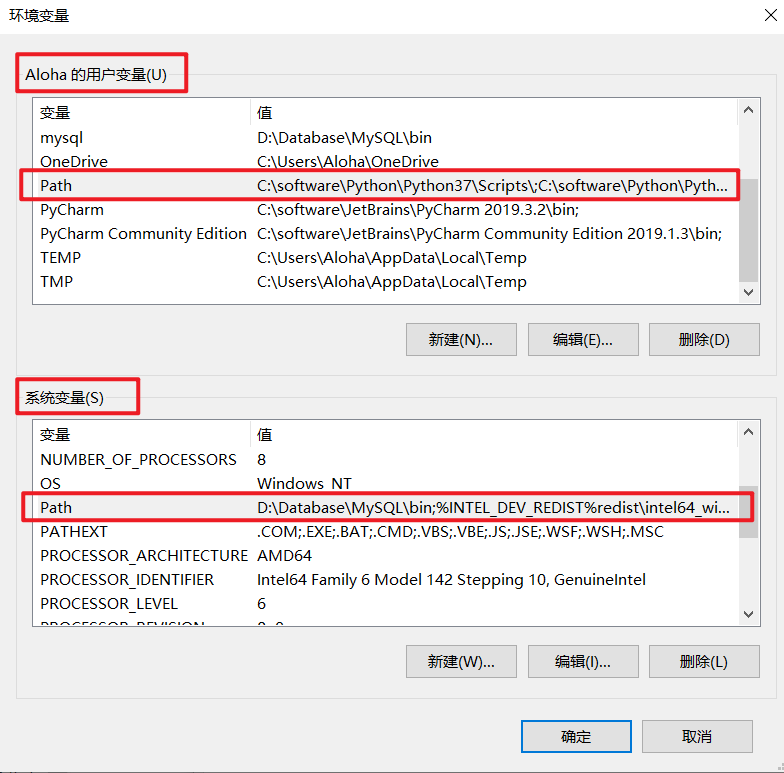
1.1.3 配置环境变量
为了避免每次需要在 CMD 命令行下,需 CD 到 Mysql 安装目录下才能启动 Mysql,可以提前配置好环境变量,这样就可以不用进入其安装目录也能执行启动命令。
找到环境变量设置入口:

将 Mysql 安装路径加入到环境变量中:
1.2 Ubuntu 系统
1.2.1 安装及配置
首先依次执行:
sudo apt-get install mysql-server
sudo apt install mysql-client
sudo apt install libmysqlclient-dev安装成功后可以通过下面的命令测试是否安装成功:
sudo netstat -tap | grep mysql
#出现……localhost:mysql……等信息说明成功 进入 mysql:
sudo mysql退出:
mysql>quit设置 mysql 允许远程访问,首先编辑文件 /etc/mysql/mysql.conf.d/mysqld.cnf
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf注释掉 bind-address = 127.0.0.1,保存退出。
然后进入 mysql 服务,执行授权命令:
mysql>grant all on *.* to root@'%' identified by ' 你的密码 ' with grant option;
mysql>flush privileges;然后执行 quit 命令退出 mysql 服务,执行如下命令重启 mysql:
sudo service mysql restart现在在 windows 下可以使用 navicat 远程连接 ubuntu 下的 mysql 服务。
navicat 连接 mysql 数据库:在 general 界面输入数据库相关信息,在 SSH 界面输入 linux 系统登陆信息。
默认 mysql 相关文件位置:
/var/lib/mysql 日志文件,数据库 [重点要知道这个]
/usr/bin 客户端程序和脚本
/usr/sbin mysqld 服务器
/usr/share/doc/packages 文档
/usr/include/mysql 包含(头) 文件
/usr/lib/mysql 库
/usr/share/mysql 错误消息和字符集文件
/usr/share/sql-bench 基准程序 1.2.2 问题修复
发现采用 1.3 章节设置密码后,不输入密码依然能进数据库,如:
sudo mysql
mysql>修复方法如下:
# 进入 mysql
sudo mysql
#依次输入以下命令:
mysql>update user set authentication_string=PASSWORD(" 密码 ") where user='root';
mysql>update user set plugin="mysql_native_password";
mysql>flush privileges;
mysql>quit;
sudo service mysql restart1.3 修改数据库密码
mysql> set password for root@localhost = password('123'); 2、增删改
2.1 基本操作
2.1.1 CMD 命令行下
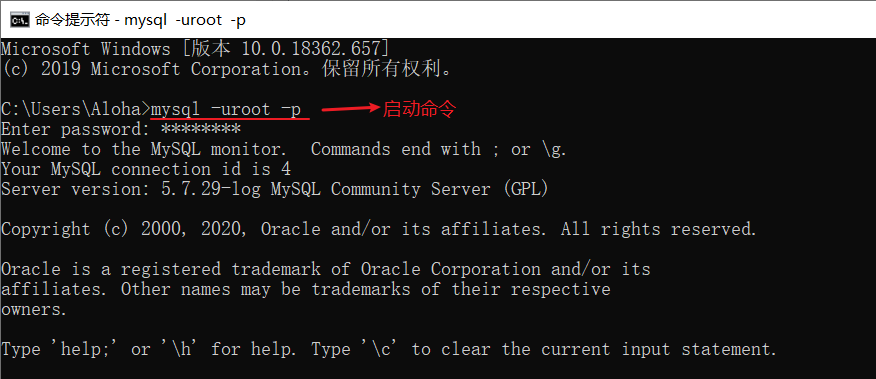
启动 mysql:
mysql -uroot -p // 启动时会提示输入密码由于已经配置了环境变量,直接输入上述命令即可。如没有配置,需要 cd 到其安装目录才能执行启动命令。
查看已有数据库:
show databases;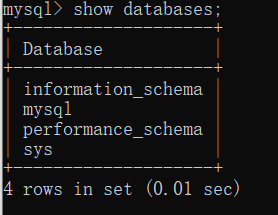
创建,使用及退出:

注意这里的 quit 并没有真正退出,后台还有 mysql 服务存在。
2.1.2 连接 Pycharm
首先要求 Pycharm 使用的是专业版,社区版是没有的数据库功能的。
启动数据库(保证 Mysql 服务在后台运行,在任务管理器中查看)。
打开连接界面:

进行连接:

测试连接时,如出现错误 Server returns invalid timezone……
应该是时区没设置对
show variables like '%time_zone%';
这里的 SYSTEM 默认时的美国时间。
解决办法:
①
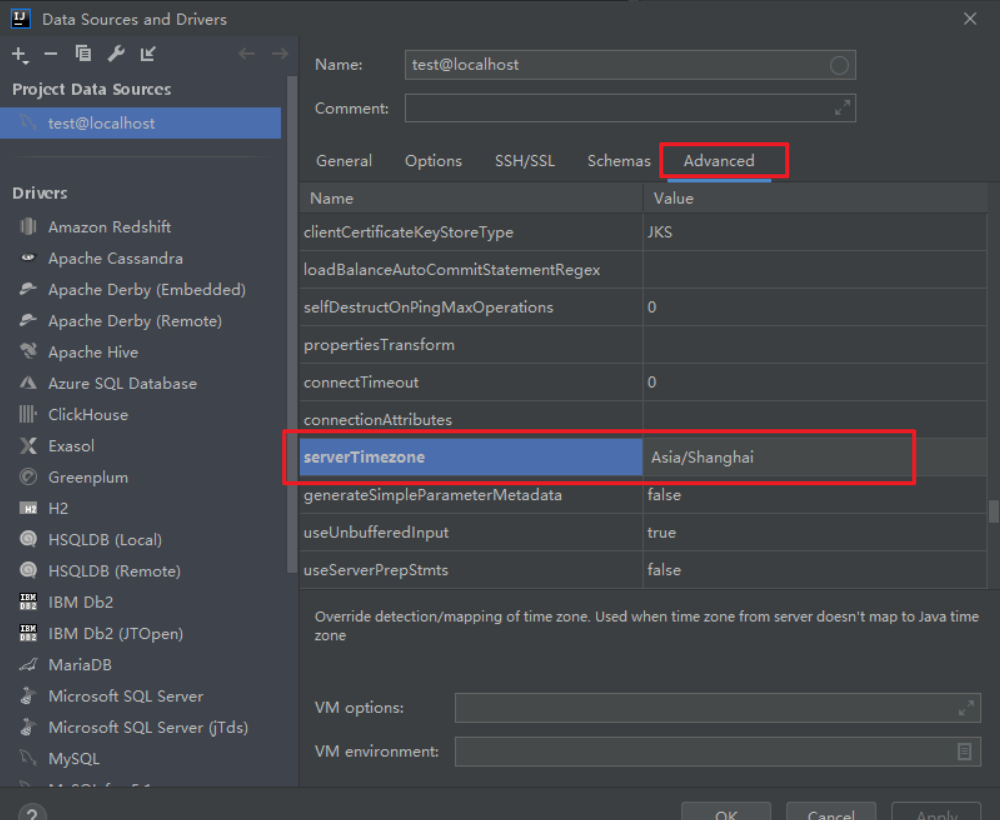
②在 mysql 的命令模式下,CMD 下输入:
mysql> set global time_zone='+8:00';设置完成之后,就可以进行愉快的玩耍了!
尝试使用命令:
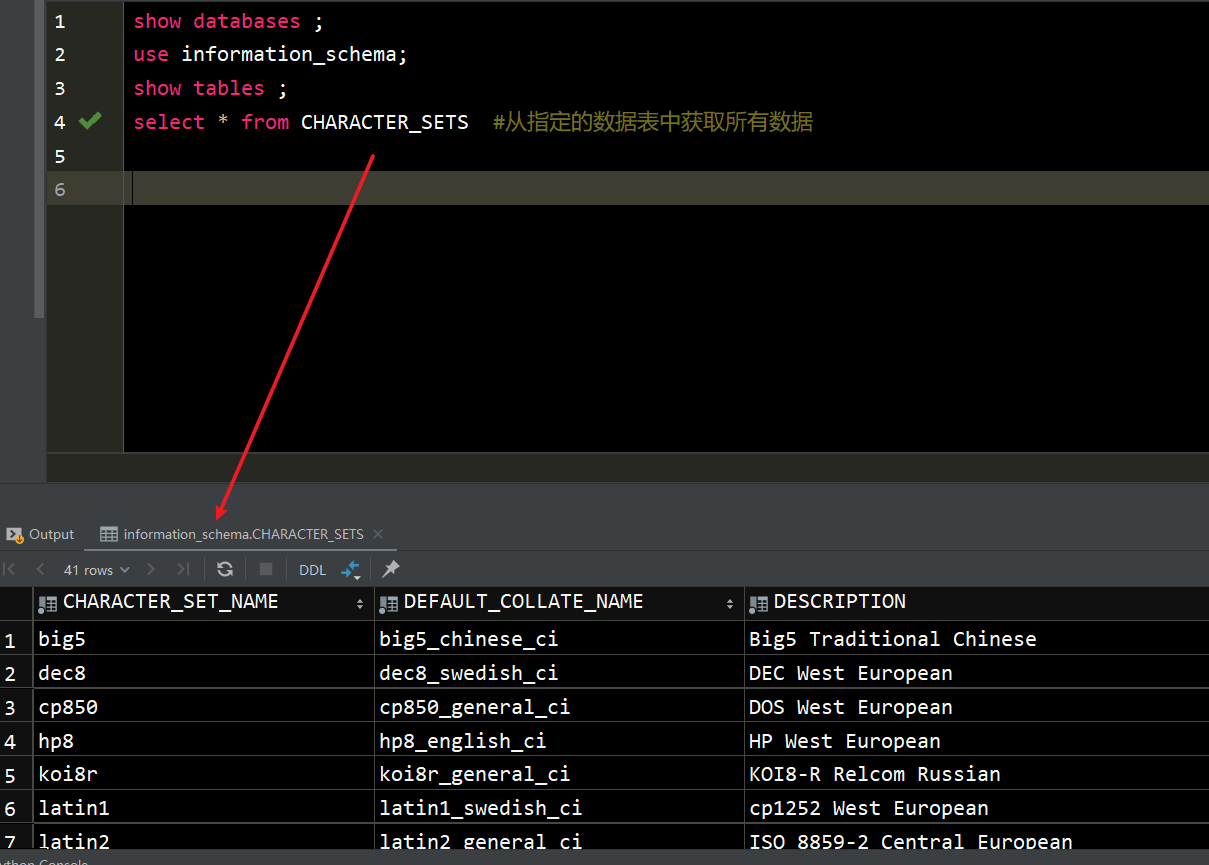
2.2 基础知识
在 pycharm 里操作数据库。
2.2.1 创建与删除
创建与删除数据库
show databases; // 显示数据库
create database python character set utf8; // 创建数据库, 指定字符集,避免中文无法识别
drop database 库名; // 删除数据库
ALTER DATABASE 库名 CHARACTER SET gbk; // 更改库的字符集创建数据库,还可以这样:
create database if not exists 库名 // 不存在才创建 创建数据表
只有创建了数据表才能进行数据操作。
use python; // 指定要操作的数据库
create table maoyan(moive_name varchar(50) primary key,
moive_data varchar(50),
score varchar(10)
) character set utf8; //varchar(50)指定字符串最大长度
desc maoyan; // 查看表结构
删除数据表
drop table if exists 表名; 修改数据表
alter table maoyan modify column score char(3);
增加新字段
alter table maoyan add column star varchar(50);
删除字段
alter table maoyan drop column star;修改表名
alter table maoyan rename to 新表名 ;2.2.2 数据类型
| 数据类型 | 大小(字节) | 用途 | 格式 |
|---|---|---|---|
| INT | 4 | 整数 | |
| FLOAT | 4 | 单精度浮点数 | |
| DOUBLE | 8 | 双精度浮点数 | |
| ENUM | – | 单选, 比如性别 | ENUM(‘a’,’b’,’c’) |
| SET | – | 多选 | SET(‘1’,’2’,’3’) |
| DATE | 3 | 日期 | YYYY-MM-DD |
| TIME | 3 | 时间点或持续时间 | HH:MM:SS |
| YEAR | 1 | 年份值 | YYYY |
| CHAR | 0~255 | 定长字符串 | |
| VARCHAR | 0~255 | 变长字符串 | |
| TEXT | 0~65535 | 长文本数据 |
整数除了 INT 外,还有 TINYINT、SMALLINT、MEDIUMINT、BIGINT。
数值
整数
分类
- Tinyint,1 个字节
- Smallint,2 个字节
- Mediumint,3 个字节
- Int,4 个字节
- Bigint,8 个字节
符号
- 默认有符号
- 设置无符号的方法,使用 UNSIGNED 关键字
CREATE TABLE t ( t1 INT, t2 INT UNSIGNED );长度
- 长度表示最大显示宽度,当使用 zerofill 时,不够长度时,用 0 填空
- 如果不配合 zerofill,则整型的长度没用
越界
- 如果插入的数值超出范围,则报 out of range 异常,并插入最接近的临界值
浮点数
- Float,4 个字节
- Double,8 个字节
定点数
- DECIMAL(M,D)
- M:整数 + 小数的位数
- D:小数的位数
- M 默认为 10, D 默认为 0
- DECIMAL(M,D)
字符型
- 较短文本
- char:固定长度,性能高,不能节约空间
- varchar:可变长度,性能低,能节约空间
- 长度为最大长度
- 较长文本
- text
- 二进制
- binary:类似 char,存储的是二进制
- varbinary:类似 varchar,存储的是二进制
- Blob:存储数据量大的二进制,比如视频,图片
日期型
- date:2018-09-26
- time:17:11:37
- year:2018
- datetime:2018-09-26 17:11:50,与时区无关,8 个字节
- timestamp:20180926171211,受 MySQL 版本影响,与时区有关,4 个字节
2.2.3 字符长度
一个汉字占多少长度与编码有关:
UTF-8:一个汉字=3 个字节
GBK:一个汉字=2 个字节
在 MySQL 中 varchar(n)和 char(n)表示 n 个字符,无论汉字和英文,Mysql 都能存入 n 个字符,仅是实际字节长度有所区别。
即 MySQL 并不会对超过长度的字符报错, 而是直接截断了。并且 char(2) 和 varchar(2) 都能存储 2 个汉字, 或者是两个英文字符。
2.3 不懂就查
表的修改
重命名一张表
重命名一张表的语句有多种形式,以下 3 种格式效果是一样的:
rename table 原名 to 新名字;
alter table 原名 rename 新名;
alter table 原名 rename to 新名;
进入数据库 python:
use python使用命令尝试修改 table_1 的名字为 table_2 :
rename table table_1 to table_2;删除一张表
删除一张表的语句,类似于刚才用过的删除数据库的语句,格式是这样的:
drop table 表名字;比如我们把 table_2 表删除:
drop table table_2;列的修改
即对表结构的修改
对表结构的修改,有时候一些小的错误会造成不可挽回的后果,所以请细心操作。另外需要注意,非必要情况不要修改表结构。
增加一列
在表中增加一列的语句格式为:
alter table 表名字 add column 列名字 数据类型 约束;
或:
alter table 表名字 add 列名字 数据类型 约束;现在 employee 表中有 id、name、age、salary、phone、in_dpt 这 6 个列,我们尝试加入 height (身高)一个列并指定 DEFAULT 约束:
alter table employee add height INT(4) default 170;新增加的列,被默认放置在这张表的最右边。如果要把增加的列插入在指定位置,则需要在语句的最后使用 AFTER 关键词(“AFTER 列 1” 表示新增的列被放置在 “列 1” 的后面)。
提醒:语句中的 INT(4) 不是表示整数的字节数,而是表示该值的显示宽度,如果设置填充字符为 0,则 170 显示为 0170
比如我们新增一列 weight(体重) 放置在 age(年龄) 的后面:
alter table employee add weight INT(4) default 120 after age;上面的效果是把新增的列加在某位置的后面,如果想放在第一列的位置,则使用 FIRST关键词,如语句:
alter table employee add test INT(10) default 11 FIRST;删除一列
删除表中的一列和刚才使用的新增一列的语句格式十分相似,只是把关键词 ADD 改为 DROP ,语句后面不需要有数据类型、约束或位置信息。具体语句格式:
alter table 表名字 drop column 列名字;
或: alter table 表名字 drop 列名字;我们把刚才新增的 test 删除:
alter table employee drop test;重命名一列
这条语句其实不只可用于重命名一列,准确地说,它是对一个列做修改(CHANGE) :
alter table 表名字 change 原列名 新列名 数据类型 约束;注意:这条重命名语句后面的 “数据类型” 不能省略,否则重命名失败。
当 原列名 和新列名 相同的时候,指定新的 数据类型 或约束,就可以用于修改数据类型或约束。需要注意的是,修改数据类型可能会导致数据丢失,所以要慎重使用。
我们用这条语句将 “height” 一列重命名为汉语拼音 “shengao” ,效果如下:
alter table employee change height shengao INT(4) default 170;
改变数据类型
要修改一列的数据类型,除了使用刚才的 CHANGE 语句外,还可以用这样的 MODIFY语句:
alter table 表名字 modify 列名字 新数据类型;再次提醒,修改数据类型必须小心,因为这可能会导致数据丢失。在尝试修改数据类型之前,请慎重考虑。
内容修改
修改表中某个值
大多数时候我们需要做修改的不会是整个数据库或整张表,而是表中的某一个或几个数据,这就需要我们用下面这条命令达到精确的修改:
update 表名字 set 列 1 = 值 1, 列 2= 值 2 where 条件;
比如,我们要把 Tom 的 age 改为 21,salary 改为 3000:
update employee set age=21,salary=3000 where name='Tom';
注意:一定要有 WHERE 条件,否则会出现你不想看到的后果
删除一行记录
删除表中的一行数据,也必须加上 WHERE 条件,否则整列的数据都会被删除。删除语句:
delete from 表名字 where 条件;我们尝试把 Tom 的数据删除:
delete from employee where name='Tom';3、插入数据
3.1 插入
insert into
语法 1 - 【常用;支持多行;可用于子查询】
insert into 表名(字段 1, 字段 2, 字段 3……) values(字值 1, 字值 2, 字值 3……);注意
- 如果想设置空值,可以用 NULL 表示
- 字段列表和字段值列表必须一一对应
- 需要自己指定 id
- 若字值数是完整,可以省略字段
语法 2 - 【不常用;不支持多行;不可用于子查询】
insert into 表名 set 字段名 = 值, 字段名 = 值,...;
注意:当插入字符有中文时,需要在创建表时设置character set utf8
如创建表时,指定了约束 auto_increment就可以不用指定 id。
replace into 数据替换更新,与 insert into 写法相同
3.2 更新
udate
语法 1 - 【单表更新】
udate 表名 set 字段名 = 值, 字段名 = 值 where 筛选条件;语法 2 - 【多表更新】
udate 表 1 as 别名 inner | left | right join 表 2 as 别名 on 连接条件 set 字段名 = 值 where 筛选条件;例子
udate boys as b inner join girls as g on b.id = g.id set g.phone = 1111 where b.name = " 小明 ";
3.3 删除
delete from
语法 1 - 【单表删除】
delete from 表名 where 筛选条件;语法 2 - 【多表删除】
delete from 表 1 as 别名 inner | left | right join 表 2 as 别名 on 连接条件 where 筛选条件;例子
delete from girls as g inner join boys as b on b.id = g.id where b.name=" 小明 ";
3.4 清空
truncate table
语法
truncate table boys;注意事项
- delete from 是删除表中某些行数据, truncate table 是清空整张表
- delete from 删除后,自增字段不重置; truncate table 清空后,自增字段重置为 1
- delete from 可以回滚, truncate table 不能回滚
刚才我们新建了两张表,使用语句 SELECT * FROM employee; 查看表中的内容,可以看到 employee 表中现在还是空的:
mysql> SELECT * FROM employee;
Empty set (0.00 sec)我们通过 INSERT 语句向表中插入数据,语句格式为:
insert into 表的名字 (列名 a, 列名 b, 列名 c) values(值 1, 值 2, 值 3);我们尝试向 employee 中加入 Tom、Jack 和 Rose:
insert into employee(id,name,phone) values(01,'Tom',110110110);
insert into employee values(02,'Jack',119119119);
insert into employee(id,name) values(03,'Rose');你已经注意到了,有的数据需要用单引号括起来,比如 Tom、Jack、Rose 的名字,这是由于它们的数据类型是 CHAR 型。此外 VARCHAR,TEXT,DATE,TIME,ENUM 等类型的数据也需要单引号修饰,而 INT,FLOAT,DOUBLE 等则不需要。
第一条语句比第二条语句多了一部分:(id,name,phone) 这个括号里列出的,是将要添加的数据 (01,'Tom',110110110) 其中每个值在表中对应的列。而第三条语句只添加了 (id,name) 两列的数据,所以在表中 Rose 的 phone 为 NULL。
现在我们再次使用语句 SELECT * FROM employee; 查看 employee 表,可见 Tom 和 Jack 的相关数据已经保存在其中了:
mysql> SELECT * FROM employee;
+------+------+-----------+
| id | name | phone |
+------+------+-----------+
| 1 | Tom | 110110110 |
| 2 | Jack | 119119119 |
| 3 | Rose | NULL |
+------+------+-----------+
3 rows in set (0.00 sec)
4、 查询
Data Query Language[DQL]
SQL 中最常用的 SELECT 语句,用来在表中选取数据,本节实验中将通过一系列的动手操作详细学习 SELECT 语句的用法。
练习用数据库导入
- 下载相关资源中的
select.sql - 执行 sql 脚本
source myemployees.sql;4.1 基础查询
SELECT 子句
select 查询字段 from 表名;
-- 查询字段包括:表的字段,常量值,表达式,函数
-- 查询的结果是一个虚拟的表查询表中单个字段
select name from employees;查询表中多个字段
select name, salary, age from employees;查询表中所有字段
select * from employees;
字段起别名
方式一:select name as 姓 from employees;
方式二:select name 姓 from employees;
特殊符号:select last_name as "OUT#PUT" from employees;查询结果去重
select distinct department_id from employees;4.2 条件查询
WHERE 子句
select 查询列表 from 表名 where 条件表达式;比较运算符
> < >= <= = !=(<>) 逻辑运算符
&& || !
AND OR NOT例如:
select * from maoyan where film_name =' 龙猫 ';结果如下(pycharm 环境下)
4.2.1 模糊查询
模糊查询关键字
| 模糊查询语句 | 注意事项 |
|---|---|
| like | 与通配符配合使用 |
| between x and y | 包含边界,等价于 >= x && <= y |
| in | IN (待选列表),待选列表中的元素类型要相同 |
| is null | 不能用 = 判断是否是 NULL,只能用 IS 判断是否是 NULL,仅可以判断 NULL |
通配符
% :任意多个字符,包含 0 个
_ :任意 1 个字符转义通配符
\_
\%select name,age,phone
from employee
where name like ' 张一 %'; // 找出表中 name 列中含有‘张三’的内容4.3 排序查询
ORDER BY 子句
select * FROM employees
order by salary DESC; -- DESC:降序,ASC: 升序,默认为 ASC// 举例:
select * from maoyan order by scores;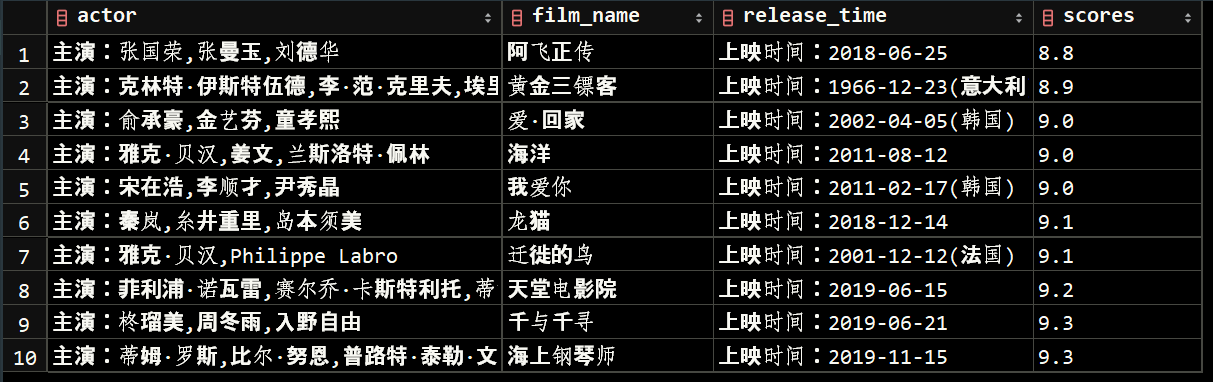
多重排序标准
-- 先按 salary 进行升序排序,保证满足前提条件的情况下,按 employee_id 进行降序排序
select *
from employees
order by salary ASC, employee_id DESC;4.4 常用函数
字符函数
- length
-- 求出字节的个数
select length(last_name) from employees;- concat
select concat('a','b','c','d') as ' 结果 ';
select concat(last_name, first_name) as name from employee; // 合并- upper
select upper(last_name) from employees;- lower
select lower(last_name) from employees;- substr
select substr("123456789", 5) // 56789 索引从 1 开始
select substr("123456789", 5, 2) // 567 从索引 5 开始,长度为 2- instr
select instr("123456789", "567") // 返回第一次出现的索引 5
select instr("123456789", "xxx") // 找不到返回 0- trim
select trim(" xxx ") // 去除前后空格
select trim("a" from "aaaaaaaaaaaaaxxxaaaxxxaaaaaaaaa") // 返回 "xxxaaaxxx"- lapd
select lpad("abc", 15, "*") // "***************abc"
select lpad("abc", 2, "*") // "ab"- rpad
select rpad("abc", 15, "*") // "abc***************"
select rpad("abc", 2, "*") // "bc"数学函数
- round
select round(4.56); // 5
select round(-1.56) // -2
select round(-1.567, 2) // -1.57 - cell
select cell(1.0001) // 2
select cell(-1.02) // -1
select cell(1.00) // 1- floor
select floor(1.0001) // 1
select floor(-9.8) //-10- truncate
select truncate(1.699999,1); // 1.6日期函数
- NOW
select now();- CURDATE
select curdate();- CURTIME
select curtime();- YEAR
select year(now());
select year("2018-9-14 08:23:57");MONTH,DAY,HOUR,MINUTE,SECOND 同上
- STR_TO_DATE
str_to date("9-13-1999", "%m-%-%y")
%y 18 %Y 2018
%m 08 %c 8
%d 08
%H 24 小时制
%h 12 小时制
%i 35
%s 05- DATE_FORMAT
date_format("2018/6/6","%Y 年 %m 月 %d 日 ")流程控制语句
- IF
select *, if(scores<9,' 低 ',' 高 ') level from maoyan;
如下:新增了一列”level”

// 多层嵌套写法:
select *,if(sex=0,' 女 ',if(sex=1,' 男 ',' 保密 ')) sex_l from user;- CASE
case (要判断的表达式,有就是 switch,否则是 if-else)
when 常量 1 then 语句 1
when 常量 2 then 语句 2
...
else 语句 x
end
// 如:
select *,case
when username='admin' then ' 超级管理员 '
when email='root@qq.com' then ' 系统管理员 '
when is_super = 2 then ' 测试管理员 '
when status ='0 'then ' 失效管理员 '
else ' 其它管理员 ' end ' 管理员类型 ' from db_admin_user 其他函数
- IFNULL 函数
-- ifnull(exp1, exp2)
-- exp1:将要进行判断的字段
-- exp2:替换的字段
-- 如果 exp1 为 NULL,则返回替换的字段
select ifnull(commission_pct, 0) as " 奖金率 ", commission_pct
from employees;统计函数
- SUM:忽略 NULL
- AVG:忽略 NULL
- MAX:忽略 NULL
- MIN:忽略 NULL
- COUNT:忽略 NULL
- 注意事项
- sum avg 可以处理数值
- max,min,count 可以处理任何类型
- 分组函数都忽略 NULL
- 可以和 distinct 配合实现去重
- COUNT(*) :统计行数,只要有不含 NULL 的,都算一行
- COUNT(1):统计行数,只要有不含 NULL 的,都算一行
- 和分组函数一同查询的字段要求是 group by 后的字段
select sum(scores) as sum_scores from maoyan;4.5 分组查询
GROUP BY 子句
select
from
where
group by
group by group by 强调的是一个整体,就是组,只能显示一个组里满足聚合函数的一条记录。 partition by 在整体后更强调个体,能显示组里所有个体的记录。
HAVING (过滤)子句
select *
from maoyan
where scores>9
group by made_country
having made_country='china'
order by scores desc;4.6 连接查询
分类
- 内连接
- 等值连接
- 非等值连接
- 自连接
- 外连接
- 左外连接
- 右外连接
- 全外连接
- 交叉连接:就是笛卡尔积
语法
select 查询列表
from 表 1 as 别名
连接类型 表 2 as 别名
on 连接条件
where
group by
having
order by
连接类型
内连接:inner join,可以省略 inner
左外连接:left join
右外连接:right join
全外连接:full join
交叉连接:cross join例子
select last_name, department_name
from employees as e
inner join department as d
on e.department_id = d.department_id;4.7 分页查询
LIMIT 的使用
放在全部 SQL 语句最后
LIMIT 开始索引,条目个数
如果开始索引是 0,则可以省略
例子
分页通用写法
sleect 查询列表
from 表
limit (页码 -1) * 每页条目个数, 每页条目个数;4.8 联合查询
- 将多条查询语句的结果集合并为一个结果集
- 关键字:UNION
例如
select * from employees where email like '%a%'
union
select * from employees where department_id > 90;注意事项
- 要求多条查询语句的查询结果列数相同
- UNION 关键字默认去重,如果不想去重则 UNION ALL 可以包含重复项
5、 数据约束
constraint.sql文件中包含的代码可以新建一个数据库python, 然后在其中创建三张表department,employee,project,它们包含了各种约束。
听名字就知道,约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性。
比如,规定一个用户的用户名不能为空值且没有重复的记录,这就是一种约束规则。
5.1 五大约束类型
在 MySQL 中,通常有这几种约束:
| 约束类型: | 主键 | 默认值 | 唯一 | 外键 | 非空 |
|---|---|---|---|---|---|
| 关键字: | primary key | default | unique | foreign key | not null |
5.1.1 主键约束
在数据库中,如果有两行记录数据完全一样,那么如何来区分呢? 答案是无法区分,如果有两行记录完全相同,那么对于 Mysql 就会认定它们是同一个实体,这于现实生活是存在差别的。
假如我们要存储一个学生的信息,信息包含姓名,身高,性别,年龄。
不幸的是有两个女孩都叫小梦,且她们的身高和年龄相同,数据库将无法区分这两个实体,这时就需要用到主键了。
主键 (PRIMARY KEY)是用于约束表中的一行,作为这一行的唯一标识符,在一张表中通过主键就能准确定位到一行,因此主键十分重要,主键不能有重复记录且不能为空。
还有一种特殊的主键——复合主键。主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识
5.1.2 默认值约束
默认值约束 (DEFAULT) 规定,当有 DEFAULT 约束的列,插入数据为空时,将使用默认值。
DEFAULT 约束只会在使用 INSERT 语句时体现出来, INSERT 语句中,如果被 DEFAULT 约束的位置没有值,那么这个位置将会被 DEFAULT 的值填充
5.1.3 唯一约束
唯一约束 (UNIQUE) 比较简单,它规定一张表中指定的一列的值必须不能有重复值,即这一列每个值都是唯一的。
当 INSERT 语句新插入的数据和已有数据重复的时候,如果有 UNIQUE 约束,则 INSERT 失败,
5.1.4 外键约束
外键 (FOREIGN KEY) 既能确保数据完整性,也能表现表之间的关系。
比如,现在有用户表和文章表,给文章表中添加一个指向用户 id 的外键,表示这篇文章所属的用户 id,外键将确保这个外键指向的记录是存在的,如果你尝试删除一个用户,而这个用户还有文章存在于数据库中,那么操作将无法完成并报错。因为你删除了该用户过后,他发布的文章都没有所属用户了,而这样的情况是不被允许的。同理,你在创建一篇文章的时候也不能为它指定一个不存在的用户 id。
一个表可以有多个外键,每个外键必须 REFERENCES (参考) 另一个表的主键,被外键约束的列,取值必须在它参考的列中有对应值。
5.1.5 非空约束
非空约束 (NOT NULL), 听名字就能理解,被非空约束的列,在插入值时必须非空。
在 MySQL 中违反非空约束,会报错
5.2 列级约束与表级约束
列级约束:约束语法都不报错,但是外键约束没有效果
表级约束:支持主键约束,外键约束,唯一约束
create table 表名( 字段名 字段类型 列级约束 字段名 字段类型 constraint 表级约束名 表级约束类型(字段名) )列级约束例子
create table stuinfo ( id INT primary key, # 主键约束 stuName VARCHAR(20) not null, # 非空约束 gender CHAR(1) default 'm', # 默认约束 seat INT unique, # 唯一约束 major INT foreign key references major(id) # 外键约束,但是没有效果 );表级约束例子
create table stuinfo ( id INT stuName VARCHAR(20) not null, # 非空约束 gender CHAR(1) default 'm', # 默认约束 seat INT, major INT, constraint pk primary key(id), # 主键约束 constraint uq unique(seat), # 唯一约束 constraint fk_stuinfo_major foreign key(major(id)) references major(id) # 外键约束 );
5.3 主键约束和唯一约束的区别
| 约束类型 | 保证唯一性 | 是否允许为空 | 允许多少个 | 是否允许组合 |
|---|---|---|---|---|
| 主键 | 保证 | 不允许 | 最多 1 个 | 允许 |
| 唯一 | 保证 | 允许 | 可以多个 | 允许 |
5.4 外键使用注意事项
- 外键关联的必须是 Key,一般是 主键 / 唯一键
- 插入数据时,先插入主表,再插入从表
- 删除数据时,先删除从表,再删除主表
5.5 联合主键
用几个列进行唯一标识一行,即若两列(n 列)作为联合主键,这两列相同,就意味这重复,就会插入数据失败。
create table abc(
a date ,
d varchar(8),
c varchar(8),
constraint a_d primary key(a,d)
)character set utf8;
insert into abc(a,d,c) values ('1993-09-02',' 小明 ',' 男 ');
// 插入成功
insert into abc(a,d,c) values ('1993-09-02',' 小红 ',' 男 ');
// 插入成功
insert into abc(a,d,c) values ('1993-09-02',' 小明 ',' 女 ');
// 插入失败,因为 a 和 d 列相同6、高级操作
本节实验中我们将学习并实践数据库的其他基本操作:索引、视图,导入和导出,备份和恢复等。
这些概念对于数据库管理员而言都非常重要,请仔细理解并完成所有实验操作。
作为基础篇,不会涉及到关于索引和视图的高级应用和核心概念,但是基本操作大家会了解,尤其是关于索引的内容,学会建立恰当的索引可以大大提高数据库的查询效率,更高级的应用我们会在进阶篇详细讲解。
知识点
- 索引
- 视图
- 导入和导出
- 备份和恢复
准备
注:进入本节进行学习的,请先删除上一节建立的数据库
python,删除语句为DROP DATABASE python;。
在开始之前, 将sql 资料 文件夹下的 advanced_operation.sql 拷贝到桌面
代码会搭建好一个名为 python 的数据库(有三张表:department,employee,project),并向其中插入数据。
输入命令开启 MySQL 服务并登录:
# 打开 MySQL 服务
sudo service mysql start
#使用 root 用户登录
mysql -u root
advanced_operation.sql 和 in.txt,其中第一个文件用于创建数据库并向其中插入数据,第二个文件用于测试数据导入功能。
如果你是接着上一个实验操作的话,首先把 python 数据库删掉:
mysql> drop database python;
输入命令运行第一个文件,搭建数据库并插入数据:
mysql> source /home/ubuntu/Desktop/advanced_operation.sql
6.1 索引
索引是一种与表有关的结构,它的作用相当于书的目录,可以根据目录中的页码快速找到所需的内容。
当表中有大量记录时,若要对表进行查询,没有索引的情况是全表搜索:将所有记录一一取出,和查询条件进行一一对比,然后返回满足条件的记录。这样做会消耗大量数据库系统时间,并造成大量磁盘 I/O 操作。
而如果在表中已建立索引,在索引中找到符合查询条件的索引值,通过索引值就可以快速找到表中的数据,可以 大大加快查询速度。
对一张表中的某个列建立索引,有以下两种语句格式:
alter table 表名字 add index 索引名 (列名);
create index 索引名 on 表名字 (列名);
我们用这两种语句分别建立索引:
alter table employee add index idx_id (id); #在 employee 表的 id 列上建立名为 idx_id 的索引
create index idx_name on employee (name); #在 employee 表的 name 列上建立名为 idx_name 的索引 索引的效果是加快查询速度,当表中数据不够多的时候是感受不出它的效果的。这里我们使用命令 SHOW INDEX FROM 表名字; 查看刚才新建的索引。
在使用 SELECT 语句查询的时候,语句中 WHERE 里面的条件,会 自动判断有没有可用的索引。
比如有一个用户表,它拥有用户名 (username ) 和个人签名 (note ) 两个字段。其中用户名具有唯一性,并且格式具有较强的限制,我们给用户名加上一个唯一索引;个性签名格式多变,而且允许不同用户使用重复的签名,不加任何索引。
这时候,如果你要查找某一用户,使用语句 select * from user where username=? 和 select * from user where note=? 性能是有很大差距的,对 建立了索引的用户名 进行条件查询会比 没有索引的个性签名 条件查询快几倍,在数据量大的时候,这个差距只会更大。
一些字段不适合创建索引,比如性别,这个字段存在大量的重复记录无法享受索引带来的速度加成,甚至会拖累数据库,导致数据冗余和额外的 CPU 开销。
6.2 视图
视图是从一个或多个表中导出来的表,是一种 虚拟存在的表 。它就像一个窗口,通过这个窗口可以看到系统专门提供的数据,这样,用户可以不用看到整个数据库中的数据,而只关心对自己有用的数据。
注意理解视图是虚拟的表:
- 数据库中只存放了视图的定义,而没有存放视图中的数据,这些数据存放在原来的表中;
- 使用视图查询数据时,数据库系统会从原来的表中取出对应的数据;
- 视图中的数据依赖于原来表中的数据,一旦表中数据发生改变,显示在视图中的数据也会发生改变;
- 在使用视图的时候,可以把它当作一张表。
创建视图的语句格式为:
create view 视图名(列 a, 列 b, 列 c) as select 列 1, 列 2, 列 3 from 表名字;可见创建视图的语句,后半句是一个 SELECT 查询语句,所以 视图也可以建立在多张表上 ,只需在 SELECT 语句中使用 子查询 或连接查询,这些在之前的实验已经进行过。
现在我们创建一个简单的视图,名为 v_emp,包含 v_name,v_age,v_phone 三个列:
create view v_emp (v_name,v_age,v_phone) as select name,age,phone from employee;视图的作用
- 提高了重用性,就像一个函数。如果要频繁获取 user 表的 name 和 goods 表的 name。若没有视图,就只能写一大段 sql 语句查询。而 view 则可以简单整合两个 name 到一张虚拟表里,查询简单很多。
- 对数据库重构,却不影响程序的运行。若要拆分一张表,可以视图进行虚拟拆分,又不改变原表的结构。
- 提高了安全性能。可以对不同的用户,设定不同的视图。
6.3 备份
数据库中的数据十分重要,出于安全性考虑,在数据库的使用中,应该注意使用备份功能。
备份与导出的区别:导出的文件只是保存数据库中的数据;而备份,则是把数据库的结构,包括数据、约束、索引、视图等全部另存为一个文件。
mysqldump 是 MySQL 用于备份数据库的实用程序。它主要产生一个 SQL 脚本文件,其中包含从头重新创建数据库所必需的命令 CREATE TABLE INSERT 等。
使用 mysqldump 备份的语句:
mysqldump -u root 数据库名 > 备份文件名; #备份整个数据库
mysqldump -u root 数据库名 表名字 > 备份文件名; #备份整个表
mysqldump 是一个备份工具,因此该命令是在终端中执行的,而不是在 mysql 交互环境下
我们尝试备份整个数据库 python,将备份文件命名为 bak.sql,先 Ctrl+D 退出 MySQL 控制台,再打开 Xfce 终端,在终端中输入命令:
cd /home/ubuntu/
mysqldump -u root python > bak.sql;
你可以用 gedit 查看备份文件的内容,可以看见里面不仅保存了数据,还有所备份的数据库的其他信息。
6.4 恢复
用备份文件恢复数据库,其实我们早就使用过了。在本次实验的开始,我们使用过这样一条命令:
source /home/ubuntu/Desktop/advanced_operation.sql
这就是一条恢复语句,它把 advanced_operation-06.sql 文件中保存的python 数据库恢复。
还有另一种方式恢复数据库,但是在这之前我们先使用命令新建一个 空的数据库 test:
mysql -u root -p #因为在上一步已经退出了 MySQL,现在需要重新登录
create database test; #新建一个名为 test 的数据库
再次 Ctrl+D 退出 MySQL,然后输入语句进行恢复,把刚才备份的 bak.sql 恢复到 test数据库:
mysql -u root test < bak.sql我们输入命令查看 test 数据库的表,便可验证是否恢复成功:
mysql -u root -p #因为在上一步已经退出了 MySQL,现在需要重新登录
use test #连接数据库 test
SHOW TABLES; #查看 test 数据库的表
实验总结
在本实验中,我们实践了下面几个基本概念:
- 索引:可以加快查询速度
- 视图:是一种虚拟存在的表
- 导入:从文件中导入数据到表
- 导出:从表中导出到文件中
- 备份:
mysqldump备份数据库到文件 - 恢复:从文件恢复数据库
我们将学习 MySQL 服务安装及命令使用 。
总结
查询的完整格式 不要被吓到 其实很简单 !
select select_expr [,select_expr,...] [
from tb_name
[where 条件判断]
[group by {col_name | postion} [ASC | DESC], ...]
[having where 条件判断]
[order by {col_name|expr|postion} [ASC | DESC], ...]
[limit {[offset,]rowcount | row_count OFFSET offset}]
]- 完整的 select 语句
select distinct *
from 表名
where ....
group by ... having ...
order by ...
limit start,count- 执行顺序为:
- from 表名
- where ….
- group by …
- select distinct *
- having …
- order by …
- limit start,count
- 实际使用中,只是语句中某些部分的组合,而不是全部
附录
导入数据
mysql 命令导入
>> mysql -u 用户名 -p 密码 < /home/abc/ 源.sqlsource 命令导入
mysql> source /home/abc/ 源.sql
导出数据
mysqldump 命令导出
>> mysqldump -u 用户名 -p 密码 数据库名 表名 > 导出文件路径select … into outfile 命令导出
select * from 表名 into outfile 导出文件路径
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net