什么是 Pandas?
Pandas 的名称来自于面板数据(panel data)
Pandas 是一个强大的分析结构化数据的工具集,基于 NumPy 构建,提供了 高级数据结构 和数据操作工具,它是使 Python 成为强大而高效的数据分析环境的重要因素之一。
- 一个强大的分析和操作大型结构化数据集所需的工具集
- 基础是 NumPy,提供了高性能矩阵的运算
- 提供了大量能够快速便捷地处理数据的函数和方法
- 应用于数据挖掘,数据分析
- 提供数据清洗功能
为什么要学习 pandas?
NumPy 已经能够帮助我们处理数据,能够结合 matplotlib 解决我们数据分析的问题,那么 pandas 学习的目的在什么地方呢?
NumPy 能够帮我们处理处理数值型数据,但是这还不够, 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等。
1. 数据结构
1.1 Series
1.1.1 创建
从列表创建:
>>> import pandas as pd
>>> pd.Series([1,2,3,4,5])
0 1
1 2
2 3
3 4
4 5
dtype: int64从数组创建:
>>> import pandas as pd
>>> import numpy as np
>>> pd.Series(np.arange(5))
0 0
1 1
2 2
3 3
4 4
dtype: int32自定义索引:
>>> a=pd.Series([1,2,3,4,5],index=['a','b','c','d','e']) // 自定义索引
>>> a
a 1
b 2
c 3
d 4
e 5 // 此时 a,b,c,d,e 叫标签,索引还是 0-4
dtype: int64
>>> a.values
array([1, 2, 3, 4, 5], dtype=int64)
>>> a.index
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')从字典创建:
>>> dict={'name':' 姚明 ','age':46,'height':190}
>>> pd.Series(dict)
name 姚明
age 46
height 190
dtype: object1.1.2 基本使用
>>> dict={'name':' 姚明 ','age':46,'height':190}
>>> a=pd.Series(dict,index=['name','age','sex'])
>>> a
name 姚明
age 46
sex NaN
dtype: object
>>> a.isnull() // 检查是否为空
name False
age False
sex True
dtype: bool
>>> a.notnull() // 检查是否不为空索引
>>> a[0] // 位置索引
>>> a['name'] // 标签索引
>>> a[-1] // 负号索引
>>> a[[0,2]] // 选取多个,也可标签 a[['name','sex']]
>>> s=pd.Series(np.arange(5))
>>> s[s>3] // 布尔索引切片
>>> a[0:2]
>>> a['name':'sex']广播
>>> s=pd.Series(np.arange(5),index=['a','b','c','d','e'])
>>> s+2
a 2
b 3
c 4
d 5
e 6
dtype: int32补充
s.index.unique() 返回索引唯一值
s.index.is_unique() 判断是否为唯一值 返回True/False
s.value_counts() 返回值以及计数,组成一个 Series
s.isin([8]) 判断 s 里面是否有 8 返回布尔类型的 Series # 也可对 DataFrame 进行判断
1.2 DataFrame
表格型数据结构
1.2.1 创建
从字典类
数组,列表和元祖构成的字典创建 dataframe
Series 构成的字典创建 dataframe
字典构成的字典创建 dataframe
>>> import pandas as pd
>>> import numpy as np
>>> data={
"a":[1,2,3,4],
"b":(5,6,7,8),
"c":np.arange(9,13),
"d":pd.Series(np.range(4))
}
>>> df=pd.DataFrame(data) // 创建 DataFrame 可以指定 index=
>>> df
a b c d
0 1 5 9 0
1 2 6 10 1
2 3 7 11 2
3 4 8 12 3
>>> data={
"a":{'apple':"4",'banana':'2.5'},
"b":{'apple':"3.5",'banana':'3'},
"c":{'apple':"3.5"}
}
>>> pd.DataFrame(data)
a b c
apple 4 3.5 3.5
banana 2.5 3 NaN从列表类
2D ndarray 创建 dataframe
字典构成的列表创建 dataframe
Series 构成的字典创建 dataframe
>>>pd.DataFrame(np.arange(12).reshape(3,4),index=['a','b','c'],columns=['A','B','C','D'])
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11 //index 和 columns 指定索引名称1.2.2 基本使用
属性
>>> df
a b c d
0 1 5 9 0
1 2 6 10 1
2 3 7 11 2
3 4 8 12 3
>>> df.index // 查看数据表的行索引
RangeIndex(start=0, stop=4, step=1)
>>> df.columns // 查看数据表的列索引
Index(['a', 'b', 'c' ,'d'], dtype='object')
>>> df.values // 查看数据表的值
array([[1, 5, 9, 0],
[2, 6, 10, 1],
[3, 7, 11, 2],
[4, 8, 12, 3]], dtype=int64)
>>> df.dtypes // 查看每列数据格式
>>> df.info() // 查看数据表的信息(维度,列名,数据格式。所占空间等)
>>> df['d'].astype('float') // 将数据格式转换成浮点型转置
>>> df.T
a b c
A 0 4 8
B 1 5 9
C 2 6 10
D 3 7 11列索引
>>> df.T['a'] // 直接索引默认只能列索引 且只能标签索引,不能位置索引
A 0
B 1
C 2
D 3
Name: a, dtype: int32增加列
>>> df.T['d']=['2','2','2','2']
>>> df.T
a b c d
A 0 4 8 2
B 1 5 9 2
C 2 6 10 2
D 3 7 11 2删除列
>>> del(df.T['d'])
>>> df.T
a b c
A 0 4 8
B 1 5 9
C 2 6 10
D 3 7 11 取值
>>> df.T['b'][2] // 列索引之后变成了 Series, 故其后可以进行 ' 位置索引 '' 标签索引 '' 负号索引 '' 布尔索引 '
62. DataFrame 基本操作
2.1 索引
列名索引:df[' 列名 '] — 适用列索引
标签索引:df.loc[' 行名 '] — 适用行索引
位置索引:df.iloc[] — 列行索引均可
切片:df[:]— 行切片
列索引
>>> df
A B C
a 0 1 2
b 3 4 5
c 6 7 8
>>> df['A'] // 列名索引,取 A 列数据
a 0
b 4
c 8
Name: A, dtype: int32
>>> df.columns[1]
'B'
>>> df.columns['A'] // 会报错
>>> df.iloc[:,1] // 位置索引,可取到 B 列数据行索引
>>> df
A B C
a 0 1 2
b 3 4 5
c 6 7 8
#index 索引
>>> df.index[1]
'b'
>>> df.index[1]='e' // 会报错,不支持修改行索引名称
>>> df.index['a'] // 会报错,无法取出 'a' 行数据
# 标签索引 loc
>>> df.loc['a'] // 终于能取到行数据了,也能增加行……此法不能取列
A 0
B 1
C 2
Name: a, dtype: int32
#支持切片索引
>>> df[:2]
A B C
a 0 1 2
b 3 4 5
#位置索引 iloc
>>> df.iloc[2] // 选取第三行数据重新索引
行重建
>>> df.reindex(['A','B','C','D','E'])
A B C D
A NaN NaN NaN NaN
B NaN NaN NaN NaN
C NaN NaN NaN NaN
D NaN NaN NaN NaN
E NaN NaN NaN NaN
// 以上只能再新增 A-E 行数据而已
>>> df.reindex(['a','b','c','d'])
A B C D
a 0.0 1.0 2.0 3.0
b 4.0 5.0 6.0 7.0
c 8.0 9.0 10.0 11.0
d NaN NaN NaN NaN
// a,b,c 照旧,新增了 d 行 列重建
>>> df
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
>>> df.reindex(columns=['C','A','B','E'])
C A B E
a 2 0 1 NaN
b 6 4 5 NaN
c 10 8 9 NaN列变索引
>>> df.set_index('D') // 将“D”列变成索引
A B C
D
3 0 1 2
7 4 5 6
11 8 9 10增加列
>>> df
A B C
a 0 1 2
b 3 4 5
c 6 7 8
>>> df[0]=[1,1,1] // 默认往后增加列
A B C 0
a 0 1 2 1
b 3 4 5 1
c 6 7 8 1
>>> df.insert(0,'E',[88,88,88]) // 指定位置插入列
E A B C
a 88 0 1 2
b 88 3 4 5
c 88 6 7 8增加行
>>> df.loc(6)=[1,1,1]
>>> df
A B C
a 0 1 2
b 3 4 5
c 6 7 8
6 1 1 1
>>> row={'A':3,'B':3,'C':3}
>>> df.append(row,ignore_index=True) // 默认为 false, 但是为 true 时,会自动使用新索引
A B C
0 0 1 2
1 3 4 5
2 6 7 8
3 1 1 1
4 3 3 3删除
>>> df
A B C
a 0 1 2
b 3 4 5
c 6 7 8
# del
>>> del(df['A']) // 只能删除列,且每次只能删除一个
#.drop
>>> df.drop(columns=['A','B']) // 删除列
>>> df.drop(index=['a','b']) // 删除行
>>> df.drop(['a','b']) // 删除行
// 此法还可以指定 axis 来取行还是列
>>> df.drop('a',inplace=True) // 直接在原数据上删除,不返回新对象改
>>> df
A B C
a 0 1 2
b 3 4 5
c 6 7 8
>>> df['A']=[1,1,1] // 直接对 A 修改
>>> df.A = 1 // 这样也是可以的
>>>df.loc['a','A']=100 // 修改某一个值
A B C
a 100 1 2
b 3 4 5
c 6 7 8切片
>>> df.loc['a':'b','A':'B'] // 标签索引切片
A B
a 0 1
b 3 4
>>> de.iloc(1:2,0:2) // 位置索引切片2.2 运算
2.2.1 对齐运算
>>> df1=pd.DataFrame(np.arange(12).reshape(4,3),index=['a','b','c','d'],columns=['A','B','C'])
A B C
a 0 1 2
b 3 4 5
c 6 7 8
d 9 10 11
>>> df2=pd.DataFrame(np.arange(9).reshape(3,3),index=['a','d','f'],columns=list("ABD"))
A B D
a 0 1 2
d 3 4 5
f 6 7 8
>>> df1 + df2
A B C D
a 0.0 2.0 NaN NaN
b NaN NaN NaN NaN
c NaN NaN NaN NaN
d 12.0 14.0 NaN NaN
f NaN NaN NaN NaN
// 不存在默认为为空,进行相加DataFrame 与数组 numpy 数据一样,可以进行加减乘除多元运算,但是不能进行直接进行多元逻辑运算(逻辑或,逻辑与)。
要想进行多元逻辑运算,可使用 np.logical_and(arr1,arr2,arr3) 对arr1,arr2,arr3进行与集运算,但要求这三个数组形状一样。同理,逻辑或为np.logical_or(arr1,arr2,arr3)。
2.2.2 填充缺失值运算
>>> df1.add(df2.fill_value=0)
A B C D
a 0.0 2.0 2.0 2.0
b 3.0 4.0 5.0 NaN
c 6.0 7.0 8.0 NaN
d 12.0 14.0 11.0 5.0
f 6.0 7.0 NaN 8.0
// 遇到数字加空值,这个空值填充为 0, 按数字加零进行计算,若是空值加空值,还是为空3. Pandas 的函数应用
3.1 应用函数
- apply 将函数应用到列或者行
>>> df=pd.DataFrame(np.random.randn(3,4))
>>> df
0 1 2 3
0 0.330759 0.730455 -1.579240 -0.731951
1 0.612881 0.097846 1.265440 2.285802
2 -1.503725 1.155428 1.156895 0.776801
>>> f=lambda x:x.max() // 定义一个匿名函数,给一个 x,就求 x 的最大值
>>> df.apply(f) // 默认 axis=0, 按列求每一列的最大值
0 0.612881
1 1.155428
2 1.265440
3 2.285802
dtype: float64- applymap 将函数应用到每一个数据
>>> f=lambda x:"%.2f"%x // 定义一个匿名函数,给一个 x,就对 x 保留两位小数
>>> df.applymap(f)
0 1 2 3
0 0.33 0.73 -1.58 -0.73
1 0.61 0.10 1.27 2.29
2 -1.50 1.16 1.16 0.78agg(), aggregate(), apply()这三种函数有着类似的功能。
3.2 排序
- 按索引排序
>>> df=pd.DataFrame(np.arange(12).reshape(3,4),index=list("bca"),columns=list('CBDA'))
>>> df
C B D A
b 0 1 2 3
c 4 5 6 7
a 8 9 10 11
>>> df.sort_index() // 按行索引大小排序……若想倒序 设置 ascending=False
C B D A
a 8 9 10 11
b 0 1 2 3
c 4 5 6 7
// 若按照列索引排序,只需设置 axis=1- 按值排序
>>> df=pd.DataFrame({'a':[3,7,0,9],'c':[5,2,8,0],'b':[9,5,2,8]})
>>> df
a c b
0 3 5 9
1 7 2 5
2 0 8 2
3 9 0 8
>>> df.sort_values(by=['a','c']) // 按照 a 列数值大小排列,若 a 列相同,则按 c 列
a c b
2 0 8 2
0 3 5 9
1 7 2 5
3 9 0 83.3 处理缺失值
df.isnull() 判断每个位置是否有缺失值,返回布尔类型的 DataFrame
df.notnull() 判断每个位置是否无缺失值,返回布尔类型的 DataFrame
df.dropna() 删除有缺失值的行 ,可传参how='all' 默认为'any',整行都是 nan 才删 / 只要有一个 nan 就删。
>>> df
a c b
0 3.0 5.0 9
1 7.0 NaN 5
2 NaN 8.0 2
3 9.0 0.0 8
>>> df.dropna() // 默认按行删除 增加 axis=1 可按列删除
a c b
0 3.0 5.0 9
3 9.0 0.0 8df.fillna() 填充缺失值:
可传参{0:1,1:100},意思是第 0 列缺失值填充为 1,第 1 列缺失值填充为 100;
可传参method=('ffill'),意思是缺失值填充为它的上方的数据,继承上一行的数据;
可传参method=('ffill',limit=2),意思是对继承的次数进行限制。
>>> df.fillna(-100) // 将所有缺失值补充填为 -100
a c b
0 3.0 5.0 9
1 7.0 -100.0 5
2 -100.0 8.0 2
3 9.0 0.0 84. 层级索引
>>> s=pd.Series(np.random.randn(6),index=[['a','a','a','b','b','b'],[0,1,2,0,1,2]])
a 0 -0.981812
1 -0.101430
2 -1.254341
b 0 0.371863
1 0.434470
2 -0.729295
dtype: float64
>>> s.index // 多层索引
MultiIndex([('a', 0),
('a', 1),
('a', 2),
('b', 0),
('b', 1),
('b', 2)],
)4.1 选取
s['a'] 外层选取
s[:,2]内层选取
>>> s[:,2] // 选取内层为 2 的数据
a -1.254341
b -0.729295
dtype: float64s['a',1] 选取某一个值
4.2 交换
s.swaplevel() 交换内外层的索引
>>> s.swaplevel()
0 a -0.981812
1 a -0.101430
2 a -1.254341
0 b 0.371863
1 b 0.434470
2 b -0.729295
dtype: float644.3 排序
s.sortlevel() 先按照外层索引排序,再对内层索引排序
4.4 重塑
df.stack() 将 DataFrame 变成层级 Series
s.unstack() 将层级 Series 变成 DataFrame
>>> s=pd.Series(np.random.randn(6),index=[['a','a','a','b','b','b'],[0,1,2,0,1,2]])
a 0 -0.981812
1 -0.101430
2 -1.254341
b 0 0.371863
1 0.434470
2 -0.729295
>>> s.unstack() // 将层级 Series 变成 DataFrame
0 1 2
a -0.981812 -0.10143 -1.254341
b 0.371863 0.43447 -0.729295这样就可以对数据进行切片了。
5. 统计计算
df.sum() 默认按列数据求和……补充 axis=1 按行数据求和
df.cumsum() 按列往下进行求和
>>> df=pd.DataFrame({'a':[3,7,np.nan,9],'c':[5,np.nan,8,0],'b':[9,5,2,8]})
a c b
0 3.0 5.0 9
1 7.0 NaN 5
2 NaN 8.0 2
3 9.0 0.0 8
>>> df.cumsum() // 默认 skipna=True 跳过缺失值求和
a c b
0 3.0 5.0 9
1 10.0 NaN 14
2 NaN 13.0 16
3 19.0 13.0 24df.mean() 默认按列数据求平均值
df.max()默认按列数据最大值
df.min()默认按列数据最小值
df.idxmax() 求每列最大的数值对应的行索引
df['XX'].value_counts() 统计 XX 列中的种类及其个数
统计描述
df.describe() 汇总统计
>>> df.describe()
a c b
count 3.000000 3.000000 4.000000
mean 6.333333 4.333333 6.000000
std 3.055050 4.041452 3.162278
min 3.000000 0.000000 2.000000
25% 5.000000 2.500000 4.250000
50% 7.000000 5.000000 6.500000
75% 8.000000 6.500000 8.250000
max 9.000000 8.000000 9.000000统计函数对 Series 也适用,下面举一个字符类型的 Series 的例子
>>> s=pd.Series(['a','b','c','b','a','a','e'])
0 a
1 b
2 c
3 b
4 a
5 a
6 e
dtype: object
>>> s.describe()
count 7
unique 4
top a // 统计出现频率最多的
freq 3
dtype: object6. 数据处理
6.1 文件读取
6.1.1 常用
CSV 文件:
>>> import pandas as pd
>>> import numpy as np
>>> pd.read_csv('scores.csv',encoding='gbk')
数学 英语
0 59.0 89.0
1 78.0 45.0
2 24.0 NaN
3 NaN 56.0
4 23.0 56.0
>>> pd.read_table('scores.csv',sep=",",encoding='gbk')
数学 英语
0 59.0 89.0
1 78.0 45.0
2 24.0 NaN
3 NaN 56.0
4 23.0 56.0txt 文件:
>>> list(open('demo.txt'))
['A B C\n', '1 2 3\n', '4 5 6']
>>> p=pd.read_table('demo.txt')
A B C
0 1 2 3
1 4 5 6
>>> p['A'] // 报错……不管怎么索引都会出错
>>> p=pd.read_table('demo.txt',sep='\s+') // 应该这样读取…… \s 空白符
A B C
0 1 2 3
1 4 5 6
>>> p['a']
0 1
1 4
Name: A, dtype: int64以下需要好好领悟
>>> pd.read_table('demo.csv',sep=",") // 本来是这样的
key1 key2 value1 value2
0 one a 1 2
1 one b 2 4
2 two c 3 6
3 two d 4 8
4 three e 5 10
5 three f 6 12
>>> p=pd.read_table('demo.csv',sep=",",index_col=['key1','key2']) // 这样读取!
value1 value2 // 将列变成索引
key1 key2
one a 1 2
b 2 4
two c 3 6
d 4 8
three e 5 10
f 6 12
>>> p.index
MultiIndex([('one', 'a'),
('one', 'b'),
('two', 'c'),
('two', 'd'),
('three', 'e'),
('three', 'f')],
names=['key1', 'key2'])去头:括号传参head=None
赋头:括号传参names=['a','b','c',...]
加列索引:括号传参index_col=['a','b','c',...]
6.1.2 总结
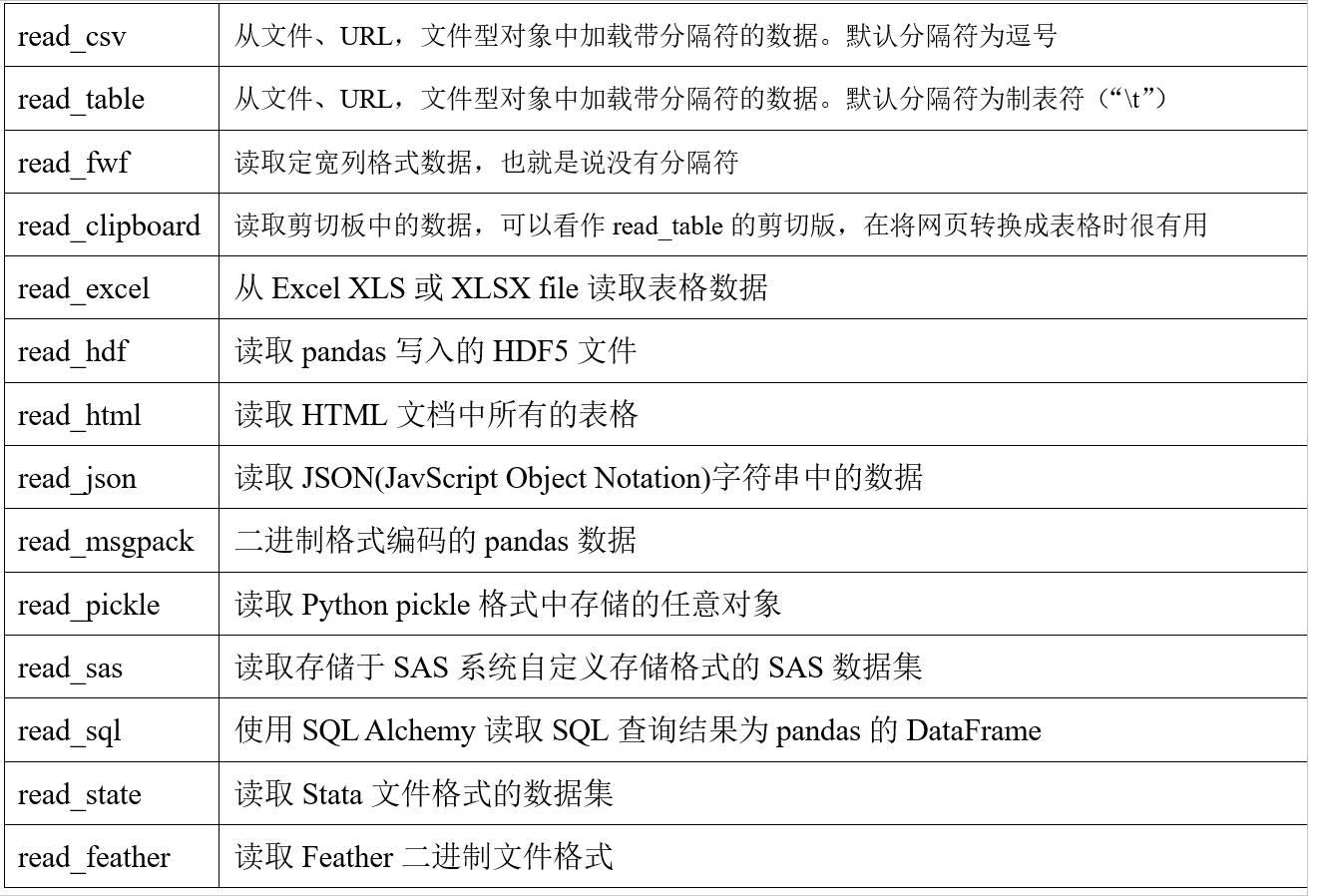
包含的参数

6.1.3 大文件分块读取
对于千万级以上的数据读取时,不能一次性全部读取,电脑内存受不了,这时就需要分块读取。
- 指定 CHUNKSIZE 分块读取文件,用以指定一个块大小(每次读取多少行),返回一个可迭代的
TextFileReader对象。
>>> table=pd.read_csv('fn.csv',chunksize=100) // 每 100 行的读
>>> table.get_chunk(5) // 获取前 5 行 注意这是迭代处理
>>> for df in table: // 循环处理
对 df 处理- 指定迭代 = 真
>>> reader = pd.read_table('tmp.sv', sep='\t', iterator=True)
>>> reader.get_chunk(10000) // 通过 get_chunk(size),返回一个 size 行的块举个例子:
>>> reader = pd.read_table('tmp.sv', sep='\t', iterator=True)
>>> chunkSize = 1000
>>> chunks = []
>>> loop=True
>>> while loop:
>>> try:
>>> chunk = reader.get_chunk(chunkSize)
>>> chunks.append(chunk)
>>> except StopIteration:
>>> loop=False
>>> print ("Iteration is stopped.")
>>> df = pd.concat(chunks, ignore_index=True)
// 这样数据就被读取出来了6.2 文件保存
写入 CSV 文件:
pd.to_csv(file_path or buf,sep,columns,header,index,na_rep,mode)
file_path:保存文件路径, 默认 None
sep:分隔符,默认’,’
columns:是否保留某列数据,默认 None
header:是否保留列名,默认 True
index:是否保留行索引,默认 True
na_rep:指定字符串来代替空值,默认是空字符
mode:默认’w’,追加’a’
也可以df.to_excel(file_path or buf,sep,columns,header,index,na_rep,mode)
保存为二进制文件:
df.to_pickle() 此用法不多
6.3 数据清洗
6.3.1 处理缺失值
参照 3.3 节内容。
6.3.2 处理重复行
检查重复数据:
data.duplicated() 返回布尔类型数据,重复的那一行为 True。
删除重复数据:
data.drop_duplicates()返回删除重复行后剩下的数据。默认检查行中所有的列数据。
可传参['B'],keep='last',意思是以 B 列为准,判断是否有重复的行,如第三行的 B 列与第五行的 B 列数据重复,就会删除前一行,保留后一行。
再看看下面的例子:
>>> data=pd.DataFrame({'food':['Apple','banana','orange','apple','mango','tomato'],
'price':[4,3,3.5,6,12,3]})
food price
0 Apple 4.0
1 banana 3.0
2 orange 3.5
3 apple 6.0
4 mango 12.0
5 tomato 3.0其中 apple 有重复,需要按 food 列删除。
food 列大小写统一化处理:
>>> lower=data['food'].str.lower() //lower()小写,upper()大写
0 apple
1 banana
2 orange
3 apple
4 mango
5 tomato
Name: food, dtype: object6.3.3 数据分类
对 food 进行分类:
>>> classf={'apple':'fruit','banana':'fruit','orange':'fruit','mango':'fruit','tomato':'vagetables'
}
>>> data['classf']=lower.map(classf)
>>> data
food price classf
0 Apple 4.0 fruit
1 banana 3.0 fruit
2 orange 3.5 fruit
3 apple 6.0 fruit
4 mango 12.0 fruit
5 tomato 3.0 vagetables
// 也可以采用下面这种方式
>>> data['classf']=data['food'].map(lambda x:classf[x.lower()])6.3.4 替换值
data.replace(A,B) 把 data 中的 A 替换成 B
6.3.5 重命名轴索引
>>> data=pd.DataFrame((np.arange(12)).reshape(3,4),index=['Beijing','Tokyo','New York'],columns=['one','two','three','four'])
>>> data
one two three four
Beijing 0 1 2 3
Tokyo 4 5 6 7
New York 8 9 10 11方法 1:
>>> data.index=['B','T','N'] // 重命名行
>>> data
one two three four
B 0 1 2 3
T 4 5 6 7
N 8 9 10 11
>>> data.columns=['One','Two','Three',"Four"] // 重命名列
One Two Three Four
B 0 1 2 3
T 4 5 6 7
N 8 9 10 11方法 2:
>>> data.rename(index={'B':'BJ'},columns={'Four':' 第四年 '})
One Two Three 第四年
BJ 0 1 2 3
T 4 5 6 7
N 8 9 10 11想要改变原数据时,即 data 本身也改变,可赋值inplace=True
6.3.6 离散化与面元划分
对列表进行划分:
>>> ages=[34,56,12,34,45,8,2,78,90,4]
>>> bin=[0,3,12,18,30,60,100]
>>> a=pd.cut(ages,bin) // 对 ages 中的数字按照 bin 里的分区进行划分
>>> a
[(30, 60], (30, 60], (3, 12], (30, 60], (30, 60], (3, 12], (0, 3], (60, 100], (60, 100], (3, 12]]
Categories (6, interval[int64]): [(0, 3] < (3, 12] < (12, 18] < (18, 30] < (30, 60] < (60, 100]]
// 以上区间默认是左开右闭,可传入 right=False,就会变成左闭右开
>>> a.codes // 返回 ages 中的每个数据在第几个区间
array([4, 4, 1, 4, 4, 1, 0, 5, 5, 1], dtype=int8)
>>> pd.value_counts(a) // 对 a 中的区间进行计数
(30, 60] 4
(3, 12] 3
(60, 100] 2
(0, 3] 1
(18, 30] 0
(12, 18] 0
dtype: int64
>>> labels=[' 幼儿 ',' 儿童 ',' 青少年 ',' 青年 ',' 中年 ',' 老年 ']
>>> a=pd.cut(ages,bin,labels=labels) #传入 label 标签
>>> a
[中年, 中年, 儿童, 中年, 中年, 儿童, 幼儿, 老年, 老年, 儿童] Categories (6, object): [幼儿 < 儿童 < 青少年 < 青年 < 中年 < 老年]
>>> s=pd.cut(ages,4) // 将 ages 分成 4 个等分区间
[(24.0, 46.0], (46.0, 68.0], (1.912, 24.0], (24.0, 46.0], (24.0, 46.0], (1.912, 24.0], (1.912, 24.0], (68.0, 90.0], (68.0, 90.0], (1.912, 24.0]]
Categories (4, interval[float64]): [(1.912, 24.0] < (24.0, 46.0] < (46.0, 68.0] < (68.0, 90.0]]
// 可传入参数 precision=2,即可对数据保留两位小数
>>> pd.qcut(ages,4) // 将 ages 分成 4 个区间, 每个区间中包含的数据个数相等6.3.7 提取异常值
>>> data[(np.abs[data]>3).any(1)] // 只要 data 中有一个大于 3 的,就取出来
>>> np.where(data.Size.str.contains(' 室 ')) // 把 data 中 Size 那一列中包含 ' 室 ' 的行索引号取出来 6.3.7 采样与随机排列
采样:
>>> df.sample(n=2) // 在 df 中随机采取 2 行数据 随机排列:
>>> sam=np.random.permutation(5) // 生成 0-4 共 5 个数,并随机排列
>>> df.take(sam) // 对 df 按照 sam 的顺序排列6.4 字符串操作
6.4.1 字符串方法


6.4.2 正则表达式方法

6.4 pandas 字符串方法
首先举个例子:
>>> data=pd.Series(['dace@qq.com','dace@gmail.com','dace@163.com'],index=['a','b','c'])
a dace@qq.com
b dace@gmail.com
c dace@163.com
dtype: object
>>> data.str // 注意这种用法很重要!!!
<pandas.core.strings.StringMethods at 0x1ffaa3ecdd8>
>>> data.str.contains('gmail') // 判断 data 里是否包含‘gmail’
a False
b True
c False
dtype: bool
>>> data.str[:5] // 字符串化之后,切片取值前 5 个字符
a dace@
b dace@
c dace@
dtype: object归纳如下:

注意:以上判断字符串是否数字的函数,只能对整型数字进行判断,不能判断浮点类型数据。
isalnum()用法:只要不出现特殊符号则返回真>>> 'ytvu2313131y 树 '.isalnum() True >>> '+'.isalnum() //'./'.isalnum() False//Falseisalpha()用法:只要不出现阿拉伯数字或者特殊符号则返回真>>> 'Wqwuu 数 '.isalpha() //'wqwuu 数十 '.isalpha() True//True >>> 'wqwuu 数十。'.isalpha() //'wqwuu 数十 123'.isalpha() False//Falseisdecimal()用法:True: Unicode 数字,全角数字(双字节)
False: 罗马数字,汉字数字,小数
Error: byte 数字(单字节)>>> '123'.isdecimal() True >>> '123.34'.isdecimal() //'123.34fff'.isdecimal() False//Falseisdigit()用法:True: Unicode 数字,byte 数字(单字节),全角数字(双字节)
False: 汉字数字,罗马数字,小数>>> '123'.isdigit() //'233' .isdigit() Trueisnumeric()用法:True: Unicode 数字,全角数字(双字节),罗马数字,汉字数字
False: 小数
Error: byte 数字(单字节)>>> ' 二十 3' .isnumeric() Trueislower()用法:只要不出现大写字符则返回真>>> 'zuo 天 123。' .islower() Trueisupper()用法:只要不出现小写字母则返回真>>> 'ZUO 天 123。' .isupper() True
6.5 数据规整
6.5.1 规整分块
>>> frame=pd.DataFrame({'a':np.arange(7),'b':np.arange(7,0,-1),
'c':['one','one','one','two','two','two','two'],
'd':[0,1,2,0,1,2,3]}
>>> frame
a b c d
0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
3 3 4 two 0
4 4 3 two 1
5 5 2 two 2
6 6 1 two 3对数据进行规整分块
>>> frame.set_index(['c','d']) //c 列作为主索引,d 列作为次索引
a b
c d
one 0 0 7
1 1 6
2 2 5
two 0 3 4
1 4 3
2 5 2
3 6 1
// 括号传参 drop=Flase 则在后面继续保留 c,d 列6.5.2 数据连接
pd.merge()根据单个或多个键将不同 DataFrame 的行连接起来
类似数据库的连接操作
pd.merge(left, right, how='inner',on=None,left_on=None, right_on=None)left:合并时左边的 DataFrame
right:合并时右边的 DataFrame
how:合并的方式, 默认’inner’,还有’outer’, ‘left’, ‘right’
on:需要合并的列名, 必须两边都有的列名,并以 left 和 right 中的列名的交集作为连接键
left_on: left Dataframe 中用作连接键的列
right_on: right Dataframe 中用作连接键的列
内连接 inner:对两张表都有的键的交集进行联合
外连接 outer:对两张表都有的键的并集进行联合
左连接 left:对所有左表的键进行联合
右连接 right:对所有右表的键进行联合
举个例子
>>> left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
>>> right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
>>> pd.merge(left,right, how='left', on=['key1', 'key2'])
处理重复列名:
参数 suffixes:默认为_x, _y
>>> df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data' : np.random.randint(0,10,7)})
>>> df2= pd.DataFrame({'key': ['a', 'b', 'd'],
'data' : np.random.randint(0,10,3)})
>>> pd.merge(df1, df2, on='key', suffixes=('_left', '_right')) 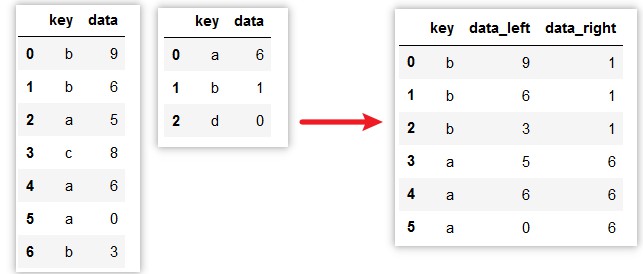
按索引连接:
参数 left_index=True 或 right_index=True,留下左索引 / 右索引。
df1.append(df2)left.join(right,on='key')
6.5.3 数据合并
np.concatenate(a,b)介绍 Numpy 库中已经介绍。
pd.concat([a,b],axis,join, ignore_index=True)- 注意指定轴方向,默认 axis=0,按行拼接
- join 指定合并方式,默认为’outer’,取并集合并,还可指定’inner’,取交集合并
- Series 合并时查看行索引有无重复
6.5.4 轴向旋转
>>> df = pd.DataFrame({'date':['2018-1','2018-1','2018-2','2018-2','2018-3'],
'class':['a','b','b','c','c'],
'values':[5,3,2,6,1],
'values1':[4,5,6,8,9]},columns=['date','class','values','values1'])
>>> df.pivot('date','class','values')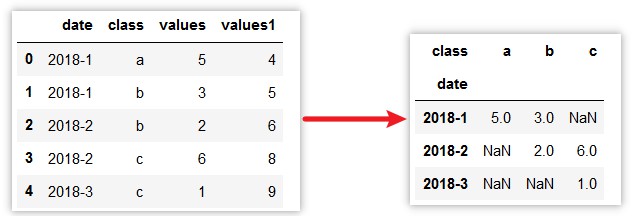
6.6 数据聚合与分组
聚合的分组的含义:

分组函数:df.groupby()
分组:
>>> df = pd.DataFrame({'fruit':['apple','banana','orange','apple','banana'],
'color':['red','yellow','yellow','red','cyan'],
'price':[8.5,6.8,5.6,7.8,6.4]})
>>> df
fruit color price
0 apple red 8.5
1 banana yellow 6.8
2 orange yellow 5.6
3 apple red 7.8
4 banana cyan 6.4
>>> df['fruit'].value_counts() // 统计水果列种类及个数
// 分组函数的应用
>>> g = df.groupby(by='fruit')
>>> type(g)
pandas.core.groupby.generic.DataFrameGroupBy
// 分组输出
>>>for name,group in g:
print(name) // 输出组名
print('-'*50)
print(group) // 输出数据块 dataframe 类型
apple
--------------------------------------------------
fruit color price
0 apple red 8.5
3 apple red 7.8
banana
--------------------------------------------------
fruit color price
1 banana yellow 6.8
4 banana cyan 6.4
orange
--------------------------------------------------
fruit color price
2 orange yellow 5.6
// 选取任意数据块
>>> dict(list(df.groupby(by='fruit')))['apple'] // 先变成列表,再变成字典结构,易于索引
fruit color price
0 apple red 8.5
3 apple red 7.8通过字典或 Series 进行分组
>>> people = pd.DataFrame(np.random.randn(5, 5),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Sam', 'Make', 'Tony', 'Jim', 'Nana'])
>>> m = {'a': 'red', 'b': 'red', 'c': 'blue','d': 'blue', 'e': 'red', 'f' : 'orange'}
>>> people.groupby(m,axis=1).sum()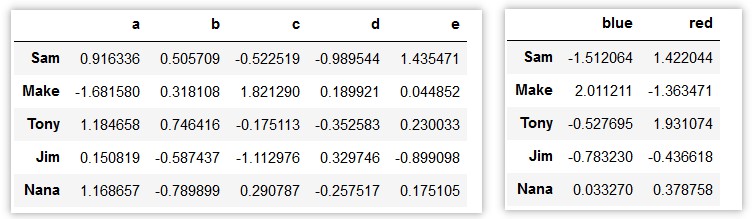
通过函数进行分组
>>> people.groupby(len).sum() // 按索引的字符长度进行求和
a b c d e
3 1.067155 -0.081729 -1.635495 -0.659798 0.536373
4 0.671735 0.274625 1.936964 -0.420179 0.449990聚合:
>>> df.groupby(['fruit','color'])[['price']].mean()
price
fruit color
apple red 8.15
banana cyan 6.40
yellow 6.80
orange yellow 5.60as_index:对于聚合输出, 返回以组便签为索引的对象,仅对 DataFrame
>>> df.groupby('fruit')['price'].mean() // 返回 Series 对象
>>> df.groupby('fruit',as_index=False)['price'].mean() // 返回 DataFrame 对象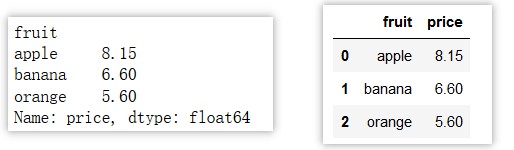
>>> df
fruit color price
0 apple red 8.5
1 banana yellow 6.8
2 orange yellow 5.6
3 apple red 7.8
4 banana cyan 6.4
>>> def diff(arr):
return arr.max() - arr.min()
>>> df.groupby('fruit')['price'].agg(diff) // 求差价
fruit
apple 0.7
banana 0.4
orange 0.0
Name: price, dtype: float647. 时间序列
7.1 基础
7.1.1 创建及索引
>>> import numpy as np
>>> import pandas as pd
>>> from datetime import datetime
>>> dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
datetime(2011, 1, 7), datetime(2011, 1, 8),
datetime(2011, 1, 10), datetime(2011, 1, 12)]
>>> ts = pd.Series(np.random.randn(6), index=dates)
2011-01-02 -0.540878
2011-01-05 -1.736195
2011-01-07 -1.751403
2011-01-08 -0.683907
2011-01-10 -0.458234
2011-01-12 -1.284808
dtype: float64
dtype: float64
>>> ts.index
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)
// 除了常规的一些标签,位置索引外,还支持以下的索引
>>> ts['20100110']
-0.4582336049173489时间范围索引
>>> ts = pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2000',periods=1000))
>>> ts // 时间序列默认每天生成,periods=1000 意思是生成 1000 天的时间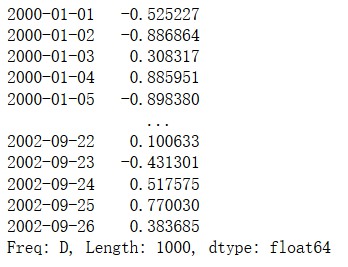
索引:
>>> ts['2002'] // 会选取 2002 年的所有数据, 还可指定月份
>>> ts[datetime(2002,9,23):] // 返回 2002-9-23 及以后 ts1 中有的值
>>> ts['2002-9-23':'2002-12-30']=1
>>> ts // 结果如下,这不同于切片,有的才赋值,没有就不管
>>> ts.truncate(after='1/9/2001') // 取 1/9/2001(不包含)之前的数据重复的时间索引:
>>> dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000','1/2/2000', '1/3/2000'])
>>> ts = pd.Series(np.arange(5), index=dates)
>>> ts
2000-01-01 0
2000-01-02 1
2000-01-02 2
2000-01-02 3
2000-01-03 4
dtype: int32
>>> ts.index.is_unique // 检查是否为唯一
False
>>> ts['1/2/2000']
2000-01-02 1
2000-01-02 2
2000-01-02 3
dtype: int32
>>> ts.groupby(level=0).count() // 还支持分组
2000-01-01 1
2000-01-02 3
2000-01-03 1
dtype: int647.1.2 时间索引的范围,频率,及移动
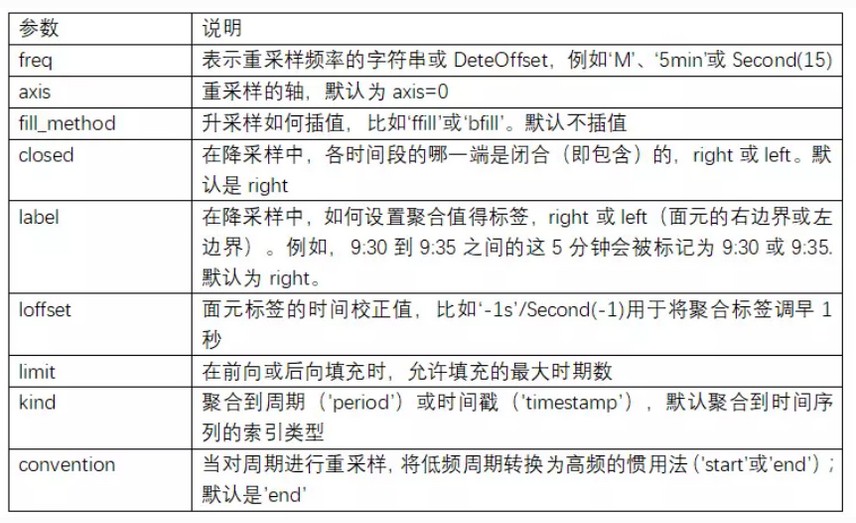
>>> index = pd.date_range(begin_time, end_time, periods, freq) 默认periods=None,若没有指定 end_time,可由 periods 指定生成天数。
默认freq='D',还支持以下偏移:

举个例子:
>>> ts=pd.date_range('2012-01-01','2012-12-31',freq='M') // 生成每个月的最后一天
DatetimeIndex(['2012-01-31', '2012-02-29', '2012-03-31', '2012-04-30',
'2012-05-31', '2012-06-30', '2012-07-31', '2012-08-31',
'2012-09-30', '2012-10-31', '2012-11-30', '2012-12-31'],
dtype='datetime64[ns]', freq='M')日期偏移量
>>> from pandas.tseries.offsets import Hour,Minute
>>> pd.date_range('2012-01-01','2012-01-02',freq='4h') // 按小时来偏移
DatetimeIndex(['2012-01-01 00:00:00', '2012-01-01 04:00:00',
'2012-01-01 08:00:00', '2012-01-01 12:00:00',
'2012-01-01 16:00:00', '2012-01-01 20:00:00',
'2012-01-02 00:00:00'],
dtype='datetime64[ns]', freq='4H')
>>> ts.shift(2) // 将 value 向下偏移两个位置,也可传入 freq 参数7.2 重采样及频率转换
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据聚合到低频率称为降采样(downsampling),而将低频率数据转换到高频率则称为升采样(upsampling)。
降采样示例:
>>> t = pd.DataFrame(np.random.uniform(10,50,(100,1)),index=pd.date_range('20170101',periods=100))
>>> t
0
2017-01-01 19.606228
2017-01-02 26.594414
2017-01-03 40.741761
2017-01-04 27.251084
2017-01-05 10.215133
... ...
2017-04-06 22.951463
2017-04-07 23.516511
2017-04-08 32.327609
2017-04-09 22.503653
2017-04-10 19.498829
100 rows × 1 columns
>>> t.resample('M').sum() // 将 t 里面的数据按月求和
0
2017-01-31 920.056615
2017-02-28 888.402558
2017-03-31 1026.173892
2017-04-30 305.172146升采样示例:
>>> frame = pd.DataFrame(np.random.randn(2, 4),
index=pd.date_range('1/1/2000', periods=2,freq='W-WED'),
columns=[' 上海 ', ' 北京 ', ' 深圳 ', ' 广州 '])
>>> frame
上海 北京 深圳 广州
2000-01-05 -1.081783 -0.340245 -1.626201 0.021319
2000-01-12 -0.126046 0.656332 -0.114384 -1.840728
>>> frame.resample('D').asfreq()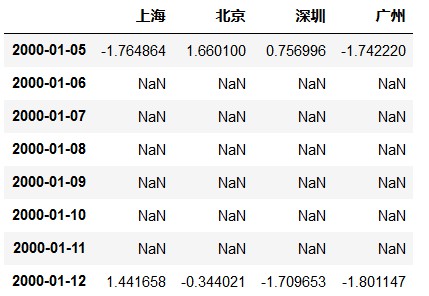
resample 是一个灵活高效的方法,可用于处理非常大的时间序列。
7.3 应用案例
>>> df = pd.read_csv('911.csv')
>>> df.head()
>>> df['timeStamp'] = pd.to_datetime(df['timeStamp']) // 转换成时间格式
>>> df.set_index('timeStamp',inplace=True) // 设置其中一列为索引
8. 老师总结
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net