1、Mysql 数据库
MySQL 是一个 DBMS(数据库管理系统),由瑞典 MySQLAB 公司开发,目前属于 Oracle (甲骨文) 公司,MySQL 是最流行的关系型数据库管理系统(关系数据库,是建立在关系数据库模型基础上的数据库,借助于集合代数等概念和方法来处理数据库中的数据)。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发者都选择 MySQL 作为网站数据库。MySQL 使用 SQL 语言进行操作。
菜鸟教程:https://www.runoob.com/mysql/mysql-administration.html
概念对比
- DB:数据库,存放数据的容器
- DBMS:数据库管理系统,用于管理 DB
- SQL:结构化查询语言,是关系型数据库的通用语言
RDBMS 术语
在我们开始学习 MySQL 数据库前,让我们先了解下 RDBMS 的一些术语:
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(= 元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
1.1 创建
1.1.1 创建数据库
创建一个数据库,给它一个名字,比如 python,以后的几次操作也是对 python 这个数据库进行操作。 语句格式为 CREATE DATABASE < 数据库名字 >;,(注意不要漏掉分号 ;),前面的 CREATE DATABASE 也可以使用小写,具体命令为:
-- create database 数据库名 charset=utf8;
-- 例:
create database python charset=utf8;接下来的操作,就在刚才创建的 python 中进行,由于一个系统中可能会有多个数据库,要确定当前是对哪一个数据库操作,使用语句 use < 数据库名字 >:
mysql> use python;1.1.2 创建数据表
数据表(table)简称表,它是数据库最重要的组成部分之一。数据库只是一个框架,表才是实质内容。
而一个数据库中一般会有多张表,这些各自独立的表通过建立关系被联接起来,才成为可以交叉查阅、一目了然的数据库。
如下便是一张表:
| ID | name | phone |
|---|---|---|
| 01 | Tom | 110110110 |
| 02 | Jack | 119119119 |
| 03 | Rose | 114114114 |
在数据库中新建一张表的语句格式为:
CREATE TABLE 表的名字 (列名 a 数据类型(数据长度), 列名 b 数据类型(数据长度)); 我们尝试在 python 中新建一张表 employee,包含姓名,ID 和电话信息,所以语句为:
mysql> CREATE TABLE employee (id int(10),name char(20),phone int(12));
Query OK, 0 rows affected (0.00 sec)1.2 Pymysql 操作数据库
PymySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库。

使用 pip install pymysql 可以直接安装。
1.2.1 数据库操作方法
connect()链接数据库
close()发送数据关闭与数据库的链接
commit()提交并保存数据
cursor(cursor=None)创建一个新游标,用于执行 sql 语句并获得结果
rollback()回滚当前事务。
select_db(db)设置当前数据库。
参数:db – 数据库的名称.
1.2.1 连接数据库
连接数据库对象:调用 pymysql.connect() 方法
import pymysql
conn=pymysql.connect(参数列表)参数:
- host - 数据库服务器所在的主机
- user - 登录的用户名
- password - 要使用的密码。
- database - 要使用的数据库,None 不使用特定的数据库。
- port - 要使用的 MySQL 端口,默认通常都可以。(默认值:3306)
- charset - 你要使用的 Charset。
- db - 数据库的别名。(与 MySQLdb 兼容)
- passwd - 密码的别名。(与 MySQLdb 兼容)
import pymysql
conn=pymysql.connect(
host='localhost',
port=3306,
database='python',
user='root',
password='123456',
)
print(conn)
// 输出结果如下:
<pymysql.connections.Connection object at 0x0000018E4F185CF8> // 表示连接成功
1.2.2 执行 sql 命令
执行 sql 命令,需要调用 Connection 对象的 cursor() 方法创建一个游标(Cursor)对象。
获取 Cursor 对象:
cursor = conn.cursor()使用 excute 执行查询指令
sql = ' 需要执行的命令 '
cursor.excute(sql)如:
cursor=conn.cursor()
tables_count=cursor.execute('show tables;') // 查看有多少数据表1.2.3 游标对象
close()关闭游标对象。
execute(query, args=None)执行查询
参数:
query (str) – 查询执行。
Returns(返回内容): 受影响的行数
Return type: int
返回受影响的行数,主要用于执行 insert、update、delete 语句,也可以执行 create、alter、drop 等语句
如果 args 是列表或元组,则%s 可以用作查询中的占位符。如果 args 是 dict,则%(name)s 可以用作查询中的占位符。
executemany(query, args)执行多个查询
参数
query –查询在服务器上执行
args –序列或映射的序列。它用作参数。
此方法可提高多行 INSERT 和 REPLACE 的性能。否则它等同于使用 execute()循环遍历 args。
fetchall()执行查询时,获取结果集的所有行,一行构成一个元组,再将这些元组装入一个元组返回
fetchmany(size=None)获取几行
fetchone()执行查询语句时,获取查询结果集的第一个行数据,返回一个元组
1.3 插入数据
使用游标向数据库插入数据
# 插入一条数据
one_data = "insert into goods values(0,'ipad mini 配备 retina 显示屏 ',' 平板电脑 ',' 苹果 ','2788',default,default); "
cursor.execute(one_data)回滚
try:
# 执行 SQL 语句
cursor.execute("insert into goods values(0,'ipad mini 配备 retina 显示屏 ',' 平板电脑 ',' 苹果 ','2788',default,default); ")
# 提交事务
conn.commit()
except Exception as e:
# 有异常,回滚事务
conn.rollback()
cursor.close()
conn.close()1.3.1 案例
事先使用 mysql 在 python 这个数据库里创建一个表,名为“maoyan”,并指定列名。
create database python character set utf8;
use python;
create table maoyan(moive_name varchar(10) primary key,
star varchar(30) ,
relasetime varchar(20) ,
scores char(3)
) character set utf8;
然后在代码框操作:
import pymysql
list = [(' 主演:秦岚, 糸井重里, 岛本须美 ', ' 龙猫 ', ' 上映时间:2018-12-14', '9.1'),
(' 主演:张国荣, 张曼玉, 刘德华 ', ' 阿飞正传 ', ' 上映时间:2018-06-25', '8.8'),
(' 主演:俞承豪, 金艺芬, 童孝熙 ', ' 爱·回家 ', ' 上映时间:2002-04-05(韩国)', '9.0'),
(' 主演:雅克·贝汉, 姜文, 兰斯洛特·佩林 ', ' 海洋 ', ' 上映时间:2011-08-12', '9.0'),
(' 主演:宋在浩, 李顺才, 尹秀晶 ', ' 我爱你 ', ' 上映时间:2011-02-17(韩国)', '9.0'),
(' 主演:克林特·伊斯特伍德, 李·范·克里夫, 埃里·瓦拉赫 ', ' 黄金三镖客 ', ' 上映时间:1966-12-23(意大利)', '8.9'),
(' 主演:雅克·贝汉,Philippe Labro', ' 迁徙的鸟 ', ' 上映时间:2001-12-12(法国)', '9.1'),
(' 主演:柊瑠美, 周冬雨, 入野自由 ', ' 千与千寻 ', ' 上映时间:2019-06-21', '9.3'),
(' 主演:蒂姆·罗斯, 比尔·努恩, 普路特·泰勒·文斯 ', ' 海上钢琴师 ', ' 上映时间:2019-11-15', '9.3'),
(' 主演:菲利浦·诺瓦雷, 赛尔乔·卡斯特利托, 蒂兹亚娜·罗达托 ', ' 天堂电影院 ', ' 上映时间:2019-06-15', '9.2')]
conn=pymysql.connect(
host='localhost',
port=3306,
database='python',
user='root',
password='123456',
)
cursor=conn.cursor()
for i in list:
try:
sql="insert into python.maoyan (star,moive_name,relasetime,scores) values ('%s','%s','%s','%s')" % i
cursor.execute(sql)
except Exception as e:
conn.rollback()
conn.commit()
cursor.close()
conn.close()1.4 查询数据
cursor.execute("select * from maoyan")
one = cursor.fetchone() // 读取一条数据
print(one)
all = cursor.fetchall() // 读取所有数据
print(all)1.4.1 查询一行数据
cs1 = conn.cursor()
count = cs1.execute('select id,name from goods where id>=4')
print(" 查询到 %d 条数据:" % count) # 打印受影响的行数
for i in range(count):
result = cs1.fetchone()
print(result)
cs1.close()
conn.close()1.4.2 查询多行数据
cs1 = conn.cursor()
count = cs1.execute('select id,name from goods where id>=4')
print(" 查询到 %d 条数据:" % count)
result = cs1.fetchall()
print(result)
cs1.close()
conn.close()1.5 修改数据
cs1 = conn.cursor()
count = cs1.execute('insert into goods_cates(name) values(" 硬盘 ")')
print(count)
count = cs1.execute('insert into goods_cates(name) values(" 光盘 ")')
print(count)
conn.commit()
cs1.close()
conn.close()1.6 参数化
sql 语句的参数化,可以有效防止 sql 注入。
注意:此处不同于 python 的字符串格式化,全部使用 %s 占位。
非安全方式:
from pymysql import *
def main():
find_name = input(" 请输入物品名称:")
conn = connect(host='localhost',
port=3306,user='root',
password='mysql',
database='jing_dong',
charset='utf8')
cs1 = conn.cursor()
sql = 'select * from goods where name="%s"' % find_name
result = cs1.execute(sql).fetchone
print(rsult)
if __name__ == '__main__':
main()
// 在 `input` 时输入 `" or 1=1 or "`,会查询到所有数据,会造成信息泄露。安全的方式:
params = [find_name] // 把传入的 find_name 变成这样的
# 如果要是有多个参数,需要进行参数化
# 那么 params = [数值 1, 数值 2....],此时 sql 语句中有多个 %s 即可
cs1.execute('select * from goods where name=%s', params)
result = cs1.fetchone()
print(result)
cs1.close()
conn.close()1.7 面向对象检索数据
import pymysql
class MaoYanDB:
def __init__(self):
pass
def show_all_info(self):
""" 显示所有商品信息 """
# 获取连接
connection = pymysql.connect(host='localhost',
port=3306,user='root',
password='mysql',
database='jing_dong',
charset='utf8' # 编码
)
cursor = connection.cursor()
""" 显示所有商品分类 """
sql = "select * from goods;"
cursor.execute(sql)
for temp in cursor.fetchall():
print(temp)
cursor.close()
connection.close()
def show_names(self):
""" 返回所有电影的名字 """
connection = pymysql.connect(host='localhost',
port=3306,user='root',
password='mysql',
database='jing_dong',
charset='utf8' # 编码
)
sql = "select movie_name from maoyan;"
cursor = connection.cursor()
cursor.execute(sql)
for temp in cursor.fetchall():
print(temp)
cursor.close()
connection.close()
if __name__ == '__main__':
my = MaoYanDB()
my.show_names()
封装重构之后
import pymysql
class MaoYanDB:
def __init__(self):
self.connection = pymysql.connect(host='localhost',
port=3306,user='root',
password='mysql',
database='jing_dong',
charset='utf8' # 编码
)
self.cursor = self.connection.cursor()
def show_all_info(self):
""" 显示所有商品信息 """
""" 显示所有商品分类 """
sql = "select * from goods;"
self.cursor.execute(sql)
for temp in self.cursor.fetchall():
print(temp)
self.cursor.close()
def show_names(self):
""" 返回所有电影的名字 """
sql = "select movie_name from maoyan;"
self.cursor.execute(sql)
for temp in self.cursor.fetchall():
print(temp)
if __name__ == '__main__':
my = MaoYanDB()
my.show_names()
2、ORM
面向对象编程把所有实体看成对象(object),关系型数据库则是采用实体之间的关系(relation)连接数据。很早就有人提出,关系也可以用对象表达,这样的话,就能 使用面向对象编程,来操作关系型数据库。
ORM 全称 Object Relational Mapping, 翻译过来叫 对象关系映射 。简单的说,ORM 将数据库中的表与面向对象语言中的类建立了一种对应关系。这样,我们要操作数据库,数据库中的表或者表中的一条记录就可以直接通过操作类或者类实例来完成。
- 学会用 SQLALchemy 连接数据库(MySQL, SQLite, PostgreSQL), 创建数据表;
- 掌握表数据之间一对一,一对多及多对多的关系并能转化为对应 SQLAlchemy 描述;
- 掌握使用 SQLAlchemy 进行 CURD 操作;
- 学会使用 Faker 生成测试数据
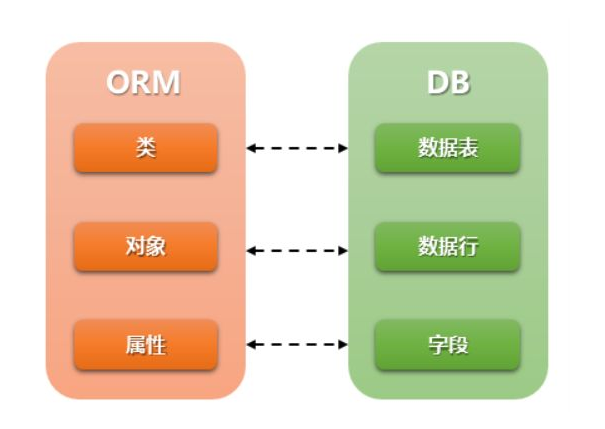
要实现 MySQL 数据表到 Python 类的映射,就需要 ORM 框架的帮助。在 Python 中有多个选择,例如轻量的 SQLobject 框架、Storm 框架、Django 内置的 ORM、著名的 SQLAlchemy 以及基于前者的 flask 插件 flask-SQLAlchemy 等。
SQLAlchemy 是 Python 社区最知名的 ORM 工具之一,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。
接下来我们将学习 SQLAlchemy 的使用。先安装 SQLAlchemy:
$ sudo pip install sqlalchemy2.1 创建连接
2.1.1 创建引擎
使用 SQLAlchemy 连接数据库需要引擎,创建引擎使用 create_engine 方法:
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://windows:123456@192.168.31.206:3306/study?charset=utf8')注意这里创建引擎的格式:
数据库类型 + 驱动:// 用户名: 密码 @主机: 端口号 / 数据库名字?charset= 编码格式
链接其他数据库
- Postgres:
postgresql://scott:tiger@localhost/mydatabase- MySQL:
mysql://scott:tiger@localhost/mydatabase- Oracle:
oracle://scott:tiger@127.0.0.1:1521/sidname- SQLite (注意开头的四个斜线):
sqlite:////absolute/path/to/foo.db这里不同数据库创建引擎的格式不一样,但是后续创建表和查询模式都一样。
下面还是回到 Mysql 为例介绍。
2.1.2 基类
创建映射类需要继承声明基类,使用 declarative_base :
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base(engine)2.1.3 会话
from sqlalchemy.orm import sessionmaker
session = sessionmaker(engine)()当我们创建了 session 实例,就启动了一个操作 MySQL 数据库的会话。对 数据库进行了连接。
2.2 创建数据
2.2.1 映射类
一对一对象
首先 创建 user 数据表 的映射类,此表存放用户数据。
from sqlalchemy import Column, Integer, String
class User(Base): // 创建映射类须继承声明基类
__tablename__ = 'user' // 设置数据表名字,不可省略
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False)
email = Column(String(64), unique=True)
# 此特殊方法定义实例的打印样式
def __repr__(self):
return '<User: {}>'.format(self.name)在 User 类中,用 __tablename__ 指定在 MySQL 中表的名字。我们创建了三个基本字段,类中的每一个 Column 代表数据库中的一列,在 Colunm中,指定该列的一些配置。第一个字段代表类的数据类型,上面我们使用 String, Integer 俩个最常用的类型,其他常用的包括:
Text
Boolean
SmallInteger
DateTime另外定义 __repr__ 是为了方便调试,你可以不定义,也可以定义的更详细一些。
一对多对象
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship, backref
class Course(Base):
__tablename__ = 'course'
id = Column(Integer, primary_key=True)
name = Column(String(64))
user_id = Column(Integer, ForeignKey('user.id', ondelete='CASCADE'))
//ForeignKey 设置外键关联,第一个参数为字符串,user 为数据表名,id 为字段名
// 第二个参数 ondelete 设置删除 User 实例后对关联的 Course 实例的处理规则
//'CASCADE' 表示级联删除,删除用户实例后,对应的课程实例也会被连带删除
user = relationship('User',
backref=backref('course', cascade='all, delete-orphan'))
//relationship 设置查询接口,以便后期进行数据库查询操作
// 第一个参数为位置参数,参数值为外键关联的映射类名,数据类型为字符串
// 第二个参数 backref 设置反向查询接口
//backref 的第一个参数 'course' 为查询属性,User 实例使用该属性可以获得相关课程实例的列表
//backref 的第二个参数 cascade 如此设置即可实现 Python 语句删除用户数据时级联删除课程数据
def __repr__(self):
return '<Course: {}>'.format(self.name)定义列时常用参数表:
| 参数 | 说明 |
|---|---|
| primary_key | 如果设为 True,这列就是表的主键 |
| unique | 默认值为 False,如果设为 True,这列不允许出现重复的值 |
| index | 如果设为 True,为这列创建索引,提升查询效率 |
| nullable | 默认值为 True,这列允许使用空值;如果设为 False,这列不允许使用空值 |
| default | 为这列定义默认值 |
常用的 SQLAlchemy 查询关系选项(在 backref 中使用):
| 选项 | 说明 |
|---|---|
| backref | 在关系的另一个映射类中添加反向引用 |
| lazy | 指定如何加载查询记录。可选值有 select (首次访问时按需加载)、immediate (源对象加 载后就加载)、joined (加载记录,但使用联结), noload (永不加载)和 dynamic (不加载记录,但提供加载记录的查询,比较常用) |
| cascade | 设置级联删除的方式 |
| uselist | 如果设为 Fales,查询结果不使用列表,而使用映射类实例(下节课程会用到) |
| order_by | 指定查询记录的排序方式 |
| secondary | 指定多对多关系中关系表的名字(下节课程会用到) |
2.2.2 创建数据表
声明基类 Base 在创建之后并不会主动连接数据库,因为它的默认设置为惰性模式。Base 的 metadata 有个 create_all 方法,执行此方法会主动连接数据库并创建全部数据表,完成之后自动断开与数据库的连接:
Base.metadata.create_all()完整代码
总结以上内容,写入 db.py 文件:
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship, backref
engine = create_engine('mysql://root@localhost/study?charset=utf8')
Base = declarative_base(engine)
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False)
email = Column(String(64), unique=True)
def __repr__(self):
return '<User: {}>'.format(self.name)
class Course(Base):
__tablename__ = 'course'
id = Column(Integer, primary_key=True)
name = Column(String(64))
user_id = Column(Integer, ForeignKey('user.id', ondelete='CASCADE'))
user = relationship('User',
backref=backref('course', cascade='all, delete-orphan'))
def __repr__(self):
return '<Course: {}>'.format(self.name)
if __name__ == '__main__':
Base.metadata.create_all() // 创建数据表运行后就可以看到数据库生成了数据库模型。
2.3 生成测试数据
2.3.1 添加测试数据
测试数据的创建需要用到 Python 的 faker 库,使用 pip 安装先:
pip install faker终端执行 ipython 命令,即可进入命令行交互解释器:
In [38]: from faker import Faker # 引入 Faker 类
# 创建实例,添加参数 'zh-cn' 是为了伪造中文数据
# 该实例叫做工厂对象,它可以使用各种各样的方法伪造数据
In [39]: fake = Faker('zh-cn')
In [40]: fake.name() # 伪造姓名
Out[40]: ' 房明 '
In [41]: fake.address() # 伪造地址
Out[41]: ' 山西省梅市上街董路 Q 座 238175'
In [42]: fake.email() # 伪造邮箱
Out[42]: 'oqiu@rn.net'
In [43]: fake.url() # 伪造 URL
Out[43]: 'https://www.yuzhu.cn/'
In [44]: fake.date() # 伪造日期
Out[44]: '2012-07-03'
创建实例:
接下来创建 5 个课程用户,也就是 5 个 User 类的实例,每个用户对应两个课程,共 10 个 Course 类实例。将以下代码写入测试数据的 Python 文件中,文件名为 create_data.py :
from sqlalchemy.orm import sessionmaker
from faker import Faker
from db import Base, engine, User, Course
session = sessionmaker(engine)()
fake = Faker('zh-cn')
def create_users():
for i in range(10):
# 创建 10 个 User 类实例,伪造 name 和 email
user = User(name=fake.name(), email=fake.email())
# 将实例添加到 session 会话中,以备提交到数据库
# 注意,此时的 user 对象没有 id 属性值
# 映射类的主键字段默认从 1 开始自增,在传入 session 时自动添加该属性值
session.add(user)
def create_courses():
# session 有个 query 方法用来查询数据,参数为映射类的类名
# all 方法表示查询全部,这里也可以省略不写
# user 就是上一个函数 create_users 中的 user 对象
for user in session.query(User).all():
# 两次循环,对每个作者创建两个课程
for i in range(2):
# 创建课程实例,name 的值为 8 个随机汉字
course = Course(name=''.join(fake.words(4)), user_id=user.id)
session.add(course)
def main():
# 执行两个创建实例的函数,session 会话内就有了这些实例
create_users()
create_courses()
# 执行 session 的 commit 方法将全部数据提交到对应的数据表中
session.commit()
if __name__ == '__main__':
main()
2.3.2 测试
完成后,可以在终端执行 python3 create_data.py 来创建数据。为了便于查看代码的执行情况,不这样做,我们在 ipython 中引入这些函数,依次执行它们来查看细节:
# 引入相关对象
In [1]: from create_data import User, Course, session, create_users, create_courses
# 执行创建 User 实例的函数
In [2]: create_users()
# session 查询结果为列表,每个元素就是一个 User 实例
In [3]: session.query(User).all()
Out[3]:
[<User: 安颖 >,
<User: 赵琴 >,
<User: 李英 >,
<User: 邢想 >,
<User: 高玲 >,
<User: 戴晶 >,
<User: 卢建平 >,
<User: 陈强 >,
<User: 姜帆 >,
<User: 包柳 >]
# 将某个 User 实例赋值给 user 变量
In [4]: user = session.query(User).all()[3]
# 查看属性
In [5]: user.name
Out[5]: ' 邢想 '
In [6]: user.id
Out[6]: 4
# 执行创建 Course 实例的函数
In [7]: create_courses()
# 查看前 4 个 Course 实例的 name 属性
In [8]: for course in session.query(Course)[:4]:
...: print(course.name)
...:
开发中文电子新闻
怎么发布结果详细
你的只要非常如果
次数通过评论等级
# User 实例的 course 属性为查询接口,通过 relationship 设置
# 属性值为列表,里面是两个课程实例
In [9]: user.course
Out[9]: [<Course: 上海这么国际时候 >, <Course: 对于技术两个你们 >]
# 将某个课程实例赋值给 course 变量
In [10]: course = session.query(Course)[12]
# 课程实例的 user 属性为查询接口,通过 relationship 设置
In [11]: course.user
Out[11]: <User: 卢建平 >
# 将全部实例提交到对应的数据表
In [12]: session.commit()
In [13]:
查看 MySQL 数据库中各表的数据:
mysql> SELECT * FROM user;
+----+-----------+----------------------+
| id | name | email |
+----+-----------+----------------------+
| 1 | 安颖 | fanxiuying@weiyin.cn |
| 2 | 赵琴 | tao10@hotmail.com |
| 3 | 李英 | xia68@gangqiang.cn |
| 4 | 邢想 | minyi@yahoo.com |
| 5 | 高玲 | maoqiang@pa.cn |
| 6 | 戴晶 | xlin@yahoo.com |
| 7 | 卢建平 | dqian@yahoo.com |
| 8 | 陈强 | yuanjun@guiying.cn |
| 9 | 姜帆 | xiayan@tx.cn |
| 10 | 包柳 | qiang78@hotmail.com |
+----+-----------+----------------------+
10 rows in set (0.00 sec)
mysql> SELECT * FROM course;
+----+--------------------------+---------+
| id | name | user_id |
+----+--------------------------+---------+
| 1 | 开发中文电子新闻 | 1 |
| 2 | 怎么发布结果详细 | 1 |
| 3 | 你的只要非常如果 | 2 |
| 4 | 次数通过评论等级 | 2 |
| 5 | 经验方式文件根据 | 3 |
| 6 | 资料你们各种类别 | 3 |
| 7 | 上海这么国际时候 | 4 |
... ...
+----+--------------------------+---------+
20 rows in set (0.00 sec)
接下来我们在 ipython 中删除 user 实例,验证级联删除功能是否生效:
In [13]: session.delete(user)
In [14]: session.commit()
In [15]:查看数据表的情况,一如预期,user 表中 id 为 4 的行被删除,course 表中 user_id 为 4 的行也被删除:
mysql> SELECT * FROM user;
+----+-----------+----------------------+
| id | name | email |
+----+-----------+----------------------+
| 1 | 安颖 | fanxiuying@weiyin.cn |
| 2 | 赵琴 | tao10@hotmail.com |
| 3 | 李英 | xia68@gangqiang.cn |
| 5 | 高玲 | maoqiang@pa.cn |
| 6 | 戴晶 | xlin@yahoo.com |
| 7 | 卢建平 | dqian@yahoo.com |
| 8 | 陈强 | yuanjun@guiying.cn |
| 9 | 姜帆 | xiayan@tx.cn |
| 10 | 包柳 | qiang78@hotmail.com |
+----+-----------+----------------------+
9 rows in set (0.00 sec)
mysql> SELECT * FROM course WHERE user_id = 4;
Empty set (0.00 sec)
mysql>
2.4 关系
2.4.1 一对一关系
本节我们来学习创建一对一、多对多关系的数据表。为了方便演示,假设我们的每个课程只有一个实验,我们要创建映射类 Lab 和表 lab,课程和实验就是一对一的关系,如何实现这种关系呢?把 lab 的主键 id 设置为外键关联到 course 的主键 id 即可,因为主键是自带唯一约束的,这样就实现了一对一关系。
创建映射类 Lab,将以下代码写入 db.py 文件:
class Lab(Base):
tablename = 'lab'
# 设置主键为外键,关联 course 表的 id 字段
# 注意参数顺序,先定义外键,再定义主键
id = Column(Integer, ForeignKey('course.id'), primary_key=True)
name = Column(String(128))
# 设置查询接口,Lab 实例的 course 属性值为 Course 实例
# Course 实例的 lab 属性值默认为列表,列表中有一个 Lab 实例
# uselist 参数可以设置 Course 实例的 lab 属性值为 Lab 实例而非列表
course = relationship('Course', backref=backref('lab', uselist=False))
def __repr__(self):
return '<Lab: {}>'.format(self.name)
保存代码后,在终端运行文件即可生成数据表:
$ python db.py查看数据库:
mysql> SHOW TABLES;
+-----------------+
| Tables_in_study |
+-----------------+
| course |
| lab |
| user |
+-----------------+
3 rows in set (0.00 sec)
接下来创建多对多关系的数据表,然后再一并生成测试数据。
2.4.2 多对多关系
一个课程可以有多个标签,每个标签可以贴在多个课程上,我们需要实现 course 课程表和 tag 标签表的多对多关系。
- 一对多关系:一个 User 实例(课程教师)对应多个 Course 实例,一个 Course 实例对应一个 User 实例。
- 一对一关系:一个 Course 实例对应一个 Lab 实例,一个 Lab 实例对应一个 Course 实例。
- 多对多关系:一个 Course 实例对应多个 Tag 实例,一个 Tag 实例对应多个 Course 实例。
满足上述需求的多对多关系,需要在创建 Tag 映射类之前,首先创建中间表的映射类,用 Table 这个特殊类创建,此类的实例就是映射类。
将以下代码写入 db.py 文件中:
# 引入 Table 类
from sqlalchemy import Table
# 创建 Table 类的实例,即中间表映射类,赋值给变量 Rela
# 该类在实例化时,接收 4 个参数:
# 1、数据表名字 2、Base.metadata
# 3 和 4、两个 Column(列名,数据类型,外键,主键)
Rela = Table('rela', Base.metadata,
Column('tag_id', Integer, ForeignKey('tag.id'), primary_key=True),
Column('course_id', Integer, ForeignKey('course.id'), primary_key=True)
)
有了中间表的映射类,就可以创建 tag 表的映射类 Tag 了,将以下代码写入 db.py 文件中:
class Tag(Base):
__tablename__ = 'tag'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True)
# 设置查询接口,secondary 指定多对多关系的中间表,注意数据类型不是字符串
course = relationship('Course', secondary=Rela, backref='tag')
def __repr__(self):
return '<Tag: {}>'.format(self.name)
同样地,终端运行文件生成数据表:
$ python db.py
-- 查看数据库中的数据表:
mysql> SHOW TABLES;
+-----------------+
| Tables_in_study |
+-----------------+
| course |
| lab |
| rela |
| tag |
| user |
+-----------------+
5 rows in set (0.00 sec)
注意中间表是真实存在的数据表,它有两个字段,当我们给课程添加标签时,该表会记录相关信息:
mysql> DESC rela;
+-----------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------+------+-----+---------+-------+
| tag_id | int(11) | NO | PRI | NULL | |
| course_id | int(11) | NO | PRI | NULL | |
+-----------+---------+------+-----+---------+-------+
2 rows in set (0.00 sec)
2.5 完善创建
2.5.1 增加数据
下面对 create_data.py 文件补充一些代码,我们用 10 个随机中文汉字作为 lab 表的 name 字段的值,创建 20 个 Lab 类的实例,10 个 Tag 类的实例,补充代码如下:
from db import Lab, Tag
def create_labs():
for course in session.query(Course):
lab = Lab(name=''.join(fake.words(5)), id=course.id)
session.add(lab)
def create_tags():
for name in ['python', 'linux', 'java', 'mysql', 'lisp']:
tag = Tag(name=name)
session.add(tag)
启动命令行交互解释器 ipython,引入相关对象,执行创建数据的函数:
In [1]: from create_data import *
In [2]: create_labs()
In [3]: create_tags()
In [4]: session.commit()
查看数据库内数据:
mysql> SELECT * FROM lab;
+----+--------------------------------+
| id | name |
+----+--------------------------------+
| 1 | 北京联系其中准备技术 |
| 2 | 影响一样来源已经有些 |
| 3 | 建设研究工作那些我的 |
| 4 | 可是注册显示应该学生 |
| 5 | 起来决定不要企业资料 |
| 6 | 国内电子基本类型的人 |
| 9 | 方式一般的话具有系列 |
| 10 | 基本当然是否个人政府 |
| 11 | 其他教育你的类别更新 |
| 12 | 世界很多之后世界推荐 |
| 13 | 一直方法完全注意事情 |
| 14 | 大学不过认为世界应用 |
| 15 | 这么说明什么文化一个 |
| 16 | 状态阅读包括资料那么 |
| 17 | 作者继续作者人员对于 |
| 18 | 地区原因我的不断评论 |
| 19 | 基本环境表示我们情况 |
| 20 | 但是就是根据活动留言 |
+----+--------------------------------+
18 rows in set (0.00 sec)
mysql> SELECT * FROM tag;
+----+--------+
| id | name |
+----+--------+
| 1 | java |
| 2 | linux |
| 3 | lisp |
| 4 | mysql |
| 5 | python |
+----+--------+
5 rows in set (0.00 sec)
2.5.2 给课程添加标签
课程实例有 tag 属性,这是在映射类中设置的查询接口,标签实例也有对应的查询接口 course,它们的属性值均为空列表,如果要给课程添加标签,只需将标签实例添加到 tag 属性的列表中,给标签添加课程同理,举例如下:
# 通过查询将两个课程实例赋值给变量 c1 c2 ,将两个标签实例赋值给 t1 t2
In [6]: c1 = session.query(Course)[3]
In [7]: c2 = session.query(Course)[11]
In [8]: t1 = session.query(Tag)[1]
In [9]: t2 = session.query(Tag)[2]
# 课程的 tag 属性默认为空列表
In [10]: c1.tag
Out[10]: []
# 将标签实例添加到列表
In [11]: c1.tag.append(t1)
In [12]: c1.tag.append(t2)
# 标签的 course 属性里就有了对应的课程实例
In [13]: t1.course
Out[13]: [<Course: 次数通过评论等级 >]
# 当然了,课程实例的 tag 属性里有了两个标签实例
In [14]: c1.tag
Out[14]: [<Tag: linux>, <Tag: lisp>]
In [15]: t2.course.append(c2)
In [16]: c2.tag
Out[16]: [<Tag: lisp>]
# 执行 session.commit() 即可将它们的关系传入数据库中
In [17]: session.commit()
In [18]:
查看数据库的中间表,可以看到给课程添加标签后,每组关系都被保存在该表中:
mysql> SHOW TABLES;
+-----------------+
| Tables_in_study |
+-----------------+
| course |
| lab |
| rela |
| tag |
| user |
+-----------------+
5 rows in set (0.00 sec)
mysql> SELECT * FROM rela;
+--------+-----------+
| tag_id | course_id |
+--------+-----------+
| 2 | 4 |
| 3 | 4 |
| 3 | 14 |
+--------+-----------+
3 rows in set (0.00 sec)
2.6 完整代码
以上课程中我们写了两个 Python 脚本。在 db.py 中创建了 User、Course、Lab、Tag 4 个映射类 + 1 个中间表的映射类 Rela,其中包含了数据表的一对多、一对一、多对多关系;在 create_data.py 脚本中编写了向数据表中添加测试数据的代码,为了方便演示,并未在终端使用 Python 解释器执行此文件。
下面是两个 Python 脚本的完整代码,供大家测试使用:
# File Name: db.py
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey, Table
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship, backref
engine = create_engine('mysql://root@localhost/study?charset=utf8')
Base = declarative_base(engine)
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False)
email = Column(String(64), unique=True)
def __repr__(self):
return '<User: {}>'.format(self.name)
// 以下创建四个数据表
class Course(Base):
__tablename__ = 'course'
id = Column(Integer, primary_key=True)
name = Column(String(64))
user_id = Column(Integer, ForeignKey('user.id', ondelete='CASCADE'))
user = relationship('User',
backref=backref('course', cascade='all, delete-orphan'))
def __repr__(self):
return '<Course: {}>'.format(self.name)
class Lab(Base):
__tablename__ = 'lab'
id = Column(Integer, ForeignKey('course.id'), primary_key=True)
name = Column(String(128))
course = relationship('Course', backref=backref('lab', uselist=False))
def __repr__(self):
return '<Lab: {}>'.format(self.name)
Rela = Table('rela', Base.metadata,
Column('tag_id', Integer, ForeignKey('tag.id'), primary_key=True),
Column('course_id', Integer, ForeignKey('course.id'), primary_key=True)
)
class Tag(Base):
__tablename__ = 'tag'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True)
course = relationship('Course', secondary=Rela, backref='tag')
def __repr__(self):
return '<Tag: {}>'.format(self.name)
if __name__ == '__main__':
Base.metadata.create_all()# File Name: create_data.py
from sqlalchemy.orm import sessionmaker
from faker import Faker
from db import engine, User, Course, Lab, Tag
session = sessionmaker(engine)()
fake = Faker('zh-cn')
def create_users():
for i in range(10):
user = User(name=fake.name(), email=fake.email())
session.add(user)
def create_courses():
for user in session.query(User).all():
for i in range(2):
course = Course(name=''.join(fake.words(4)), user=user)
session.add(course)
def create_labs():
for course in session.query(Course):
lab = Lab(name=''.join(fake.words(5)), id=course.id)
session.add(lab)
def create_tags():
for name in ['python', 'linux', 'java', 'mysql', 'lisp']:
tag = Tag(name=name)
session.add(tag)
def main():
create_users()
create_courses()
create_labs()
create_tags()
session.commit()
if __name__ == '__main__':
main()
总结
本节课程中讲解了一对一、多对多关系的数据表创建流程,并且已经嵌入了 session 增删改查的操作讲解,下面一节课程我们针对“查”进行详细的介绍。
2.7 查询
本节主要讲解 SQLAlchemy 的查询方法,讲解主要基于前两节的数据。通常我们对数据库的使用主要有三步:创建数据表,添加数据,查询数据。前两节完成了前两步的介绍,接下来我们针对查询尤其是过滤查询进行深入探讨。
首先在 MySQL 客户端中删除数据库 study 并重建:
mysql> DROP SCHEMA IF EXISTS study; # SCHEMA 等同于 DATABASE
Query OK, 5 rows affected (0.23 sec)
mysql> CREATE SCHEMA study CHARACTER SET = UTF8;
Query OK, 1 row affected, 1 warning (0.06 sec)
mysql>
然后在终端命令行执行 Python 脚本创建数据表、添加数据,脚本代码参见上一节文档:
$ python db.py
$ python create_data.py
2.7.1 基本查询语句
我们使用命令行交互解释器 ipython 来学习查询语句:
# 首先从 create_data.py 中引入所需对象
In [1]: from create_data import session, User, Course, Lab, Tag
# session 的 query 方法接收类作为参数,.all 表示获取全部实例
# 不论查询结果是一个还是多个,返回值都是列表,查不到的话返回值是空列表
# 等同于 MySQL 语句:SELECT * FROM user;
In [2]: session.query(User).all()
Out[2]:
[<User: 王雷 >,
<User: 朱华 >,
<User: 汪林 >,
<User: 夏晶 >,
<User: 蒋桂珍 >,
<User: 宁兵 >,
<User: 梁龙 >,
<User: 李博 >,
<User: 段欣 >,
<User: 刘文 >]
# 查询第一条数据
In [3]: session.query(User).first()
Out[3]: <User: 王雷 >
# filter 方法过滤查询
In [4]: session.query(User).filter(User.name==' 王雷 ').first()
Out[4]: <User: 王雷 >
# filter_by 方法也是常用的过滤方法,且写法更为简洁
In [5]: session.query(User).filter_by(name=' 王雷 ').first()
Out[5]: <User: 王雷 >
# filter 方法支持 >、>=、<、<=、==、!= 等比较符号
In [6]: session.query(User).filter(User.name!=' 王雷 ').all()
Out[6]:
[<User: 朱华 >,
<User: 汪林 >,
<User: 夏晶 >,
<User: 蒋桂珍 >,
<User: 宁兵 >,
<User: 梁龙 >,
<User: 李博 >,
<User: 段欣 >,
<User: 刘文 >]
In [7]: session.query(User).filter(User.id>=6).all()
Out[7]: [<User: 宁兵 >, <User: 梁龙 >, <User: 李博 >, <User: 段欣 >, <User: 刘文 >]
# filter_by 方法支持多条件查询
In [8]: session.query(User).filter_by(name=' 王雷 ', id=1).all()
Out[8]: [<User: 王雷 >]
# 查询 User 表中全部数据的 name 值
In [9]: session.query(User.name).all()
Out[9]:
[(' 刘文 '),
(' 夏晶 '),
(' 宁兵 '),
(' 朱华 '),
(' 李博 '),
(' 梁龙 '),
(' 段欣 '),
(' 汪林 '),
(' 王雷 '),
(' 蒋桂珍 ')]
# 注意上一个命令的查询结果列表中每个元素的数据类型是 namedtuple
# 当然也可以理解为元组,取下标为 0 的元素就是 name 值
In [10]: for i in session.query(User.name).all():
...: print(i)
...: print(i.name)
...:
(' 刘文 ',)
刘文
(' 夏晶 ',)
夏晶
(' 宁兵 ',)
宁兵
(' 朱华 ',)
朱华
(' 李博 ',)
李博
(' 梁龙 ',)
梁龙
(' 段欣 ',)
段欣
(' 汪林 ',)
汪林
(' 王雷 ',)
王雷
(' 蒋桂珍 ',)
蒋桂珍
like 方法进行模糊查询,% 匹配任意数量的任意字符,_ 匹配单个任意字符:
# 查询邮箱为谷歌邮箱的 User 实例
In [12]: session.query(User).filter(User.email.like('%gmail%')).all()
Out[12]: [<User: 王雷 >, <User: 朱华 >, <User: 汪林 >, <User: 段欣 >, <User: 刘文 >]
# 查询邮箱第二个字符为 i 的 User 实例
In [13]: session.query(User).filter(User.email.like('_i%')).all()
Out[13]: [<User: 王雷 >, <User: 夏晶 >, <User: 宁兵 >, <User: 李博 >]
in_ 方法查询 “某个字段的值属于某个列表” 的数据:
# 如果列表中的字段在 name 列中查不到,并不会报错
In [14]: session.query(User).filter(User.name.in_([' 王雷 ', ' 夏晶 ', 'xxx'])).all()
Out[14]: [<User: 夏晶 >, <User: 王雷 >]
and_ 方法进行多条件查询,需要引入,等同于上面 filter_by 方法:
In [15]: from sqlalchemy import and_
# 查询符合全部条件的数据
In [16]: session.query(User).filter(and_(User.name==' 王雷 ', User.id==1)).all()
Out[16]: [<User: 王雷 >]
or_ 也是多条件查询,符合任一条件即可,也是需要引入:
In [24]: from sqlalchemy import or_
# 查询符合任一条件的数据
In [25]: session.query(User).filter(or_(
...: User.email=='na55@zhouwan.cn',
...: User.id==1
...: )).all()
Out[25]: [<User: 王雷 >, <User: 梁龙 >]
2.7.2 查询过滤器
| 过滤器 | 说明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit | 使用指定的值限定原查询返回的结果 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
2.7.3 查询执行器
| 方法 | 说明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果未查到,返回 None |
| first_or_404() | 返回查询的第一个结果,如果未查到,返回 404 |
| get() | 返回指定主键对应的行,如不存在,返回 None |
| get_or_404() | 返回指定主键对应的行,如不存在,返回 404 |
| count() | 返回查询结果的数量 |
| paginate() | 返回一个 Paginate 对象,它包含指定范围内的结果 |
2.8 高级查询
下面介绍 SQLAlchemy 的排序、设置查询数量、联结查询等操作。
2.8.1 排序
# 查询全部 User 实例,按实例的 email 值排序
In [27]: session.query(User).order_by(User.email).all()
Out[27]:
[<User: 汪林 >,
<User: 刘文 >,
<User: 段欣 >,
<User: 夏晶 >,
<User: 梁龙 >,
<User: 王雷 >,
<User: 李博 >,
<User: 宁兵 >,
<User: 蒋桂珍 >,
<User: 朱华 >]
In [28]: for user in session.query(User).order_by(User.email).all():
...: print(user.email)
...:
caoli@gmail.com
fang72@gmail.com
heyang@gmail.com
minzhao@meng.cn
na55@zhouwan.cn
pingmao@gmail.com
xiaping@hotmail.com
xiuying77@hotmail.com
yang59@hotmail.com
ytao@gmail.com
# desc 方法进行降序排序,默认为升序
In [29]: session.query(User).order_by(User.email.desc()).all()
Out[29]:
[<User: 朱华 >,
<User: 蒋桂珍 >,
<User: 宁兵 >,
<User: 李博 >,
<User: 王雷 >,
<User: 梁龙 >,
<User: 夏晶 >,
<User: 段欣 >,
<User: 刘文 >,
<User: 汪林 >]
等同于 MySQL 中的 ORDER BY 语句:
mysql> SELECT * FROM user ORDER BY email;
+----+-----------+-----------------------+
| id | name | email |
+----+-----------+-----------------------+
| 3 | 汪林 | caoli@gmail.com |
| 10 | 刘文 | fang72@gmail.com |
| 9 | 段欣 | heyang@gmail.com |
| 4 | 夏晶 | minzhao@meng.cn |
| 7 | 梁龙 | na55@zhouwan.cn |
| 1 | 王雷 | pingmao@gmail.com |
| 8 | 李博 | xiaping@hotmail.com |
| 6 | 宁兵 | xiuying77@hotmail.com |
| 5 | 蒋桂珍 | yang59@hotmail.com |
| 2 | 朱华 | ytao@gmail.com |
+----+-----------+-----------------------+
10 rows in set (0.01 sec)
mysql> SELECT email FROM user ORDER BY email;
+-----------------------+
| email |
+-----------------------+
| caoli@gmail.com |
| fang72@gmail.com |
| heyang@gmail.com |
| minzhao@meng.cn |
| na55@zhouwan.cn |
| pingmao@gmail.com |
| xiaping@hotmail.com |
| xiuying77@hotmail.com |
| yang59@hotmail.com |
| ytao@gmail.com |
+-----------------------+
10 rows in set (0.00 sec)
mysql> SELECT * FROM user ORDER BY email DESC;
+----+-----------+-----------------------+
| id | name | email |
+----+-----------+-----------------------+
| 2 | 朱华 | ytao@gmail.com |
| 5 | 蒋桂珍 | yang59@hotmail.com |
| 6 | 宁兵 | xiuying77@hotmail.com |
| 8 | 李博 | xiaping@hotmail.com |
| 1 | 王雷 | pingmao@gmail.com |
| 7 | 梁龙 | na55@zhouwan.cn |
| 4 | 夏晶 | minzhao@meng.cn |
| 9 | 段欣 | heyang@gmail.com |
| 10 | 刘文 | fang72@gmail.com |
| 3 | 汪林 | caoli@gmail.com |
+----+-----------+-----------------------+
10 rows in set (0.00 sec)
2.8.2 设置查询数量
使用 limit 方法限制查询数量:
# 按 id 字段降序排序,取前 4 条数据
In [30]: session.query(User).order_by(User.id.desc()).limit(4).all()
Out[30]: [<User: 刘文 >, <User: 段欣 >, <User: 李博 >, <User: 梁龙 >]
# 因为查询结果为有序可迭代对象,所以使用列表的切片也是可以的
# 但 limit 方法更可取,因为后者只查询前 4 条数据,对内存的压力要小很多
In [31]: session.query(User).order_by(User.id.desc()).all()[:4]
Out[31]: [<User: 刘文 >, <User: 段欣 >, <User: 李博 >, <User: 梁龙 >]
对应的 MySQL 语句如下:
mysql> SELECT * FROM user ORDER BY id DESC LIMIT 4;
+----+--------+---------------------+
| id | name | email |
+----+--------+---------------------+
| 10 | 刘文 | fang72@gmail.com |
| 9 | 段欣 | heyang@gmail.com |
| 8 | 李博 | xiaping@hotmail.com |
| 7 | 梁龙 | na55@zhouwan.cn |
+----+--------+---------------------+
4 rows in set (0.00 sec)
count 方法统计查询数量:
In [33]: session.query(User).filter(User.email.like('%gmail%')).all()
Out[33]: [<User: 王雷 >, <User: 朱华 >, <User: 汪林 >, <User: 段欣 >, <User: 刘文 >]
# 注意结尾没有 .all() 了
In [34]: session.query(User).filter(User.email.like('%gmail%')).count()
Out[34]: 5
对应的 MySQL 语句:
mysql> SELECT COUNT(*) AS COUNT FROM user WHERE email LIKE '%gmail%';
+-------+
| COUNT |
+-------+
| 5 |
+-------+
1 row in set (0.00 sec)
2.8.3 联结查询
使用 join 方法进行联结查询:
# 查询王雷老师的全部课程,即查询 course 表中的数据
# 条件是 name 值为 ' 王雷 ' 的 user 表外键关联的 course 表中的数据
In [26]: session.query(Course).join(User).filter(User.name==' 王雷 ').all()
Out[26]: [<Course: 不能产品如何经营 >, <Course: 责任标题表示女人 >]
等同于 MySQL 中的 JOIN 语句:
mysql> SELECT course.id, course.name, user_id FROM course
-> JOIN user ON user.id = course.user_id
-> WHERE user.name = ' 王雷 ';
+----+--------------------------+---------+
| id | name | user_id |
+----+--------------------------+---------+
| 1 | 不能产品如何经营 | 1 |
| 2 | 责任标题表示女人 | 1 |
+----+--------------------------+---------+
2 rows in set (0.00 sec)
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net