一个程序员连 Linux 命令都不会,还算什么程序员!
这里对常见的 Linux 命令做一个总结。
Linux,全称 GNU/Linux,是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 Unix 的多用户、多任务、支持多线程和多 CPU 的操作系统。
一般 linux 系统基本上分两大类:
- RedHat 系列:Redhat、Centos、Fedora 等;
- Debian 系列:Debian、Ubuntu 等。
类 Unix 系统目录结构

以上这个目录结构要牢记。
1、Linux 常见命令
1.1 linux 命令格式
command [-options] [parameter]
命令 选项 参数 1.2 查看帮助信息
方式一:
command --help方式二:
man [section] commandman 是 linux 中的用户手册,包含的各个 section 意义如下:
- 1 – User Commands 一般用户命令
- 2 - System Calls 系统调用命令, 如 open,write 之类的(通过这个,至少可以很方便的查到调用这个函数,需要加什么头文件)
- 3 - C library Functions C 函数库命令, 如 printf,fread
- 4 - Devices and Special files 是特殊文件, 也就是 /dev 下的各种设备文件 man hd
- 5 - File formats and conventions 是指文件的格式, 比如 man 5 passwd, 就会得到说明这个文件 /etc/passwd 中各个字段的含义
- 6 - games for linux 是给游戏留的, 由各个游戏自己定义
- 7 - Miscellanea 杂项, 例如宏命令包、惯例等。
- 8 - System administration tools and Deamons 是系统管理用的命令, 这些命令只能由 root 使用, 如 ifconfig
- 9 - 其他(Linux 特定的), 用来存放内核例行程序的文档。
- n 新文档, 可能要移到更适合的领域。
- o 老文档, 可能会在一段期限内保留。
- l 本地文档, 与本特定系统有关的。
1.3 自动补全
想要编辑某个文件时,若文件名太长,可采用先敲几个前面的字母,按 tab 键可自动补全。
2 次 tab 键可补全显示目录下所有文件
按方向键上可出现上次输入的命令。
1.4 基础命令
ls显示当前目录下的文件ls #显示当前目录下的文件 ls / #显示根目录下的文件 ls /bin #显示根目录下 bin 文件夹里的文件 ls -a #显示当前目录下的所有文件(包括隐藏文件,以. 开头的文件名) ls -l #以详细列表形式显示文件(文件大小显示以字节大小形式) ls -l -h #以详细列表形式显示文件, 同时显示文件大小(以 k,M,G 等单位) ls -alh #(选项可以写在一起)具体每个字符表示什么,后面会 2.6.3 介绍 ls --help #查看所有用法pwd显示当前所处位置(在哪个目录下)cd 目录切换目录cd /bin #切换到根目录下的 bin 文件夹里 cd ~ #切换到家目录中的用户文件夹 cd ./test #切换到当前路径下的 test 文件夹里 cd .. #切换到上级目录 cd - #快速回到上次你所在的路径touch 文件名创建文件mkdir 文件夹名创建文件夹mkdir A #在当前目录下创建 A 文件夹 mkdir A/B/C -p #在当前目录下创建 A 文件夹, 再建 B, 再建 Crmdir 文件夹名删除文件夹,若文件夹不为空,则无法删除rm 文件名删除文件 / 文件夹rm *.txt #删除所有 txt 文件(空文件) rm A -r #强制删除 A 文件 即使里面有内容 find /dir/path/* -type f -mtime +2 -exec rm {} \; #-type f 表示只删文件, -mtime +2 筛选修改日期是 2 天前的cat 文件名查看文件里的所有内容,可同时显示多个文件内容cat > 文件名新建文件,并在换行后继续输入,将输入内容写进文件中,ctrl + d 结束输入more 文件名滑动逐次查看内容(按 Enter 键滑动阅览,f 键前翻页,b 键后翻页,q 键结束)head 文件名查看前 10 行tail 文件名查看后 10 行tail -f xx.log动态查看(适用于 log 在随时更新的情况)tail -50f xx.log动态查看后 50 行整齐输出(表格化输出):
column -t如:
tail xx.csv |colunmn -thistory查看已经使用过哪些命令!编号 #执行 history 记录的编号对应的哪个命令tree以目录树的形式显示当前路径下所有文件。这个命令需要安装。file xxx:用于识别文件类型。与 Windows 不同,Linux 系统并不完全依赖文件扩展名(如
.txt,.jpg)来判断文件类型。file命令会通过读取文件的 内容 、检查文件头的 魔术数字(Magic Number)以及文件结构,来准确告诉你这到底是一个什么样的文件。识别文件内容:判断是文本、二进制可执行文件、图片还是压缩包等。
检测编码格式:对于文本文件,能识别是 ASCII、UTF-8 还是其他编码。
分析二进制文件:识别可执行文件是 32 位 还是 64 位,以及是否为动态链接库。
[admin@localhost Tp]$ file TpG TpGen-Qt: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 3.2.0, BuildID[sha1]=f5e4eb9bd95f0a14f41d1ef1a6f8ee703c85a059, stripped
1.5 通配符
linux 里也支持正则表达式进行文件的搜索。
ls 1*.txt #显示名字以 1 开头的所有 txt 文件
ls 1?3 #显示名字为 1 什么 3 的所有文件
ls 1[1-5]3 #显示名字为 113 或 123 或 133 或 143 或 153 的所有文件1.6 重定向
ls > xx.txt #把当前目录下 ls 显示的所有文件名或文件夹名写到 xx.txt 文件里
ls >> xx.txt #把当前目录下 ls 显示的所有文件名或文件夹名追加写到 xx.txt 文件里
cat 1.txt 2.txt > xxx.txt #把 1.txt 和 2.txt 内容合并到 xxx.txt 里1.7 管道

以上的意思是 ls -alh 显示所有文件,将文件放到管道里,再调用 more 命令滑动逐次查看内容。
1.8 链接
分为软链接和硬链接
软链接:就是类似与快捷方式,指向源文件,加 -s
硬链接:相当于给文件又给了个名字,不加 -s
用法 1:链接源文件到目标路径
格式:ln -s 【源目录 / 文件】 【目标路径】
比如,将其他位置的 1.txt 文件,链接到我的目标文件夹的:
ln -s /home/qiang/file/test.txt ./ # 将 1.txt 链接到当前目录下修改源目录 / 文件
ln -snf /home/qiang/file/test.py ./ 重命名:
在当前目录下,mv test.py 1.py 即可。
用法 2:创建快捷方式
ln -s 1.txt 1-softlink.txt #给 1.txt 创建软链接 1-softlink.txt
ln 1.txt 1-hardlink.txt #给 1.txt 创建硬链接 1-hardlink.txt当删除文件时,删除的是硬链接,当文件的硬链接为 0 时,就会自动删除文件。
1.9 查找
1.9.1 文本查找
grep 'ntfs' xx.txt #在 xx.txt 里查找‘ntfs’
grep '^ntfs' xx.txt #在 xx.txt 里查找开头为‘ntfs’的字符串
grep -v 'ntfs' xx.txt # -v 作用是取反,不包含‘ntfs’
grep -n 'ntfs' xx.txt # -n 作用是显示行数
grep -r 'internal_crop_0810.oas' ./ # 以递归的方式查找当前路径及子目录文件里指定的字符串
grep -i 'end process' test.py # -i 是忽略查找字符的大小写1.9.2 文件查找
find 路径 形式 内容。find 默认递归指定目录。
形式:
- -name 按名字
- -iname 按名字,不区分大小写
- -size 按大小
find ./temp -name test.sh
find ./temp -name '*.sh'
find ./temp -name '[A-Z]*'
find ./temp -size 2M #查找大小为 2M 的文件
find ./temp -size -2M #查找小于 2M 的文件
find ./temp -size +2M #查找大于 2M 的文件
find ./temp -size +2M -size -4M #查找大于 2M,小于 4M 的文件
find ./ -not -name 'plot*' #取反,不包含遇到权限问题,一律在最前面加sudo。
1.9.3 查找删除
find / -name *redis* -exec rm -rf {} \; #查找根目录下所有包含 redis 的文件并删除
find /dir/path/* -type f -mtime +2 -exec rm {} \; #-type f 表示只删文件, -mtime +2 筛选修改日期是 2 天前的-type,-mtime 都是 find 的 options,
find --help可以查看更多用法2.8 章节也有介绍,支持删除大量文件
1.10 移动与拷贝
mv 1.txt 1_1.txt #重命名 1.txt 为 1_1.txt
mv 1.txt /laowang #移动文件 1.txt 到 laowang 文件夹里
cp 1.txt /laowang #复制文件 1.txt 到 laowang 文件夹里若被拒绝,则加 -r 即可解决。
1.11 压缩与解压
tar [参数] 打包文件名 需要打包的文件

打包与解包:
# 将所有 py 文件打包成 test.tar
tar -cvf test.tar *.py
#对 test.tar 进行解包
tar -xvf test.tar注意以上命令只是打包,并没有压缩。
压缩与解压:
# 将所有 py 文件压缩成 test.tar.gz, 压缩比很可观
tar -zcvf test.tar.gz *.py
#解包
tar -zxvf test.tar.gz
#将所有 py 文件压缩成 test.tar.bz2, 压缩比上面小
tar -jcvf test.tar.bz2 *.py
#解包
tar -jxvf test.tar.bz2
tar -zxvf test.tar.gz -C laowang/ #解压到指定路径其他压缩方式:
zip zzz.zip *.py
unzip -d laowang/ zzz.zip 1.12 which/who
which ls #输出 ls 命令的路径
#输出如下:
/bin/ls
who #显示当前的用户登陆信息
whoami #显示当前的账户名(用户名)1.13 编辑器 vim
使用 vi 或者 vim 命令即可编辑
vi text.py #创建 1.py 并打开 vim 编辑器,默认进入命令模式命令与模式转换:

由命令模式进入编辑模式时:a 命令在光标后面插入编辑,A 命令在行末编辑,O 命令在光标上一行插入,o 命令在光标下一行编辑……。
退出保存 :末行模式下按wq 键,一个 x 键也可以。也可以shift+zz
命令模式下命令:
- yy:复制光标所在的行
- 4yy:复制光标所在的行开始往下的一共 4 行
- dd:剪切光标所在的行
- 2dd:剪切光标所在的行开始往下的一共 4 行
- D:剪切光标所在的位置一直到行末
- d0:剪切光标所在的位置一直到行首
- u:撤销
- ctrl+r:反撤销
- x:删除光标定位的那个字符
- X:删除光标前的那个字符
- p:粘贴
- 控制光标
- h 左,j 下,k 上,l 右
- M 定位屏幕中间,H 定位屏幕最上方,L 定位屏幕最下方
- ctrl+f 向下翻一页,ctrl+b 向上翻一页;ctrl+d 向下翻半页,ctrl+u 向上翻半页
- 回到第 20 行:20+G 键;回到整个代码最后一行:G 键;回第一行:gg 键
- w 向后跳一个单词长度,b 向前跳一个单词长度
- shift+a:快速到行尾,并进入插入模式
- v、V:选择多行
>>:向右缩进<<:向左缩进.:重复上次命令
- 替换
- r:替换当前字符
- R:替换当前行光标及其后的字符
- 整体替换:末行模式下输入
%s/ 需替换的内容 / 替换后的内容 /g - 替换部分:末行模式下输入
1,10s/ 需替换的内容 / 替换后的内容 /g替换 1-10 行的。
- 搜索
- /:进入搜索模式,输入搜索词,之后按 enter
- n:下一个
- N:上一个
- 取消高亮显示
:noh
- 高频率命令(十分有用)
[[:跳到光标所在的程序块(函数)的开头;]]:跳到光标所在的下一个程序块(函数)的开头;gD:跳转到光标所在的局部变量的定义处'':跳转到光标上次停靠的地方, 是两个’,而不是一个”。与上面一个命令配合用>>:增加光标所在行的缩进<<:较少光标所在行的缩进ctrl+p:编辑模式下的代码补全ctrl+z:vim 模式下回到终端(vim 后台挂起),终端下输入fg回车,重新回到 vim 界面。- 分屏
:sp:上下分屏,ctrl+w 切换屏:vs:左右分屏,ctrl+ww 切换屏:new新建空白分屏,:w ./new.pyvim -o file1 file2:以水平分屏的形式打开多个文件,-O 是垂直分屏
2、补充命令
2.1 时间日期相关
cal #显示当前日历
cal -y 2018 #显示 2018 年日历date #显示当前时间
data "+%Y-%m-%d" #显示年,月,日
data > xx.txt #把显示的日期写到 xx.txt 文件里2.2 查看进程
ps [选项]
ps -aux #查看当前时刻的所有进程消息
ps -uf
top #查看进程消息, 持续动态存在
htop
kill [PID] #以指定 PID 方式终止对应的进程
kill [PID] -9 #强制杀死进程2.3 关闭重启
reboot #重启
shutdown -h now #立刻关机
shutdown -r now #立刻关机并通知其他用户
2.4 磁盘挂载
2.4.1 文件系统整体磁盘使用情况
df:查看 文件系统整体磁盘使用情况。注意不是文件目录
| 命令 | 说明 |
|---|---|
df -h |
最常用! 以人类可读格式(KB/MB/GB)显示所有挂载分区的空间使用情况 |
df -h / |
只查看根分区 / 的使用情况 |
df -h /home |
查看 /home 所在分区的使用情况 |
df -i |
显示 inode 使用情况(排查“磁盘未满但无法创建文件”问题) |
df --output=source,size,used,avail,pcent,target |
自定义输出列(更清晰) |
示例:
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 50G 20G 30G 40% /
/dev/sda1 976M 150M 827M 16% /boot
tmpfs 1.9G 0 1.9G 0% /run/user/10002.4.2 查看目录或文件的磁盘占用
du = disk usage,统计指定目录 / 文件实际占用的磁盘空间。
| 命令 | 说明 |
|---|---|
du -sh |
最常用! 显示当前目录总大小(-s= 汇总,-h= 易读) |
du -sh /var/log |
查看 /var/log 目录总大小 |
du -h --max-depth=1 |
显示当前目录下 各子目录 / 文件 的大小(深度为 1) |
du -sh * |
列出当前目录下每个文件 / 子目录的大小(不包括隐藏文件) |
du -ah --max-depth=1 |
包含 所有文件(-a),而不仅是目录 |
du -sh .[^.]* * 2>/dev/null |
同时显示 隐藏文件和普通文件(谨慎使用) |
示例:
[root@localhost ~]# du -sh *
4.0K anaconda-ks.cfg
1.2G data/
256M logs/
8.0K README.txt2.4.3 常用场景
系统提示“磁盘空间不足”,如何排查?
# 1. 先看哪个分区满了
df -h
# 2. 假设 / 分区满了,进入根目录查大目录
cd /
sudo du -h --max-depth=1 2>/dev/null | sort -hr | head -10
# 3. 逐步深入(如 /var 很大)
cd /var
sudo du -h --max-depth=1 2>/dev/null | sort -hr2.5 查看或配置网卡
ifconfig #查看网卡 ip 信息
ping 网址 #测试通信
ping ip #测试通信2.6 用户权限管理
2.6.1 用户
- 常见用户与设置密码
sudo useradd 账户名 -m #创建一个账户并创建一个 home 目录(-m 的作用)
sudo passwd 账户名 #设置密码- 切换用户
su 账户名 #切换账户
su - 账户名 #切换账户的同时切换到它的家目录
exit #登出账户- 远程登录
ssh python@ip #远程登陆 ip 地址的 python 账户- 删除账户
userdel 账户名 #删除账户
userdel -r 账户名 #删除账户并删除该账户的主目录,谨慎操作- 切换到超级管理员
sudo -s #切换到超级管理员2.6.1 用户组
groupadd 组名 #创建用户组
groupdel 组名 #删除用户组
groups #查看当前用户的组
cat /etc/group #查看有哪些组
groupmod +2 次 tab 键 #查看有哪些组切换文件的用户组
chgrp YY_Group 1.py #切换 1.py 到 YY_Group 用户组
chown user_xx 1.py #切换 1.py 到 user_xx 用户2.6.3 权限
2.6.3.1 用户权限
给普通用户加 sudo 权限:
sudo usermod -a -G adm 用户名
sudo usermod -a -G sudo 用户名2.6.3.2 文件权限
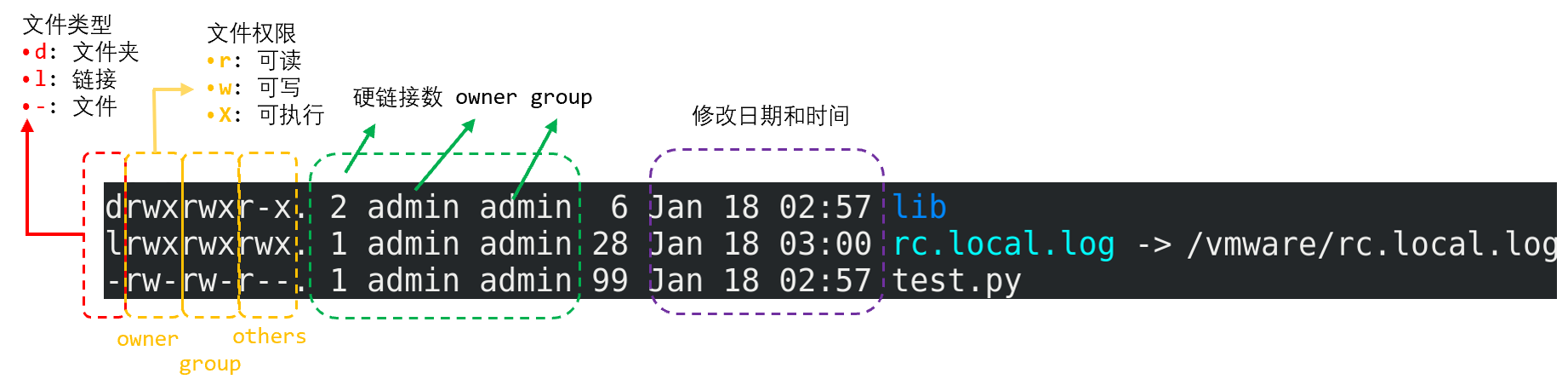
chmod 751 test.py #修改文件的权限
chmod +x test.py #给 ower 加执行(x)的权限
chmod -R 751 ./lib #给 lib 文件夹及其子文件都赋予 751 的权限数字 751 代表:
首位 7 代表 Owner 的权限,由 4+2+1 加和而来,4 代表
r(可读),2 代表w(可写),1 代表x(可执行)第二位 5 代表 group 的权限,由 4+1 加和而来,代表可读可执行
第三位 1 代表 others 的权限,代表仅可执行
chmod -R 751 ./lib等同于chmod -R u=rwx,g=r-x,o=--x ./lib
- -R 参数以递归方式对子目录和文件进行修改。
- u, g, o 分别代表 user(owner),group, others
2.7 下载源
下载源就相当于 软件库,使用安装命令,默认就会按照下载源文件里面的链接地址进行查找,下载,安装软件。
不同系统版本的下载源配置,和安装命令有所不同。
Linux 发行版主要分为几大派系,最主流的是:
Debian/Ubuntu 系(适合桌面和通用服务器
Red Hat/CentOS/Rocky 系(适合企业级服务器)
Arch 系(适合极客和开发者)。
主流 Linux 发行版 包管理器 & 换源 / 安装 速查表:
| 发行版 | 包管理器 | 源配置文件 / 目录 | 核心安装命令 | 更新软件源缓存命令 |
|---|---|---|---|---|
| Ubuntu / Debian | apt | /etc/apt/sources.list /etc/apt/sources.list.d/ |
sudo apt install < 软件名 > | sudo apt update |
| CentOS / RHEL / Rocky | yum / dnf | /etc/yum.repos.d/ | sudo yum install < 软件名 > | sudo yum makecache |
| Fedora | dnf | /etc/yum.repos.d/ | sudo dnf install < 软件名 > | sudo dnf makecache |
| Arch Linux | pacman | /etc/pacman.d/mirrorlist | sudo pacman -S < 软件名 > | sudo pacman -Sy |
| openSUSE | zypper | /etc/zypp/repos.d/ | sudo zypper install < 软件名 > | sudo zypper refresh |
通常情况下,默认下载源为官方链接,我们可能遇到网络问题没法下载,那么建议使用国内的镜像源:
- 首先根据你是用的 linux 发行版本,找到下载源配置文件目录,备份原文件,命名后缀可加.bak
- 更改官方网址为阿里,腾讯云,中科大,清华源等。注意下面只是给的上层网址,具体系统版本需要进子目录,给到精确的地址
- 更新软件源缓存命令
详解 wget, apt, yum,rpm 区别
(1)wget 是一个下载命令,名字是 World Wide Web 与 get 的结合
如果要下载一个软件,可以直接 wget+ 下载地址,通过 HTTP,HTTPS,FTP 三个最常见的 TCP/IP 协议下载。
(2)rpm 是 redhat 公司的一种软件包管理机制,直接通过 rpm 命令进行安装删除等操作,最大的优点是自己内部自动处理了各种软件包可能的依赖关系。
rpm -ivh xx.rpm #安装 xx.rpm 包
rpm -e package #删除包(3)yum 全称为 Yellow dog Updater, Modified, 基于 RPM 包管理,能够从指定的服务器自动下载 RPM 包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包。
是 redhat、centos 下的一个软件安装方式,基于 Linux。
yum install package
yum remove package
yum update(4)apt-get/apt 是 ubuntu 下的一个软件安装方式,它是基于 debain。
2.8 其他常见组合命令
2.8.1 查找删除
按照文件创建日期删除
find ./dir -type f -mtime +2 -exec rm {} \; # 不适合大量删除,会报错 find ./dir -type f -mtime +2 -exec rm {} + # 适合大量删除- -type f:指定对象为文件,不含目录
- -mtime +2 筛选修改日期是 2 天前的
{}是find的占位符,代表当前找到的文件路径。\;是-exec语句的结束标志(必须转义分号)+是另一种结束标志,表示“批量传参”。
按照文件类型 / 名字删除
find ./dir -name "*.log" -exec rm {} +大量文件删除,避免删除报错
find ./dir -type f -name "filename" | xargs rm find ./dir -type f -name "filename" -print0 | xargs -0 rm当你处理大量文件时,使用
xargs可能比-exec更高效,因为它会将找到的文件批量传递给rm命令对于包含空格或其他特殊字符的文件名,最好使用
-print0和-0参数以避免错误
在
find命令中,-exec rm {} \;和-exec rm {} +都用于对查找到的文件执行rm删除操作,但它们在 执行方式 和效率 上有重要区别:-exec rm {} \;- 含义:对每一个匹配到的文件,单独执行一次
rm命令。如果find找到 100 个文件,就会调用rm100 次。 - 缺点:效率较低(尤其在文件数量大时),因为每次都要 fork 一个新进程。
-exec rm {} +- 含义:将多个匹配到的文件作为参数一次性传递给
rm。find会尽可能多地把文件名拼接成一个命令行(不超过系统ARG_MAX限制)。只需调用rm少数几次(甚至一次)即可删除所有文件。 - 优点:高效,减少进程创建开销。
- 缺点:某些非常老的系统可能不支持(但现代系统基本都支持)。
- 含义:对每一个匹配到的文件,单独执行一次
3、Linux 文本处理
3.1 Sed 命令
sed 是一种流编辑器,是一种面向行的文本处理工具,用于对输入流(文件或管道)进行基本的文本转换,比如查找、替换、删除、插入等操作。它常用于 shell 脚本中进行自动化文本处理。
可以配合正则使用
每次从文本读入一行,在“保持空间”和“模式空间”进行修改,然后再读入下一行。
3.1.1 语法格式
命令格式:
sed [options] 'command/script' file(s) #注意这里的引号,一定要加options
e: 添加多个命令-n: 只打印经过sed处理的行(配合p命令使用)。默认输出处理后的全部内容-i: 直接修改源文件-f script-file: 从文件中读取 sed 命令
‘command/scripts’
- 替换功能
[address]s# 旧字符串 #新字符串#rule按字符串替换[address]c\ 新文本按行替换
- 插入功能
[address]a(或 i)\ 新文本按行附加文本,a 指定后加一行新文本,i 指定前加一行新文本[address]r filename插入文件内容,将 filename 内容插入 sed 的操作文件[address]w filename插入文件内容,将 sed 的操作文件内容插入到 filename 里面
- 删除功能
[address]d删除文本中的特定行
- 搜索功能
[address]p搜索符号条件的行,并输出该行的内容
- 按行输出
[address]q输出指定行并退出
- 替换功能
address:指定需要文本处理的行或者标记
- 单个数字:比如 2,指定第 2 行
- 数字逗号数字:比如 1,10,指定第 1-10 行
- 数字逗号 $:比如 2,$,指定第 2- 最后一行
- /pattern/:指定 pattern 所在的行
通配符 :
^行开始符;$行结尾符。
3.1.2 替换 s
sed -i s/ 旧字符串 / 新字符串 /rule file #按照 rule 规则,替换 " 旧字符串 " 为 " 新字符串 "-i直接修改原文件 file; s代表替换 ; /是分隔符,也可用 # 符号
rule表示替换的规则:
- 若不写,只匹配替换第一个 old_text
- 若为
g,表示全局替换 - 若为
i,忽略大小写关键字替换 - 若为
m,m 是数字,如果 old_text 的出现次数小于 m,那么替换不生效。 - 若为
p,打印匹配到的字符所在的行,此标记通常与 -n 选项一起使用。
举例:
文本替换
sed -i '2,6s#@hello@#Hi#g' filename #将 filename 里面的 2-6 行的 hello 替换成 Hi sed -i '#MiKe#s#hello#Hi#g' filename #将 filename 里面的 MiKe 所在的行的 hello 替换成 Hi路径替换:
sed -i 's#./prep#/home/prep#g' ./*/*.log #将路径 "./prep" 替换成 "/home/prep" sed -n 's#./prep#/home/prep#p' filename #替换操作,并且打印替换过的行批量替换
sed -i '{ s/sall/sale/ s/man/woman/ }' data.txt替换整行
sed -i '3c\ add new line' data.txt #第三行替换成:add new line sed -i '/num3/c\ add new line' data.txt #将 num3 所在的行全部替换为:add new line
3.1.3 插入 a/i
### 插入一行
sed -i '3a\this is a nice day' data.txt #第 3 行后面加一行文字:this is a nice day
sed -i '3i\this is a nice day' data.txt #第 3 行前面加一行文字:this is a nice day
### 插入多行
sed -i '3a\
add one line.\
add two line.' data.txt
### 插入文件
sed -i '1,2w test.txt' data.txt #将 data.txt 的第 1-2 行写入到 test.txt 中
sed -i '3r test.txt' data.txt #将 text.txt 全部插入到 data.txt 的第 3 行的后一行3.1.4 删除 d
sed -i '2,3d' data.txt #删除 2-3 行3.1.5 搜索打印 p
sed -n '/num3/p' data.txt #打印 num3 所在的行3.1.6 按行输出
sed -i '3q' data.txt #输出前 3 行并退出3.1.7 option -f
sed -f sed.sh data.txt #-f 后接一个 shell 脚本文件,这个脚本定义了 command/script3.1.8 option -e
# 利用 -e 可以实现多点编辑
sed -e '3,$d' -e 's/bash/blueshell/' data.txt #删除 3- 最后一行,并且替换 bash 为 blueshell3.2 awk 命令
awk 是一种编程语言,用于在 linux/unix 下对文本和数据进行处理。数据可以来自标准输(stdin)、一个或多个文件,或其它命令的输出。它在命令行中使用,但更多是作为脚本来使用。awk 有很多内建的功能,比如数组、函数等,这是它和 C 语言的相同之处,灵活性是 awk 最大的优势。
3.2.1 语法格式
语法格式:
awk [options] 'scripts' var=value filenameoptions:
- -F fs:指定分隔符(可以是字符串或正则表达式),默认分隔符为空格或制表符
- -f file:从脚本文件中读取 awk 命令
- -v var=value: 赋值变量,将外部变量传递给 awk
‘scripts’:
#'scripts' 基本结构
'BEGIN{ print "start" } pattern{ commands } END{ print "end" }'一个 awk 脚本通常由 BEGIN 语句 + 模式匹配 + END 语句 三部分组成,这三部分都是 可选项。
执行步骤:
- 第一步执行 BEGIN 语句
- 第二步从文件或标准输入读取一行,然后再执行 pattern 语句,逐行扫描文件到文件全部被读取
- 第三步执行 END 语句
举几个简单例子:
- 1 从标准输入(管道)读取

输出为:
welcome
hello
2022-03-06不加 print 参数时默认只打印当前的行
- 2 只用 command 语句
>>> echo|awk '{ a="mgg"; b="mingg"; c="mingongge"; print a" is "b" or "c; }'
mgg is mingg or mingonggeawk 的 print 语句中 双引号 其实就是个 拼接 作用
- 3 pattern{commands},从文件读取匹配
#data.txt
line1 xxxx1
line2 yyyy2
line3 zzzz3
--------------------------
>>> awk '/line2/{print $2}' data.txt
yyyy2下面开始正式介绍 awk 相关例子。
3.2.2 分隔符 -F
awk 默认以空格为分隔符,还可以接受指定的分隔符。
-F ' ':以空格为分隔符,单双引号都可-F#:以#为分隔符,也可-F '#',格式没有那么死板。-F,:以,为分隔符-F '[,]':以左中括号[空格 逗号,右中括号]这多个单字符作为分隔符-F'abc|cde':用 abc 和 cde多个字符串来作为分隔符-v FS='#':设置内部变量,指定输入分隔符#,其中 FS 是输入分隔符的意思-v OFS='#':设置内部变量,指定输出分隔符#,其中 OFS 是输出分隔符的意思
举个简单例子
awk -F '#' '{print $1}' data.txt$1 代表文本行中的第 1 个数据字段。后面会介绍 3.3.3—Awk 的变量。
3.2.3 文件命令读取 -f
awk 允许将脚本命令存储到文件中,然后再在命令行中引用。
awk -f {awk 脚本 } { 文件名 }
awk -f cal.awk log.txt一个 awk 脚本文件的例子:
$ cat cal.awk
#!/bin/awk -f
#运行前
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#运行中
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
#运行后
END {
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}awk 即支持 print,也可 printf。差别可自行百度。
3.3.4 变量赋值 -v
- 接受内部变量
# log.txt
2 this test
3 Are awk
This's a
10 There apple
-------------------------------------------
>>> awk -v a=1 '{print $1,$1+a}' log.txt
2 3
3 4
This's 1
10 11
#上述中 log.txt 文本中的 a 都被赋值了- 接受外部变量
>>> val="aaa"
>>> echo|awk -v v1=$val '{print v1}'
aaaAwk 的变量
# 内置变量
$0 #当前记录
$1~$n #当前记录的第 N 个字段
FS #输入字段分隔符(-F 相同作用)默认空格
RS #输入记录分割符,默认换行符
OFS #输出字段分隔符,默认空格
ORS #输出记录分割符,默认换行符
NF #该行字段个数,就是列数
NR #记录数,就是行号,默认从 1 开始这些都是比较常用的内置变量,其余的自行百度。
3.3.5 匹配规则 pattern
正则表达式作为 pattern
/A/ #去匹配含有 A 的字符 awk '/hello/ { print $0 }' myfile #输出含有 hello 的整行比较表达式作为 pattern
'$NF == "A" #输出最后一个字段为 A 的 awk '$NF == "A" { print $0 }' myfile #输出最后一个字段为 A 的整行常量表达式作为 pattern,或多模式多动作
awk ' 真 { 执行代码 } 假 { 不执行代码 }' awk '1 { print $0 }' myfile #为真,执行输出整行 awk '$NR==1 {print $NF} $NR==3 {print $NF}' myfile空 pattern 是永远匹配为真的
awk '{ print $0 }' myfile #输出所有的整行,模式范围: begpat, endpat
这个模式范围, 是由两个 pattern 组成, 每个 pattern 可以是任意的非特殊类型(可以是正则,比较,常量等 pattern).
awk 'NR==4, /555-3430/ { print $0}' myfile执行方式:匹配输出满足以 begpat 开始到以 endpat 结束中间的所有行,第一轮结束后可以开始下一轮(只满足这个起始和终止条件)。
特殊匹配 BEGIN、END
awk 里的 BEGIN 语句和 END 语句也是一种匹配。
Awk 正则
^ 行首定位符
$ 行尾定位符
. 匹配任意单个字符
* 匹配 0 个或多个前导字符(包括回车)
+ 匹配 1 个或多个前导字符
? 匹配 0 个或 1 个前导字符
[] 匹配指定字符组内的任意一个字符 /^[ab]
[^] 匹配不在指定字符组内的任意一个字符
() 子表达式
| 或者
\ 转义符
~,!~ 匹配或不匹配的条件语句
x{m} x 字符重复 m 次
x{m,} x 字符至少重复 m 次
X{m,n} x 字符至少重复 m 次但不起过 n 次(需指定参数 -posix 或 --re-interval)3.3.6 执行命令{commands}
awk 是一种编程语言,故支持运算,文件操作,输入输出,循环语句,数组,内置函数等操作。
一般高级点的用法我们用不到,这里不做介绍。如有需要,跳转:
shell 编程之 awk 命令详解 - QuincyHu - 博客园 (cnblogs.com)
4. Linux 下配置环境变量
环境变量:使得命令能够在全局使用。而不必切换到其安装目录。
4.1 环境变量的配置方法
linux 在正常启动时,先会启动一系列配置文件,再显示命令行提示符:
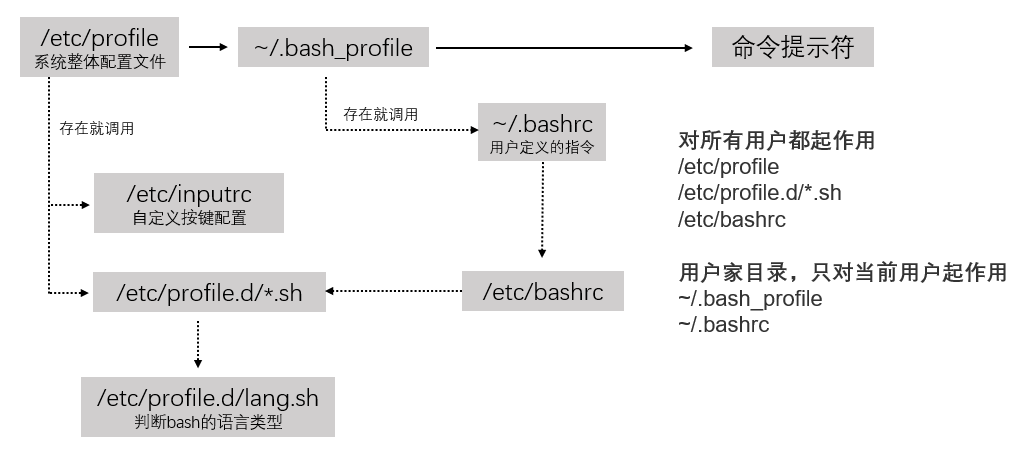
在用户目录下的 ~/.bashrc中配置环境变量:
# vim ~/.bashrc
# 添加以下一行
export PATH=$PATH:/home/uusama/mysql/bin
#或者
export PATH=/home/uusama/mysql/bin:$PATH #(二者表达意思一样)以上的 export PATH=$PATH:/home/uusama/mysql/bin 可以这样理解:
export 是配置环境变量的命令
PATH 是指定命令的搜索路径。类似的 Linux 中还有 9 个环境变量,见 4.2.3。
$PATH 是指 PATH 这个环境变量,$ 符号就是表示 PATH 是个变量,$PATH 代表了 PATH 路径下所有的变量,可能在其他配置文件配置了 PATH=/etc/pangen/bin 等多个路径,$PATH 可将这些一并加载过来。
冒号 : 是分割符的意思,意思是 PATH 环境变量不仅包含了 $PATH 代表的其他路径下的命令,还加上 /home/uusama/mysql/bin,与 win 平台的分号作用类似, 表示并列。
如果只是 export PATH=/home/uusama/mysql/bin 那么 PATH 只会指向 /home/uusama/mysql/bin 这个路径,覆盖了其他的指向。
4.2 扩展
4.2.1 export 命令
配置环境变量当然不只是上面一种方法,还可以直接采用命令的形式:
在命令窗口输入:export PATH=/home/uusama/mysql/bin:$PATH
注意事项:
- 生效时间:立即生效
- 生效期限:当前终端有效,窗口关闭后无效
- 生效范围:仅对当前用户有效
而相对于 vim 命令直接编辑~/.bashrc,就会永久生效:
- 生效时间:使用相同的用户打开新的终端时生效,或者手动
source ~/.bashrc生效 - 生效期限:永久有效
- 生效范围:仅对当前用户有效
4.2.2 查看变量
echo $PATH :显示所有 PATH 环境变量的路径
/home/pangen/bin:/home/pangen/pangen_build_env/bin:/usr/lib64/qt-3.3/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/ibutils/bin:/home/qiangjiang/.local/bin:/home/qiangjiang/binexport 可以查看(显示)Shell 环境变量
[roc@roclinux ~]$ export declare -x CVS_RSH="ssh" declare -x G_BROKEN_FILENAMES="1" declare -x HISTCONTROL="ignoredups" declare -x HISTSIZE="1000" declare -x HOME="/home/roc" declare -x HOSTNAME="roclinux" …………………………env 命令显示所有的环境变量
set 命令显示所有本地定义的 Shell 变量
4.2.3 10 个环境变量
常用的环境变量:
PATH 决定了 shell 将到哪些目录中寻找命令或程序
HOME 当前用户主目录
HISTSIZE 历史记录数
LOGNAME 当前用户的登录名
HOSTNAME 指主机的名称
SHELL 当前用户 Shell 类型
LANGUGE 语言相关的环境变量,多语言可以修改此环境变量
MAIL 当前用户的邮件存放目录
PS1 基本提示符,对于 root 用户是 #,对于普通用户是 $
4.2.4 给命令取别名
在配置文件中,如 ~/.bashrc 或~/.profile中使用 alias 命令可以定义一些命令的别名。
如:
vim ~/.bashrc
#编辑添加
alias rm='rm -irf'这样每次使用 rm 命令时,就代表使用了rm -irf
5、Linux 下运行 python
linux 有好些发行版,ubuntu/centos 版下默认使用 python2.x 版本,这个版本注意不能卸载掉。
建议使用 Anaconda 配置 python 环境。使用 Anaconda 有许多好处,尤其是对于数据科学、机器学习以及需要处理大量数据的 Python 开发者来说。以下是使用 Anaconda 的一些主要优势:
- 环境管理:
- Anaconda 通过
conda命令提供了强大的环境管理功能,使得用户可以轻松创建、管理和切换不同的开发环境。这对于同时处理多个项目或需要不同版本库的情况非常有用。
- Anaconda 通过
- 包管理:
- 包含了超过 7500 个数据科学相关的开源包,可以通过简单的命令进行安装和更新。这大大简化了依赖关系的管理,避免了手动下载和安装各种库的麻烦。
- 跨平台支持:
- 支持 Windows、macOS 和 Linux 操作系统,确保无论在哪种平台上工作,都可以获得一致的体验。
- 预装关键库:
- 自带了许多流行的数据科学库,如 NumPy, pandas, SciPy, Matplotlib, Seaborn, Scikit-learn 等,减少了初始配置时间。
- Jupyter Notebook 集成:
- 预装了 Jupyter Notebook,这是一种非常适合数据分析和机器学习项目的交互式计算环境。它允许你创建和共享包含实时代码、方程式、可视化和叙述文本的文档。
- 企业级特性(Anaconda Distribution vs Anaconda Enterprise):
- 对于企业用户,Anaconda 还提供了额外的企业级解决方案,包括更高级的安全性、团队协作工具以及对大规模部署的支持。
- 社区与支持:
- 拥有一个活跃且不断增长的社区,提供丰富的资源和支持。无论是新手还是有经验的开发者都能从中受益。
- 教育用途:
- 在学术界广泛使用,许多大学课程和在线教程推荐使用 Anaconda 作为教学工具,因为它简化了设置过程,并让学生能够专注于学习而非环境配置。
5.1 安装 Anaconda
安装 Anaconda3 环境,安装路径:Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
Linux 版本可以选择 Anaconda3-2023.03-Linux-x86_64.sh
安装:下载完成后,直接在 Linux 里运行./Anaconda3-2023.03-Linux-x86_64.sh 安装即可
配置环境变量:./anaconda3/bin 到 PATH 里面
cmd 里输入 python,检查 python 是否可以使用。
5.2 改变 python 指向版本
默认情况下,输入 python 还是会进入 python2.x,输入 python3 才会进入 python3.x。
可执行以下命令改变,使得 python 命令指向 python3.x。
ls -l /usr/bin | grep python #查看目前的 python 版本及其指向(链接)
rm /usr/ 链接路径 #删除原有 python 链接
sudo ln -s /usr/bin/python3.7 /usr/bin/python #新建 python 链接至此已经完成了目标。
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net