一、计算机编程语言
1.1 编程语言
编程语言有‘高低’之分,分为:机器语言、汇编语言、高级语言。
机器语言:计算机直接能够接受和应用的语言,由二进制代码组成的 机器指令 的集合。
汇编语言:是一种面向计算机硬件的低级语言,也称 符号语言 ,用助记符代替机器指令的操作码,用地址符号或标号代替指令或操作数的地址。汇编语言写出源程序,在用 汇编编译器 将其编译为机器指令,由计算机最终执行。
高级语言:高级语言是一种指令集的体系,使用一般人易于接受的文字来表示,是高度封装了的编程语言。
1.2 高级语言特性
1.2.1 编译型与解释型语言
高级语言有 C 系列(C、C++,C#),java,python,Go,PHP,VB,JavaScript,Rust,R 等。
按照执行的方式的不同,高级语言可被分为:
- 编译型语言 :源程序的每一条语句都经过 编译器 编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快。
- 如:C、C++
- 解释型语言 :只在执行程序时,才一条一条的由 解释器 解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的。
- 如:java、python
1.2.2 动态语言和静态语言
动态类型语言:在用动态类型的语言编程时,永远也 不用给任何变量指定数据类型 ,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来,即在 运行期间才去做数据类型检查 的语言。比如:Python,Ruby,JavaScript。
静态类型语言:写程序时要 声明所有变量的数据类型 ,它的数据类型是在 编译其间检查的。比如:C/C++,C#、Java 等。
1.2.3 强类型和弱类型语言
强类型定义语言:一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。不支持隐式转换。如:Python,Java,C++ 等。
弱类型定义语言:类型不严格区分,一般是只要大小放得下,就可以转化。支持隐式转换。如:JavaScript、PHP 等。
举例说明:
//python 程序
a=1+'1'
print(a)
// 结果输出:TypeError: unsupported operand type(s) for +: 'int' and 'str'#JavaScript 程序
var a=1+'1'
console.log(a,typeof(a))
# 结果输出:11 string 以上就是强类型语言和弱类型语言的区别。
1.3 Python 与 Java 的执行原理
Python 和 Java 同属于解释型语言,都是先编译成中间状态的字节码,最后一行行解释执行。但是还是有差异的。具体请看下面两张图:
(1)Python 的执行方式

- python 解释器首先会对整个.py 代码进行词法和语法分析,若发现错误,则停止运行抛出错误;若无错误,接下来编译器会将整个.py 代码译为二进制的字节码(放在与 python 代码的同级目录
__pycache__文件夹里),接下来字节码由 PVM 执行,逐行解释 执行字节码,变为机器码,与硬件交互执行。 - 注意:如果代码 A 被执行过,其对应的字节码(.pyc)也存在,下次再执行时,若代码 A 没被修改(以时间戳的一致性判断),则会跳过编译步骤,直接运行其字节码,以提高效率。
(2)Java 的执行方式
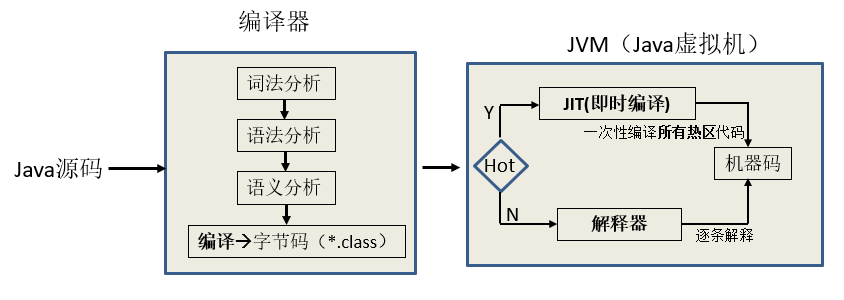
- java 编译器首先会对整个.java 代码进行词法,语法和语义分析,无误后,编译器将整个.java 代码译为二进制的字节码。接下来 JVM 会对字节码进行分析,将所有热点代码交给 JIT 一次性全部编译成机器码,非热点码则逐条解释,逐条执行。
- 注意:“热点代码”有两类:A、被多次调用的函数(方法)。B、被多次执行的循环体。
1.4 Python 解释器
CPython:官方版本的解释器:CPython。这个解释器是用 C 语言开发的,所以叫 CPython。在命令行下运行 python 就是启动 CPython 解释器。CPython 是使用最广且被的 Python 解释器。
IPython:IPython 是基于 CPython 之上的一个交互式解释器,也就是说,IPython 只是在交互方式上有所增强,但是执行 Python 代码的功能和 CPython 是完全一样的。CPython 用 >>> 作为提示符,而 IPython 用 In [序号]: 作为提示符。
PyPy:PyPy 是另一个 Python 解释器,它的目标是执行速度。PyPy 采用 JIT 技术,对 Python 代码进行动态编译(注意不是解释),所以可以显著提高 Python 代码的执行速度。
绝大部分 Python 代码都可以在 PyPy 下运行,但是 PyPy 和 CPython 有一些是不同的,这就导致相同的 Python 代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到 PyPy 下执行,就需要了解 PyPy 和 CPython 的不同点。Jython:Jython 是运行在 Java 平台上的 Python 解释器,可以直接把 Python 代码编译成 Java 字节码执行。
IronPython:IronPython 和 Jython 类似,只不过 IronPython 是运行在微软.Net 平台上的 Python 解释器,可以直接把 Python 代码编译成.Net 的字节码。
在这些 Python 解释器中,使用广泛的是 CPython。
1.5 GIL 锁
我们常说 Python 的执行效率比较慢,没法进行多线程任务,其实这不是 Python 的特性,而是其解释器 CPython 带来的。
CPython(Python 解释器)限制了同一时间内,一个进程里只能有一个线程运行。它阻止了 多个线程同时执行 Python 字节码,这就是 GIL 锁(全局解释器锁)。
Python 最初的设计理念在于,为了解决多线程之间数据完整性和状态同步的问题,设计为在任意时刻只有一个线程在解释器中运行。而当执行多线程程序时,由 GIL 来控制同一时刻只有一个线程能够运行。即 Python 中的多线程是表面多线程,也可以理解为‘假’多线程,不是真正的多线程。
为什么要这样做呢?举个例子,比如用 python 计算:n=n+1。这个操作被分成了四步:
- 加载全局变量 n
- 加载常数 1
- 进行二进制加法运算
- 将运算结果存入变量 n
以上的过程是非原子操作的,根据前面的线程释放 GIL 锁原则,线程 a 执行这四步的过程中,有可能会让出 GIL。如果这样,n=n+1 的运算过程就被打乱了。
这就是为什么我们说 GIL 是粗粒度的,它只保证了一定程度的安全。如果要做到线程的绝对安全,是不是所有的非 IO 操作,我们都需要自己再加一把锁呢?答案是否定的。在 python 中,有些操作是是原子级的,它本身就是一个字节码,GIL 无法在执行过程中释放。对于这种原子级的方法操作,我们无需担心它的安全。比如 sort 方法,[1,4,2].sort(),翻译成字节码就是 CALL METHOD 0。只有一行,无法再分,所以它是线程安全的。
同一时刻只有一个线程能够运行,那么是怎么执行多线程程序的呢?其实原理很简单:解释器的 分时复用 。即多个线程的代码, 轮流 被解释器 执行 ,只不过切换的很频繁很快,给人一种多线程“同时”在执行的错觉。聊的学术化一点,其实就是“ 并发”。
“并发”和“并行”:
- 并发:不同的代码块交替执行
- 并行:不同的代码块同时执行
GIL 锁最终是保证 Python 解释器中原子操作的线程安全。
GIL 是怎么起作用的:
- 由于 GIL 的机制,单核 CPU 在同一时刻只有一个线程在运行,当线程遇到 IO(读写)操作或 Timer Tick 到期,释放 GIL 锁。其他的两个线程去竞争这把锁,得到锁之后,才开始运行。
- 线程释放 GIL 锁有两种情况,一是遇到 IO 操作,二是 Time Tick 到期(执行完 100 个字节码指令或者 15ms)。IO 操作很好理解,比如发出一个 http 请求,等待响应。而 Time Tick 规定了线程的最长执行时间,超过时间后自动释放 GIL 锁。
在多核 CPU 下,由于 GIL 锁的全局特性,无法发挥多核的特性,GIL 锁会使得多线程任务的效率大大降低。线程 1(Thread1)在 CPU1 上运行,线程 2(Thread2)在 CPU2 上运行。GIL 是全局的,CPU2 上的 Thread2 需要等待 CPU1 上的 Thread1 让出 GIL 锁,才有可能执行。如果在多次竞争中,Thread1 都胜出,Thread2 没有得到 GIL 锁,意味着 CPU2 一直是闲置的,无法发挥多核的优势。为了避免同一线程霸占 CPU,在 python3.x 中,线程会自动的调整自己的优先级,使得多线程任务执行效率更高。
GIL 的优缺点:
GIL 的优点是显而易见的,GIL 可以保证我们在多线程编程时,无需考虑多线程之间数据完整性和状态同步的问题。
GIL 缺点是:我们的多线程程序执行起来是“并发”,而不是“并行”。因此执行效率会很低,会不如单线程的执行效率。
原子操作:
- 原子操作就是不会因为进程并发或者线程并发而导致被中断的操作。原子操作 的特点就是 要么一次全部执行,要么全不执行。不存在执行了一半而被中断的情况。
最初是为了利用多核,Python 开始支持多线程。而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。后来发现这种‘加锁’是低效的。但 当大家试图去拆分和去除 GIL 的时候,发现大量库代码开发者已经重度依赖 GIL 而非常难以去除了。
在 Python 编程中,如果想利用计算机的多核提高程序执行效率,用多进程代替多线程。
使用多进程的好处:完全并行,无 GIL 的限制,可充分利用多 cpu 多核的环境。
虽说一般使用多进程对电脑系统资源占用比较多,但是在类 unix 系统中,创建线程的开销并不比进程小,因此在并发操作时,多线程的效率还是受到了很大制约的。所以后来人们发现通过 yield 来中断代码片段的执行,同时交出了 cpu 的使用权,于是协程的概念产生了。
1.6 Python 内存管理与垃圾回收机制
Python 程序在运行时,需要在内存中开辟出一块空间,用于存放运行时产生的临时变量,计算完成后,再将结果输出到永久性存储器中。但是当数据量过大,或者内存空间管理不善,就很容易出现内存溢出的情况,程序可能会被操作系统终止。
而对于服务器这种用于永不中断的系统来说,内存管理就显得更为重要了,不然很容易引发内存泄漏。
那么对于不会再用到的内存空间,Python 主要是通过三种机制来管理的。
以引用计数为主,分代回收为辅。
(1)引用计数
引用计数法的原理是每个对象维护一个ob_ref,用来记录当前对象被引用的次数,也就是来追踪到底有多少引用指向了这个对象。当引用计数为 0 时,该内存将会被 Python 虚拟机销毁。
但发生以下几种情况时,引用计数 +1:
- 对象被创建 / 引用,如
a=1,b=a,此时 a 的引用计数为 2。 - 对象被传参到函数中,如
def funX(a):,此时 a 的引用计数再加 1。 - 对象作为元素,存储在容器中,如
L=[a,'name',1,'23'],此时 a 的引用计数再加 1。
发生以下几种情况时,引用计数 -1:
- 对象的别名被显式销毁,如
del a。 - 对象的别名被赋予新的对象,如
a=24 - 对象离开它的作用域,例如 func 函数执行完毕时,函数里面的局部变量的引用计数器就会减一(但是全局变量不会)
- 将该对象从容器中删除时,或者容器被销毁时。
引用计数的优点:
- 高效
- 实时性
- 对象有确定的生命周期
- 易于实现
引用计数的缺点:
- 维护引用计数消耗资源,维护引用计数的次数和引用赋值成正比
- 无法解决循环引用的问题。A 和 B 相互引用,而再没有外部引用 A 与 B 中的任何一个,它们的引用计数都为 1,但显然应该被回收。
为了解决这两个致命缺点,Python 又引入了以下两种 GC 机制:标记 - 清除和分代回收。
(2)标记清除
【标记清除(Mark—Sweep)】算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。主要解决的是循环引用的问题。
它分为两个阶段:标记活动对象——回收非活动对象。
如何判断非活动对象:
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。
下面举个例子:
把小黑圈视为全局变量,也就是把它作为 root object,从小黑圈出发,对象 1 可直达,那么它将被标记,对象 2、3 可间接到达也会被标记,而 4 和 5 不可达。那么 1、2、3 就是活动对象,4 和 5 是非活动对象会被 GC 回收。

标记清除算法作为 Python 的辅助垃圾收集技术主要处理的是一些 容器对象。比如:列表,字典,集合等,而字符串、数值对象是不可能造成循环引用问题。
其实,Python 使用的是一种不同的链表来持续追踪活跃的对象。而不将其称之为“活跃列表”,Python 的内部 C 代码将其称为零代 (Generation Zero)。每次当 你创建一个对象或其他什么值的时候,Python 会将其加入零代链表。
Python 会循环遍历零代列表上的每个对象,检查列表中每个互相引用的对象,根据规则减掉其引用计数。
通过识别内部引用,Python 能够减少许多零代链表对象的引用计数。
而零代链表中剩下的活跃的对象则被移动到一个新的链表:一代链表。
接下来介绍分代回收机制。
(3)分代回收
Python 中, 引入了分代收集,总共三个”代”。Python 中,一个代就是一个链表,,所有属于同一”代”的内存块都链接在同一个链表中。
Python 程序运行时,会自动分配一块内存,随着程序的运行,变量的增多,一旦超过设定的阈值,就会在零代链表中触发垃圾回收机制,有效引用计数为 0 的,执行回收,有效引用计数大于 0 的,便会依次从上一代挪到下一代。而每一代启动自动垃圾回收的阈值,则是可以单独指定的。当垃圾回收器中新增对象减去删除对象达到相应的阈值时,就会对这一代对象启动垃圾回收。
你的代码所长期使用的对象,那些你的代码持续访问的活跃对象,会从零代链表转移到一代再转移到二代。
总的来说:分代回收是一种以空间换时间的操作方式,Python 将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python 将内存分为了 3“代”,分别为年轻代(第 0 代)、中年代(第 1 代)、老年代(第 2 代),他们对应的是 3 个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python 垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为 Python 的辅助垃圾收集技术处理那些容器对象。
欢迎各位看官及技术大佬前来交流指导呀,可以邮件至 jqiange@yeah.net